 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data for Semantic Image Segmentation of Imagery of Unmanned Spacecraft
Nov 22, 2022



Images of spacecraft photographed from other spacecraft operating in outer space are difficult to come by, especially at a scale typically required for deep learning tasks. Semantic image segmentation, object detection and localization, and pose estimation are well researched areas with powerful results for many applications, and would be very useful in autonomous spacecraft operation and rendezvous. However, recent studies show that these strong results in broad and common domains may generalize poorly even to specific industrial applications on earth. To address this, we propose a method for generating synthetic image data that are labelled for semantic segmentation, generalizable to other tasks, and provide a prototype synthetic image dataset consisting of 2D monocular images of unmanned spacecraft, in order to enable further research in the area of autonomous spacecraft rendezvous. We also present a strong benchmark result (S{\o}rensen-Dice coefficient 0.8723) on these synthetic data, suggesting that it is feasible to train well-performing image segmentation models for this task, especially if the target spacecraft and its configuration are known.
Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference
Nov 21, 2022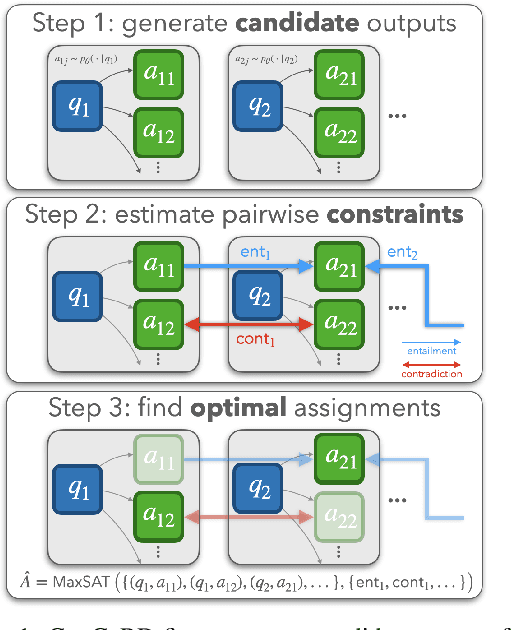
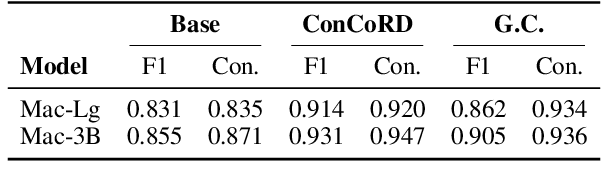

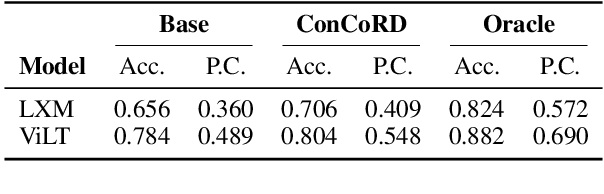
While large pre-trained language models are powerful, their predictions often lack logical consistency across test inputs. For example, a state-of-the-art Macaw question-answering (QA) model answers 'Yes' to 'Is a sparrow a bird?' and 'Does a bird have feet?' but answers 'No' to 'Does a sparrow have feet?'. To address this failure mode, we propose a framework, Consistency Correction through Relation Detection, or ConCoRD, for boosting the consistency and accuracy of pre-trained NLP models using pre-trained natural language inference (NLI) models without fine-tuning or re-training. Given a batch of test inputs, ConCoRD samples several candidate outputs for each input and instantiates a factor graph that accounts for both the model's belief about the likelihood of each answer choice in isolation and the NLI model's beliefs about pair-wise answer choice compatibility. We show that a weighted MaxSAT solver can efficiently compute high-quality answer choices under this factor graph, improving over the raw model's predictions. Our experiments demonstrate that ConCoRD consistently boosts accuracy and consistency of off-the-shelf closed-book QA and VQA models using off-the-shelf NLI models, notably increasing accuracy of LXMERT on ConVQA by 5% absolute. See https://ericmitchell.ai/emnlp-2022-concord/ for code and data.