 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Diffusion Perturbations for Measuring Fairness in Computer Vision
Paper and Code
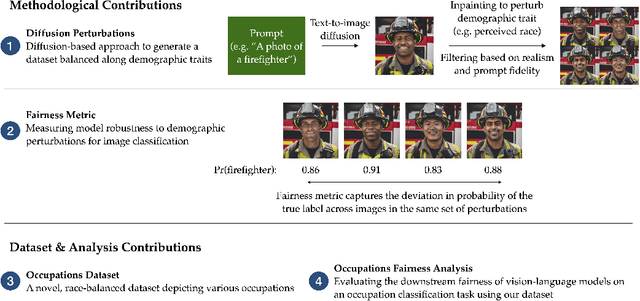
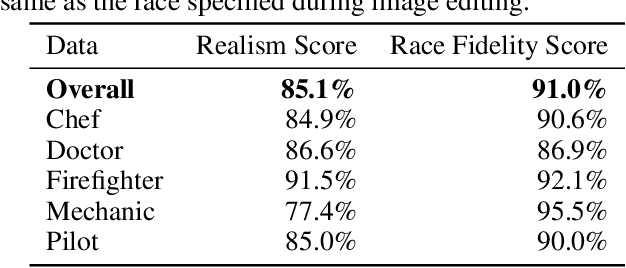


Computer vision models have been known to encode harmful biases, leading to the potentially unfair treatment of historically marginalized groups, such as people of color. However, there remains a lack of datasets balanced along demographic traits that can be used to evaluate the downstream fairness of these models. In this work, we demonstrate that diffusion models can be leveraged to create such a dataset. We first use a diffusion model to generate a large set of images depicting various occupations. Subsequently, each image is edited using inpainting to generate multiple variants, where each variant refers to a different perceived race. Using this dataset, we benchmark several vision-language models on a multi-class occupation classification task. We find that images generated with non-Caucasian labels have a significantly higher occupation misclassification rate than images generated with Caucasian labels, and that several misclassifications are suggestive of racial biases. We measure a model's downstream fairness by computing the standard deviation in the probability of predicting the true occupation label across the different perceived identity groups. Using this fairness metric, we find significant disparities between the evaluated vision-and-language models. We hope that our work demonstrates the potential value of diffusion methods for fairness evaluations.