 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveaTer: Foveated Transformer for Image Classification
Paper and Code
May 29, 2021
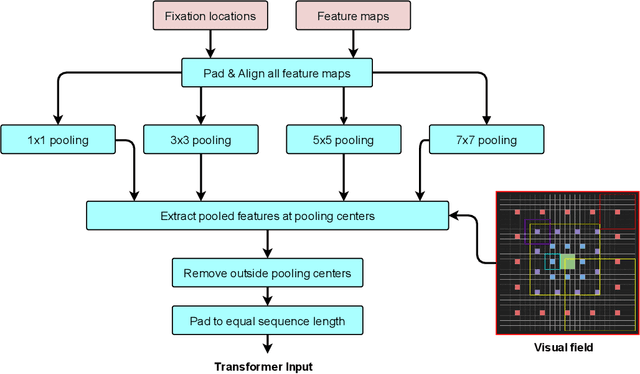
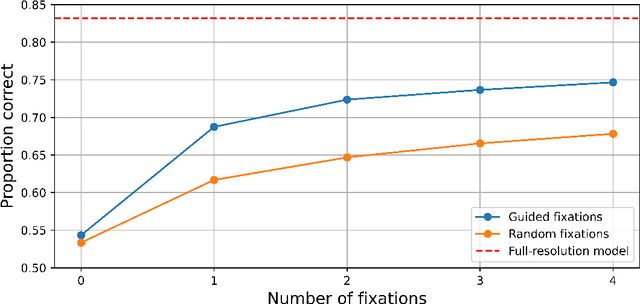
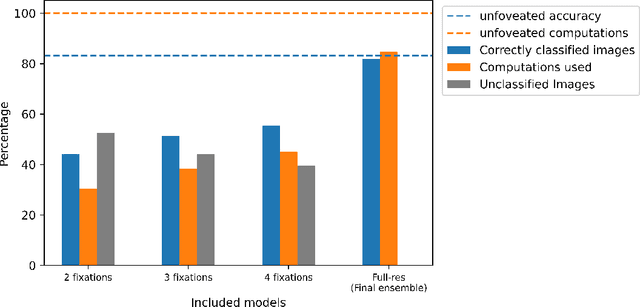
Many animals and humans process the visual field with a varying spatial resolution (foveated vision) and use peripheral processing to make eye movements and point the fovea to acquire high-resolution information about objects of interest. This architecture results in computationally efficient rapid scene exploration. Recent progress in vision Transformers has brought about new alternatives to the traditionally convolution-reliant computer vision systems. However, these models do not explicitly model the foveated properties of the visual system nor the interaction between eye movements and the classification task. We propose foveated Transformer (FoveaTer) model, which uses pooling regions and saccadic movements to perform object classification tasks using a vision Transformer architecture. Our proposed model pools the image features using squared pooling regions, an approximation to the biologically-inspired foveated architecture, and uses the pooled features as an input to a Transformer Network. It decides on the following fixation location based on the attention assigned by the Transformer to various locations from previous and present fixations. The model uses a confidence threshold to stop scene exploration, allowing to dynamically allocate more fixation/computational resources to more challenging images. We construct an ensemble model using our proposed model and unfoveated model, achieving an accuracy 1.36% below the unfoveated model with 22% computational savings. Finally, we demonstrate our model's robustness against adversarial attacks, where it outperforms the unfoveated model.