 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Local Tasks and Deep Convolutional Networks
Paper and Code
Jun 29, 2020
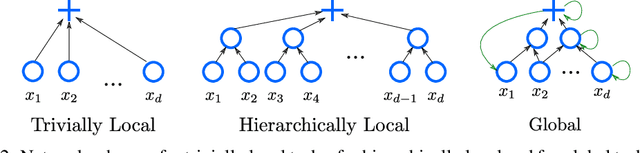
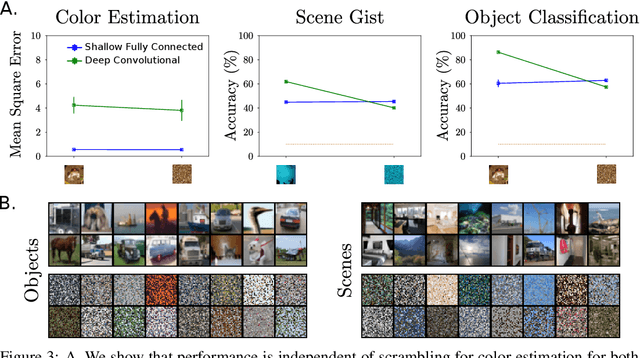
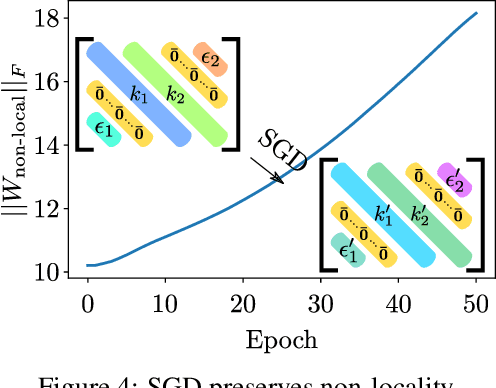
The main success stories of deep learning, starting with ImageNet, depend on convolutional networks, which on certain tasks perform significantly better than traditional shallow classifiers, such as support vector machines. Is there something special about deep convolutional networks that other learning machines do not possess? Recent results in approximation theory have shown that there is an exponential advantage of deep convolutional-like networks in approximating functions with hierarchical locality in their compositional structure. These mathematical results, however, do not say which tasks are expected to have input-output functions with hierarchical locality. Among all the possible hierarchically local tasks in vision, text and speech we explore a few of them experimentally by studying how they are affected by disrupting locality in the input images. We also discuss a taxonomy of tasks ranging from local, to hierarchically local, to global and make predictions about the type of networks required to perform efficiently on these different types of tasks.