 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Sex Classification of Children's Voices and Changes in Differentiating Factors with Age
Paper and Code
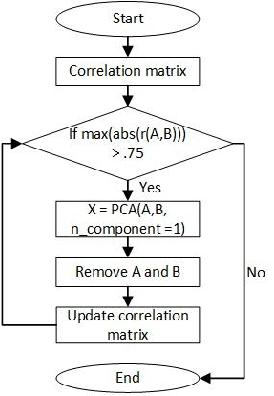
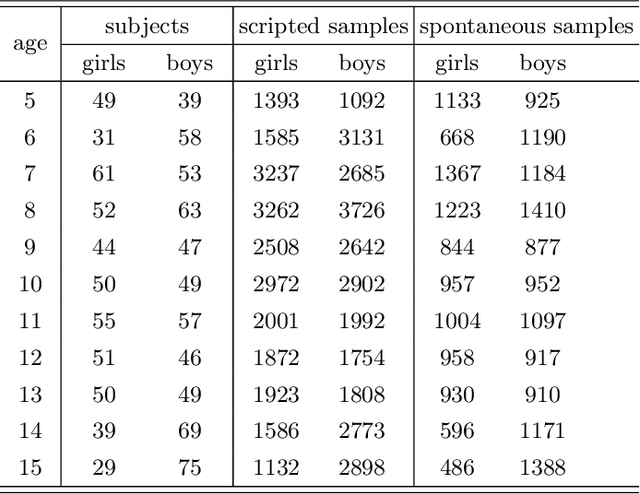
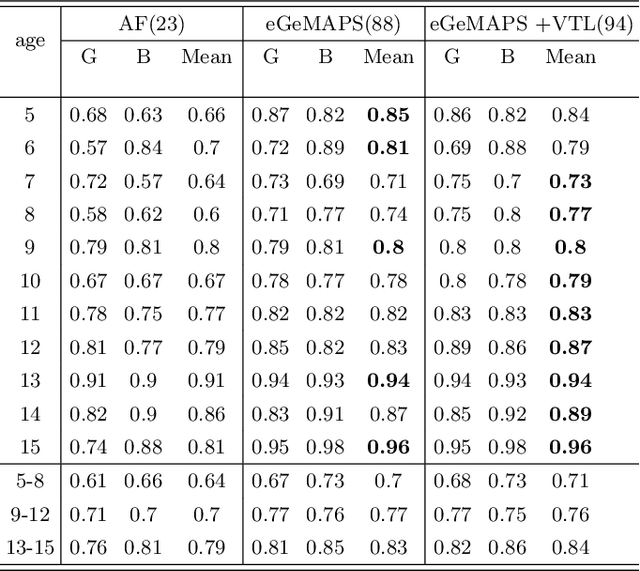
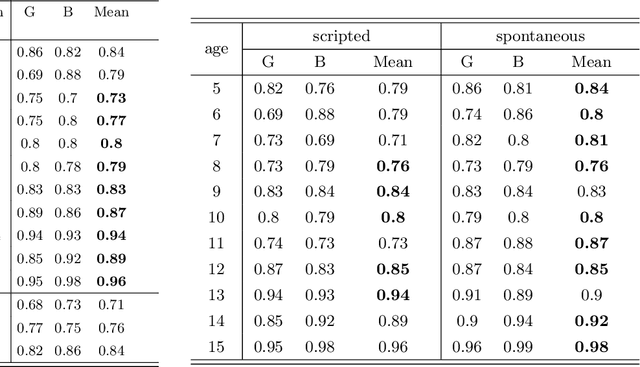
Sex classification of children's voices allows for an investigation of the development of secondary sex characteristics which has been a key interest in the field of speech analysis. This research investigated a broad range of acoustic features from scripted and spontaneous speech and applied a hierarchical clustering-based machine learning model to distinguish the sex of children aged between 5 and 15 years. We proposed an optimal feature set and our modelling achieved an average F1 score (the harmonic mean of the precision and recall) of 0.84 across all ages. Our results suggest that the sex classification is generally more accurate when a model is developed for each year group rather than for children in 4-year age bands, with classification accuracy being better for older age groups. We found that spontaneous speech could provide more helpful cues in sex classification than scripted speech, especially for children younger than 7 years. For younger age groups, a broad range of acoustic factors contributed evenly to sex classification, while for older age groups, F0-related acoustic factors were found to be the most critical predictors generally. Other important acoustic factors for older age groups include vocal tract length estimators, spectral flux, loudness and unvoiced features.