 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle-Based Adaptive Discretization for Continuous Control using Deep Reinforcement Learning
Paper and Code


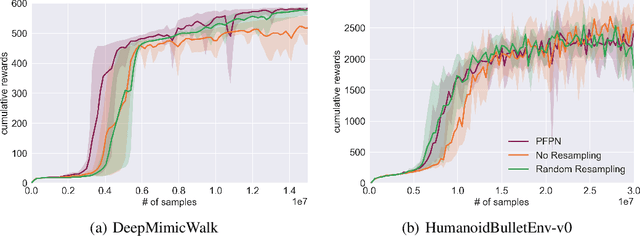
Learning controls in high-dimensional continuous action spaces, such as controlling the movements of highly articulated agents and robots, has long been a standing challenge to model-free deep reinforcement learning (DRL). In this paper we propose a general, yet simple, framework for improving the action exploration of policy gradient DRL algorithms. Our approach adapts ideas from the particle filtering literature to dynamically discretize the continuous action space and track policies represented as a mixture of Gaussians. We demonstrate the applicability of our approach on state-of-the-art DRL baselines in challenging high-dimensional motor tasks involving articulated agents. We show that our adaptive particle-based discretization leads to improved final performance and speed of convergence as compared to uniform discretization schemes and to corresponding implementations in continuous action spaces, highlighting the importance of exploration. In addition, the resulting policies are more stable, exhibiting less variance across different training trials.