 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Network Model Observers Discount Signal-like Anatomical Structures During Search in Virtual Digital Breast Tomosynthesis Phantoms
May 23, 2024Model observers are computational tools to evaluate and optimize task-based medical image quality. Linear model observers, such as the Channelized Hotelling Observer (CHO), predict human accuracy in detection tasks with a few possible signal locations in clinical phantoms or real anatomic backgrounds. In recent years, Convolutional Neural Networks (CNNs) have been proposed as a new type of model observer. What is not well understood is what CNNs add over the more common linear model observer approaches. We compare the CHO and CNN detection accuracy to the radiologist's accuracy in searching for two types of signals (mass and microcalcification) embedded in 2D/3D breast tomosynthesis phantoms (DBT). We show that the CHO model's accuracy is comparable to the CNN's performance for a location-known-exactly detection task. However, for the search task with 2D/3D DBT phantoms, the CHO's detection accuracy was significantly lower than the CNN accuracy. A comparison to the radiologist's accuracy showed that the CNN but not the CHO could match or exceed the radiologist's accuracy in the 2D microcalcification and 3D mass search conditions. An analysis of the eye position showed that radiologists fixated more often and longer at the locations corresponding to CNN false positives. Most CHO false positives were the phantom's normal anatomy and were not fixated by radiologists. In conclusion, we show that CNNs can be used as an anthropomorphic model observer for the search task for which traditional linear model observers fail due to their inability to discount false positives arising from the anatomical backgrounds.
DEMIST: A deep-learning-based task-specific denoising approach for myocardial perfusion SPECT
Jun 14, 2023



There is an important need for methods to process myocardial perfusion imaging (MPI) SPECT images acquired at lower radiation dose and/or acquisition time such that the processed images improve observer performance on the clinical task of detecting perfusion defects. To address this need, we build upon concepts from model-observer theory and our understanding of the human visual system to propose a Detection task-specific deep-learning-based approach for denoising MPI SPECT images (DEMIST). The approach, while performing denoising, is designed to preserve features that influence observer performance on detection tasks. We objectively evaluated DEMIST on the task of detecting perfusion defects using a retrospective study with anonymized clinical data in patients who underwent MPI studies across two scanners (N = 338). The evaluation was performed at low-dose levels of 6.25%, 12.5% and 25% and using an anthropomorphic channelized Hotelling observer. Performance was quantified using area under the receiver operating characteristics curve (AUC). Images denoised with DEMIST yielded significantly higher AUC compared to corresponding low-dose images and images denoised with a commonly used task-agnostic DL-based denoising method. Similar results were observed with stratified analysis based on patient sex and defect type. Additionally, DEMIST improved visual fidelity of the low-dose images as quantified using root mean squared error and structural similarity index metric. A mathematical analysis revealed that DEMIST preserved features that assist in detection tasks while improving the noise properties, resulting in improved observer performance. The results provide strong evidence for further clinical evaluation of DEMIST to denoise low-count images in MPI SPECT.
Development and task-based evaluation of a scatter-window projection and deep learning-based transmission-less attenuation compensation method for myocardial perfusion SPECT
Mar 19, 2023Attenuation compensation (AC) is beneficial for visual interpretation tasks in single-photon emission computed tomography (SPECT) myocardial perfusion imaging (MPI). However, traditional AC methods require the availability of a transmission scan, most often a CT scan. This approach has the disadvantages of increased radiation dose, increased scanner cost, and the possibility of inaccurate diagnosis in cases of misregistration between the SPECT and CT images. Further, many SPECT systems do not include a CT component. To address these issues, we developed a Scatter-window projection and deep Learning-based AC (SLAC) method to perform AC without a separate transmission scan. To investigate the clinical efficacy of this method, we then objectively evaluated the performance of this method on the clinical task of detecting perfusion defects on MPI in a retrospective study with anonymized clinical SPECT/CT stress MPI images. The proposed method was compared with CT-based AC (CTAC) and no-AC (NAC) methods. Our results showed that the SLAC method yielded an almost overlapping receiver operating characteristic (ROC) plot and a similar area under the ROC (AUC) to the CTAC method on this task. These results demonstrate the capability of the SLAC method for transmission-less AC in SPECT and motivate further clinical evaluation.
Medical Image Quality Metrics for Foveated Model Observers
Feb 09, 2021
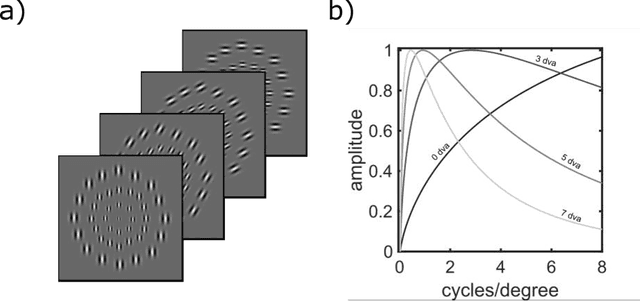

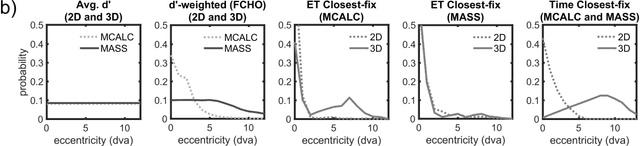
A recently proposed model observer mimics the foveated nature of the human visual system by processing the entire image with varying spatial detail, executing eye movements and scrolling through slices. The model can predict how human search performance changes with signal type and modality (2D vs. 3D), yet its implementation is computationally expensive and time-consuming. Here, we evaluate various image quality metrics using extensions of the classic index of detectability expressions and assess foveated model observers for location-known exactly tasks. We evaluated foveated extensions of a Channelized Hotelling and Non-prewhitening model with an eye filter. The proposed methods involve calculating a model index of detectability (d') for each retinal eccentricity and combining these with a weighting function into a single detectability metric. We assessed different versions of the weighting function that varied in the required measurements of the human observers' search (no measurements, eye movement patterns, and size of the image and median search times). We show that the index of detectability across eccentricities weighted using the eye movement patterns of observers best predicted human performance in 2D vs. 3D search performance for a small microcalcification-like signal and a larger mass-like. The metric with weighting function based on median search times was the second best at predicting human results. The findings provide a set of model observer tools to evaluate image quality in the early stages of imaging system evaluation or design without implementing the more computationally complex foveated search model.