 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Reinforcement Learning for Audio-Based Applications
Paper and Code
Jan 01, 2021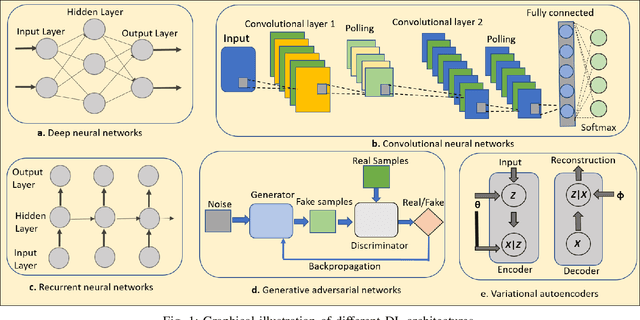
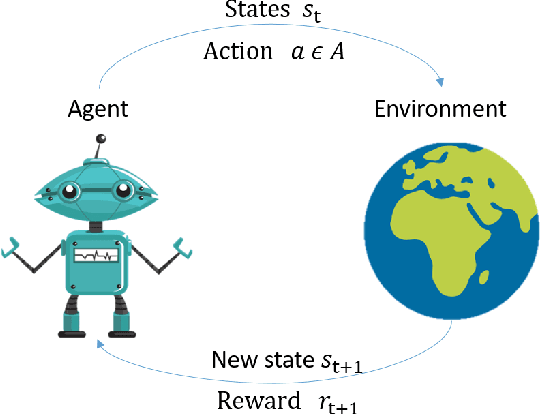
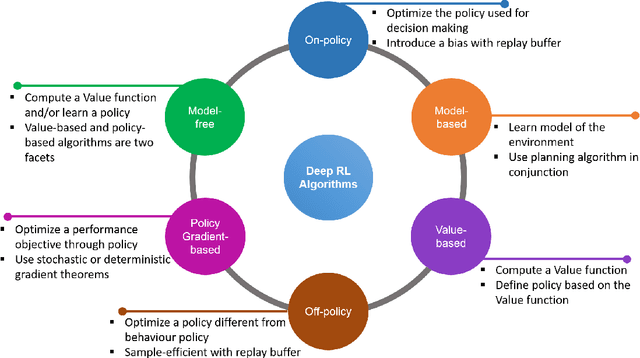
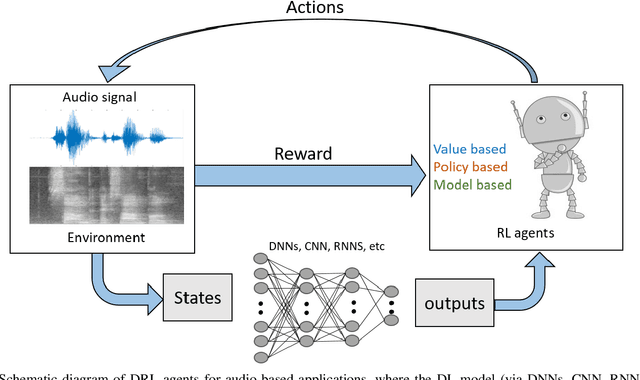
Deep reinforcement learning (DRL) is poised to revolutionise the field of artificial intelligence (AI) by endowing autonomous systems with high levels of understanding of the real world. Currently, deep learning (DL) is enabling DRL to effectively solve various intractable problems in various fields. Most importantly, DRL algorithms are also being employed in audio signal processing to learn directly from speech, music and other sound signals in order to create audio-based autonomous systems that have many promising application in the real world. In this article, we conduct a comprehensive survey on the progress of DRL in the audio domain by bringing together the research studies across different speech and music-related areas. We begin with an introduction to the general field of DL and reinforcement learning (RL), then progress to the main DRL methods and their applications in the audio domain. We conclude by presenting challenges faced by audio-based DRL agents and highlighting open areas for future research and investigation.