 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Policy Learning from Demonstration Using Advantage Weighting and Early Termination
Jul 31, 2022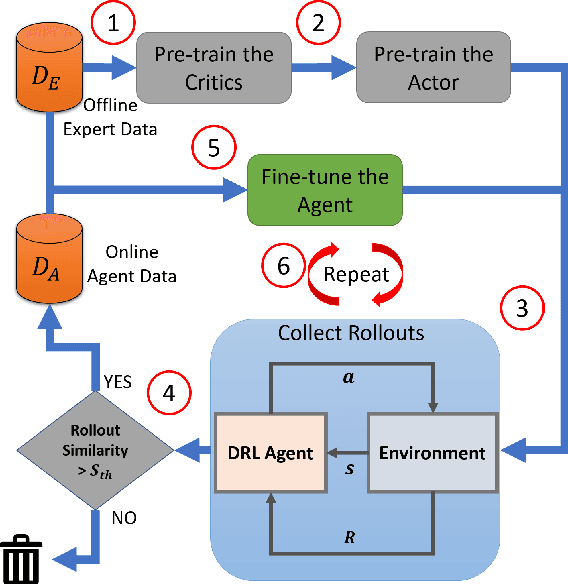

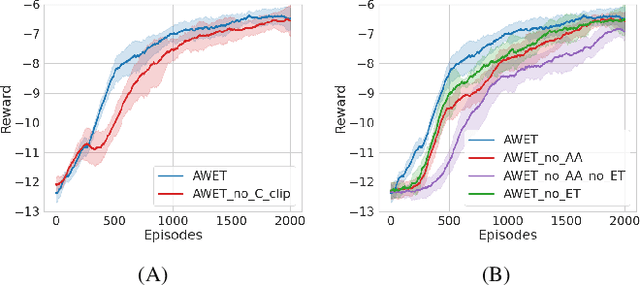
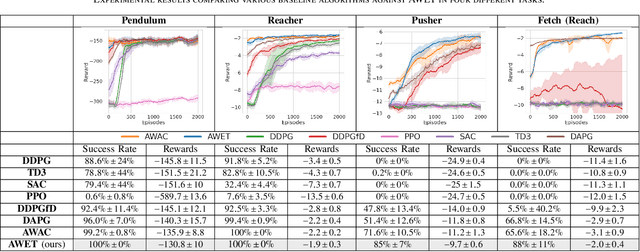
Learning robotic tasks in the real world is still highly challenging and effective practical solutions remain to be found. Traditional methods used in this area are imitation learning and reinforcement learning, but they both have limitations when applied to real robots. Combining reinforcement learning with pre-collected demonstrations is a promising approach that can help in learning control policies to solve robotic tasks. In this paper, we propose an algorithm that uses novel techniques to leverage offline expert data using offline and online training to obtain faster convergence and improved performance. The proposed algorithm (AWET) weights the critic losses with a novel agent advantage weight to improve over the expert data. In addition, AWET makes use of an automatic early termination technique to stop and discard policy rollouts that are not similar to expert trajectories -- to prevent drifting far from the expert data. In an ablation study, AWET showed improved and promising performance when compared to state-of-the-art baselines on four standard robotic tasks.
A Study on Dense and Sparse Rewards in Robot Policy Learning
Aug 06, 2021

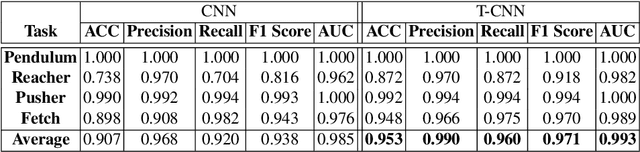
Deep Reinforcement Learning (DRL) is a promising approach for teaching robots new behaviour. However, one of its main limitations is the need for carefully hand-coded reward signals by an expert. We argue that it is crucial to automate the reward learning process so that new skills can be taught to robots by their users. To address such automation, we consider task success classifiers using visual observations to estimate the rewards in terms of task success. In this work, we study the performance of multiple state-of-the-art deep reinforcement learning algorithms under different types of reward: Dense, Sparse, Visual Dense, and Visual Sparse rewards. Our experiments in various simulation tasks (Pendulum, Reacher, Pusher, and Fetch Reach) show that while DRL agents can learn successful behaviours using visual rewards when the goal targets are distinguishable, their performance may decrease if the task goal is not clearly visible. Our results also show that visual dense rewards are more successful than visual sparse rewards and that there is no single best algorithm for all tasks.
Neural Task Success Classifiers for Robotic Manipulation from Few Real Demonstrations
Jul 01, 2021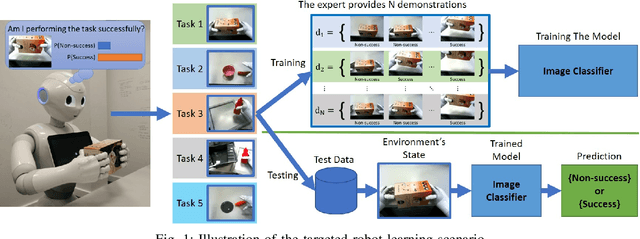
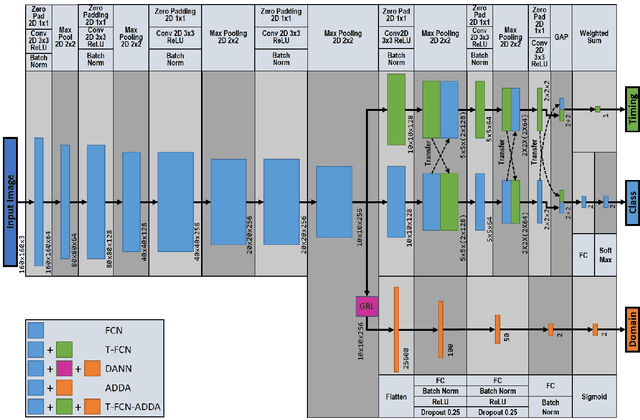
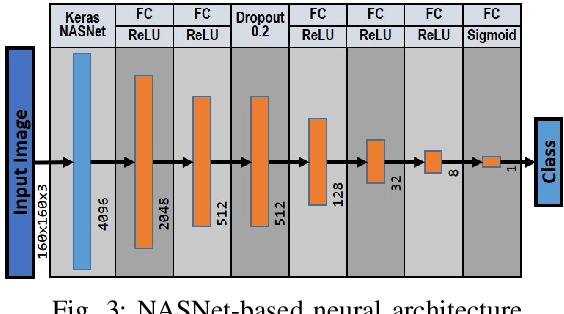
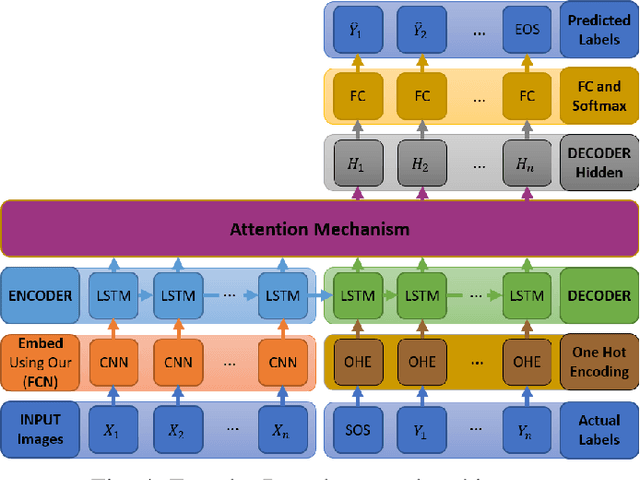
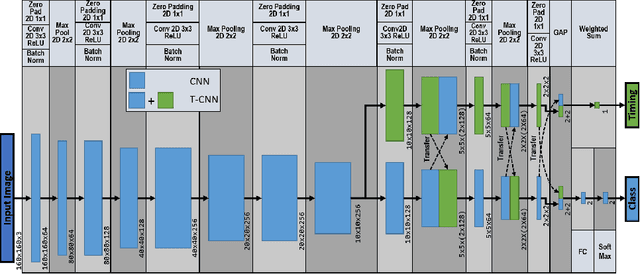
Robots learning a new manipulation task from a small amount of demonstrations are increasingly demanded in different workspaces. A classifier model assessing the quality of actions can predict the successful completion of a task, which can be used by intelligent agents for action-selection. This paper presents a novel classifier that learns to classify task completion only from a few demonstrations. We carry out a comprehensive comparison of different neural classifiers, e.g. fully connected-based, fully convolutional-based, sequence2sequence-based, and domain adaptation-based classification. We also present a new dataset including five robot manipulation tasks, which is publicly available. We compared the performances of our novel classifier and the existing models using our dataset and the MIME dataset. The results suggest domain adaptation and timing-based features improve success prediction. Our novel model, i.e. fully convolutional neural network with domain adaptation and timing features, achieves an average classification accuracy of 97.3\% and 95.5\% across tasks in both datasets whereas state-of-the-art classifiers without domain adaptation and timing-features only achieve 82.4\% and 90.3\%, respectively.