 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
Dec 31, 2025Contemporary text-to-image models exhibit a surprising degree of mode collapse, as can be seen when sampling several images given the same text prompt. While previous work has attempted to address this issue by steering the model using guidance mechanisms, or by generating a large pool of candidates and refining them, in this work we take a different direction and aim for diversity in generations via noise optimization. Specifically, we show that a simple noise optimization objective can mitigate mode collapse while preserving the fidelity of the base model. We also analyze the frequency characteristics of the noise and show that alternative noise initializations with different frequency profiles can improve both optimization and search. Our experiments demonstrate that noise optimization yields superior results in terms of generation quality and variety.
Seeing Faces in Things: A Model and Dataset for Pareidolia
Sep 24, 2024



The human visual system is well-tuned to detect faces of all shapes and sizes. While this brings obvious survival advantages, such as a better chance of spotting unknown predators in the bush, it also leads to spurious face detections. ``Face pareidolia'' describes the perception of face-like structure among otherwise random stimuli: seeing faces in coffee stains or clouds in the sky. In this paper, we study face pareidolia from a computer vision perspective. We present an image dataset of ``Faces in Things'', consisting of five thousand web images with human-annotated pareidolic faces. Using this dataset, we examine the extent to which a state-of-the-art human face detector exhibits pareidolia, and find a significant behavioral gap between humans and machines. We find that the evolutionary need for humans to detect animal faces, as well as human faces, may explain some of this gap. Finally, we propose a simple statistical model of pareidolia in images. Through studies on human subjects and our pareidolic face detectors we confirm a key prediction of our model regarding what image conditions are most likely to induce pareidolia. Dataset and Website: https://aka.ms/faces-in-things
Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks
Feb 04, 2022
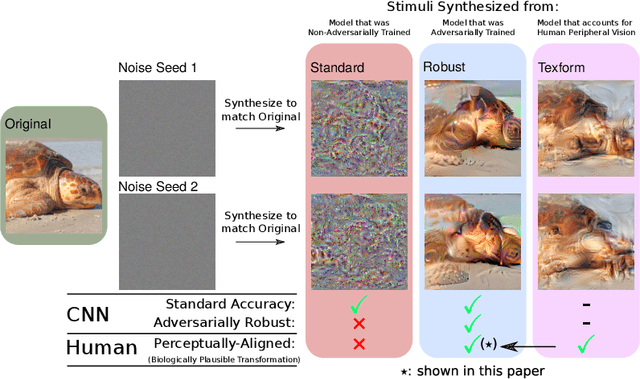
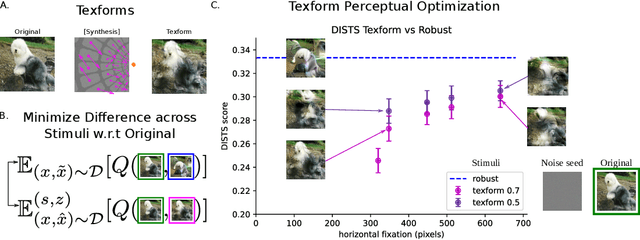
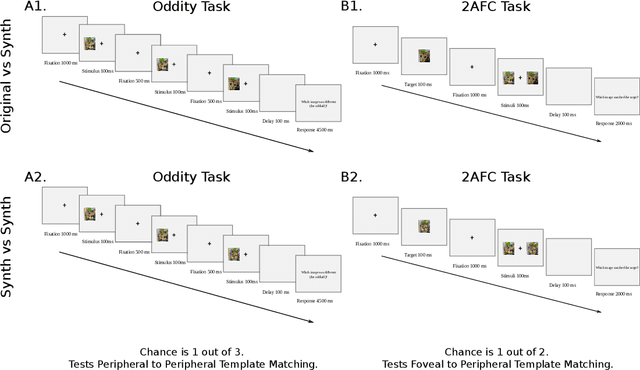
Recent work suggests that representations learned by adversarially robust networks are more human perceptually-aligned than non-robust networks via image manipulations. Despite appearing closer to human visual perception, it is unclear if the constraints in robust DNN representations match biological constraints found in human vision. Human vision seems to rely on texture-based/summary statistic representations in the periphery, which have been shown to explain phenomena such as crowding and performance on visual search tasks. To understand how adversarially robust optimizations/representations compare to human vision, we performed a psychophysics experiment using a set of metameric discrimination tasks where we evaluated how well human observers could distinguish between images synthesized to match adversarially robust representations compared to non-robust representations and a texture synthesis model of peripheral vision (Texforms). We found that the discriminability of robust representation and texture model images decreased to near chance performance as stimuli were presented farther in the periphery. Moreover, performance on robust and texture-model images showed similar trends within participants, while performance on non-robust representations changed minimally across the visual field. These results together suggest that (1) adversarially robust representations capture peripheral computation better than non-robust representations and (2) robust representations capture peripheral computation similar to current state-of-the-art texture peripheral vision models. More broadly, our findings support the idea that localized texture summary statistic representations may drive human invariance to adversarial perturbations and that the incorporation of such representations in DNNs could give rise to useful properties like adversarial robustness.