 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Context Learning: Studying the Optimization Primitives of Context Space
Apr 03, 2026Generally capable agents must learn from experience in ways that generalize across tasks and environments. The fundamental problems of learning, including credit assignment, overfitting, forgetting, local optima, and high-variance learning signals, persist whether the learned object lies in parameter space or context space. While these challenges are well understood in classical machine learning optimization, they remain underexplored in context space, leading current methods to be fragmented and ad hoc. We present Reflective Context Learning (RCL), a unified framework for agents that learn through repeated interaction, reflection on behavior and failure modes, and iterative updates to context. In RCL, reflection converts trajectories and current context into a directional update signal analogous to gradients, while mutation applies that signal to improve future behavior in context space. We recast recent context-optimization approaches as instances of this shared learning problem and systematically extend them with classical optimization primitives, including batching, improved credit-assignment signal, auxiliary losses, failure replay, and grouped rollouts for variance reduction. On AppWorld, BrowseComp+, and RewardBench2, these primitives improve over strong baselines, with their relative importance shifting across task regimes. We further analyze robustness to initialization, the effects of batch size, sampling and curriculum strategy, optimizer-state variants, and the impact of allocating stronger or weaker models to different optimization components. Our results suggest that learning through context updates should be treated not as a set of isolated algorithms, but as an optimization problem whose mechanisms can be studied systematically and improved through transferable principles.
LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
Dec 17, 2024As language models become integral to critical workflows, assessing their behavior remains a fundamental challenge -- human evaluation is costly and noisy, while automated metrics provide only coarse, difficult-to-interpret signals. We introduce natural language unit tests, a paradigm that decomposes response quality into explicit, testable criteria, along with a unified scoring model, LMUnit, which combines multi-objective training across preferences, direct ratings, and natural language rationales. Through controlled human studies, we show this paradigm significantly improves inter-annotator agreement and enables more effective LLM development workflows. LMUnit achieves state-of-the-art performance on evaluation benchmarks (FLASK, BigGenBench) and competitive results on RewardBench. These results validate both our proposed paradigm and scoring model, suggesting a promising path forward for language model evaluation and development.
Leveraging Diffusion Perturbations for Measuring Fairness in Computer Vision
Nov 25, 2023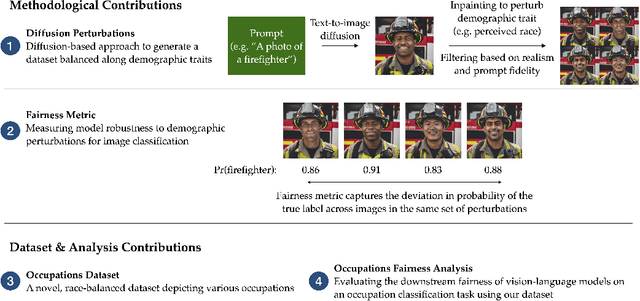
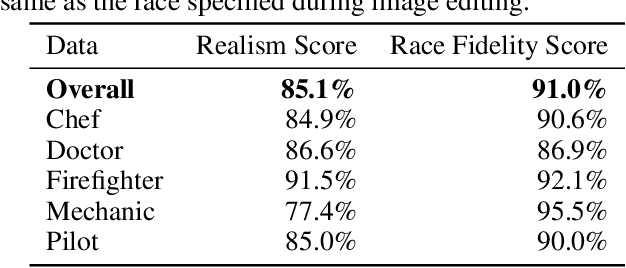


Computer vision models have been known to encode harmful biases, leading to the potentially unfair treatment of historically marginalized groups, such as people of color. However, there remains a lack of datasets balanced along demographic traits that can be used to evaluate the downstream fairness of these models. In this work, we demonstrate that diffusion models can be leveraged to create such a dataset. We first use a diffusion model to generate a large set of images depicting various occupations. Subsequently, each image is edited using inpainting to generate multiple variants, where each variant refers to a different perceived race. Using this dataset, we benchmark several vision-language models on a multi-class occupation classification task. We find that images generated with non-Caucasian labels have a significantly higher occupation misclassification rate than images generated with Caucasian labels, and that several misclassifications are suggestive of racial biases. We measure a model's downstream fairness by computing the standard deviation in the probability of predicting the true occupation label across the different perceived identity groups. Using this fairness metric, we find significant disparities between the evaluated vision-and-language models. We hope that our work demonstrates the potential value of diffusion methods for fairness evaluations.
BI-LAVA: Biocuration with Hierarchical Image Labeling through Active Learning and Visual Analysis
Aug 15, 2023



In the biomedical domain, taxonomies organize the acquisition modalities of scientific images in hierarchical structures. Such taxonomies leverage large sets of correct image labels and provide essential information about the importance of a scientific publication, which could then be used in biocuration tasks. However, the hierarchical nature of the labels, the overhead of processing images, the absence or incompleteness of labeled data, and the expertise required to label this type of data impede the creation of useful datasets for biocuration. From a multi-year collaboration with biocurators and text-mining researchers, we derive an iterative visual analytics and active learning strategy to address these challenges. We implement this strategy in a system called BI-LAVA Biocuration with Hierarchical Image Labeling through Active Learning and Visual Analysis. BI-LAVA leverages a small set of image labels, a hierarchical set of image classifiers, and active learning to help model builders deal with incomplete ground-truth labels, target a hierarchical taxonomy of image modalities, and classify a large pool of unlabeled images. BI-LAVA's front end uses custom encodings to represent data distributions, taxonomies, image projections, and neighborhoods of image thumbnails, which help model builders explore an unfamiliar image dataset and taxonomy and correct and generate labels. An evaluation with machine learning practitioners shows that our mixed human-machine approach successfully supports domain experts in understanding the characteristics of classes within the taxonomy, as well as validating and improving data quality in labeled and unlabeled collections.
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Jun 28, 2023



We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
Joint rotational invariance and adversarial training of a dual-stream Transformer yields state of the art Brain-Score for Area V4
Mar 08, 2022


Modern high-scoring models of vision in the brain score competition do not stem from Vision Transformers. However, in this short paper, we provide evidence against the unexpected trend of Vision Transformers (ViT) being not perceptually aligned with human visual representations by showing how a dual-stream Transformer, a CrossViT$~\textit{a la}$ Chen et al. (2021), under a joint rotationally-invariant and adversarial optimization procedure yields 2nd place in the aggregate Brain-Score 2022 competition averaged across all visual categories, and currently (March 1st, 2022) holds the 1st place for the highest explainable variance of area V4. In addition, our current Transformer-based model also achieves greater explainable variance for areas V4, IT and Behaviour than a biologically-inspired CNN (ResNet50) that integrates a frontal V1-like computation module(Dapello et al.,2020). Our team was also the only entry in the top-5 that shows a positive rank correlation between explained variance per area and depth in the visual hierarchy. Against our initial expectations, these results provide tentative support for an $\textit{"All roads lead to Rome"}$ argument enforced via a joint optimization rule even for non biologically-motivated models of vision such as Vision Transformers.