 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast ADMM Algorithm for Distributed Optimization with Adaptive Penalty
Paper and Code
Jun 30, 2015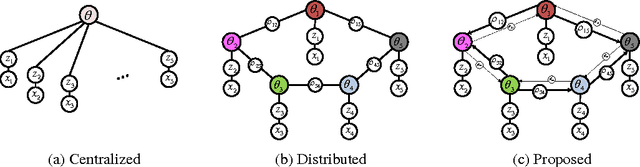
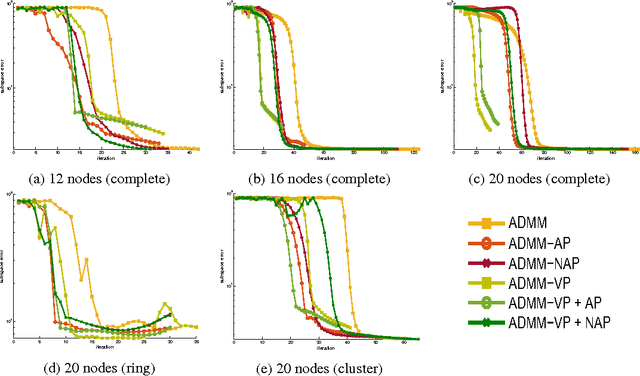
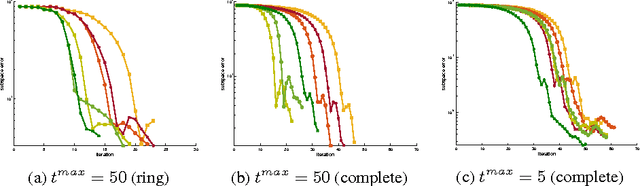
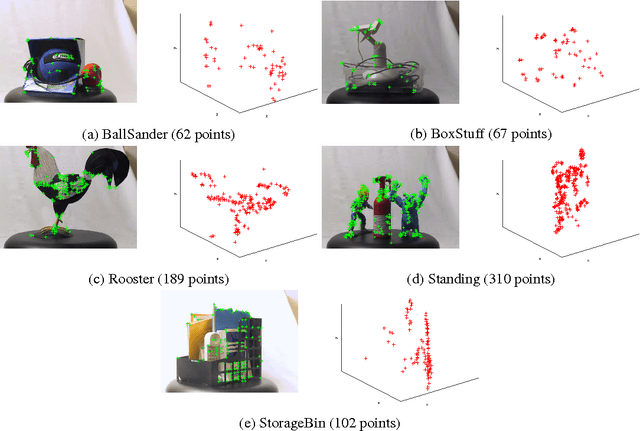
We propose new methods to speed up convergence of the Alternating Direction Method of Multipliers (ADMM), a common optimization tool in the context of large scale and distributed learning. The proposed method accelerates the speed of convergence by automatically deciding the constraint penalty needed for parameter consensus in each iteration. In addition, we also propose an extension of the method that adaptively determines the maximum number of iterations to update the penalty. We show that this approach effectively leads to an adaptive, dynamic network topology underlying the distributed optimization. The utility of the new penalty update schemes is demonstrated on both synthetic and real data, including a computer vision application of distributed structure from motion.