 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Diffusion Perturbations for Measuring Fairness in Computer Vision
Nov 25, 2023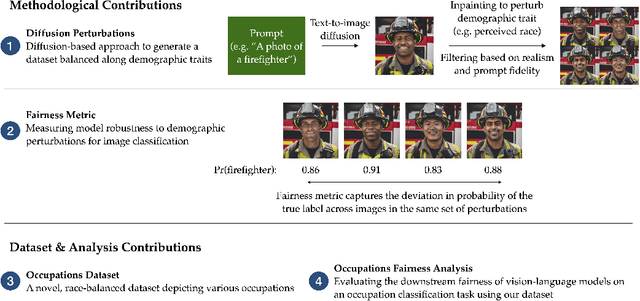
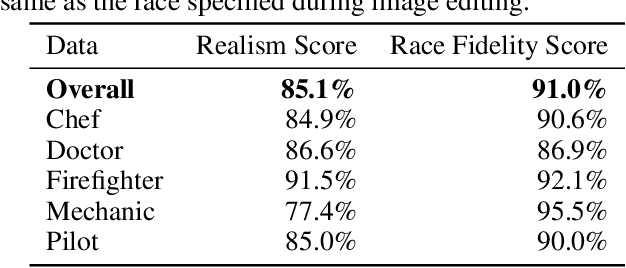


Computer vision models have been known to encode harmful biases, leading to the potentially unfair treatment of historically marginalized groups, such as people of color. However, there remains a lack of datasets balanced along demographic traits that can be used to evaluate the downstream fairness of these models. In this work, we demonstrate that diffusion models can be leveraged to create such a dataset. We first use a diffusion model to generate a large set of images depicting various occupations. Subsequently, each image is edited using inpainting to generate multiple variants, where each variant refers to a different perceived race. Using this dataset, we benchmark several vision-language models on a multi-class occupation classification task. We find that images generated with non-Caucasian labels have a significantly higher occupation misclassification rate than images generated with Caucasian labels, and that several misclassifications are suggestive of racial biases. We measure a model's downstream fairness by computing the standard deviation in the probability of predicting the true occupation label across the different perceived identity groups. Using this fairness metric, we find significant disparities between the evaluated vision-and-language models. We hope that our work demonstrates the potential value of diffusion methods for fairness evaluations.
Synthetic Data for Semantic Image Segmentation of Imagery of Unmanned Spacecraft
Nov 22, 2022



Images of spacecraft photographed from other spacecraft operating in outer space are difficult to come by, especially at a scale typically required for deep learning tasks. Semantic image segmentation, object detection and localization, and pose estimation are well researched areas with powerful results for many applications, and would be very useful in autonomous spacecraft operation and rendezvous. However, recent studies show that these strong results in broad and common domains may generalize poorly even to specific industrial applications on earth. To address this, we propose a method for generating synthetic image data that are labelled for semantic segmentation, generalizable to other tasks, and provide a prototype synthetic image dataset consisting of 2D monocular images of unmanned spacecraft, in order to enable further research in the area of autonomous spacecraft rendezvous. We also present a strong benchmark result (S{\o}rensen-Dice coefficient 0.8723) on these synthetic data, suggesting that it is feasible to train well-performing image segmentation models for this task, especially if the target spacecraft and its configuration are known.
METER-ML: A Multi-sensor Earth Observation Benchmark for Automated Methane Source Mapping
Jul 22, 2022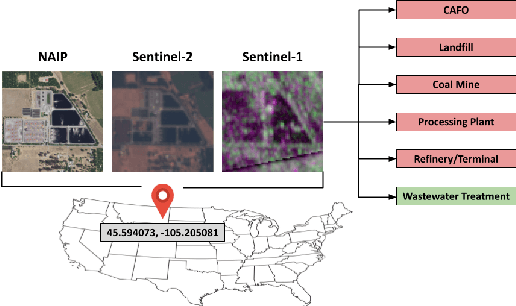
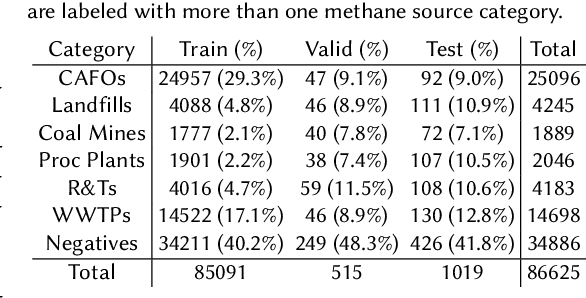


Reducing methane emissions is essential for mitigating global warming. To attribute methane emissions to their sources, a comprehensive dataset of methane source infrastructure is necessary. Recent advancements with deep learning on remotely sensed imagery have the potential to identify the locations and characteristics of methane sources, but there is a substantial lack of publicly available data to enable machine learning researchers and practitioners to build automated mapping approaches. To help fill this gap, we construct a multi-sensor dataset called METER-ML containing 86,625 georeferenced NAIP, Sentinel-1, and Sentinel-2 images in the U.S. labeled for the presence or absence of methane source facilities including concentrated animal feeding operations, coal mines, landfills, natural gas processing plants, oil refineries and petroleum terminals, and wastewater treatment plants. We experiment with a variety of models that leverage different spatial resolutions, spatial footprints, image products, and spectral bands. We find that our best model achieves an area under the precision recall curve of 0.915 for identifying concentrated animal feeding operations and 0.821 for oil refineries and petroleum terminals on an expert-labeled test set, suggesting the potential for large-scale mapping. We make METER-ML freely available at https://stanfordmlgroup.github.io/projects/meter-ml/ to support future work on automated methane source mapping.