 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset of Robot-Patient and Doctor-Patient Medical Dialogues for Spoken Language Processing Tasks
May 26, 2026Large Language Models (LLMs) have brought huge improvements to Artificial Intelligence (AI), which can be applied to general-purpose tasks. However, their application to textual or spoken medical consultations is still an open research problem. This paper proposes MeDial-Speech, a novel speech dataset for training and evaluating Med-AIs that can carry out consultations with patients. It was collected in realistic environments from robot-patient and doctor-patient dialogues, contains 111+ hours of speech data (without data augmentation), and covers four health conditions: Lewy body dementia, heart failure, shoulder pain, and angina. In addition, we propose a dialogue benchmark via sentence selection (with 20 options) to evaluate three state-of-the-art LLMs: GPT-5 mini, DeepSeek-V3, and Claude Sonnet 4. Experimental results reveal that Claude Sonnet 4 is the best in sentence selection, with 71.1% accuracy using manual transcriptions and 74.7% using automatic transcriptions, and that all LLMs are highly overconfident in their probabilistic predictions, regardless of selecting correct or incorrect sentences in medical dialogues. This dataset is free of charge for non-commercial purposes at: https://huggingface.co/datasets/hcuayahu/MeDial-Speech
Transformers in Speech Processing: A Survey
Mar 21, 2023



The remarkable success of transformers in the field of natural language processing has sparked the interest of the speech-processing community, leading to an exploration of their potential for modeling long-range dependencies within speech sequences. Recently, transformers have gained prominence across various speech-related domains, including automatic speech recognition, speech synthesis, speech translation, speech para-linguistics, speech enhancement, spoken dialogue systems, and numerous multimodal applications. In this paper, we present a comprehensive survey that aims to bridge research studies from diverse subfields within speech technology. By consolidating findings from across the speech technology landscape, we provide a valuable resource for researchers interested in harnessing the power of transformers to advance the field. We identify the challenges encountered by transformers in speech processing while also offering insights into potential solutions to address these issues.
Robot Policy Learning from Demonstration Using Advantage Weighting and Early Termination
Jul 31, 2022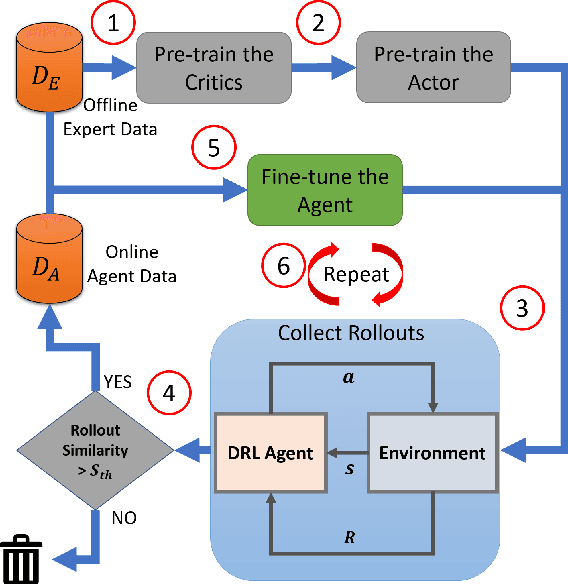

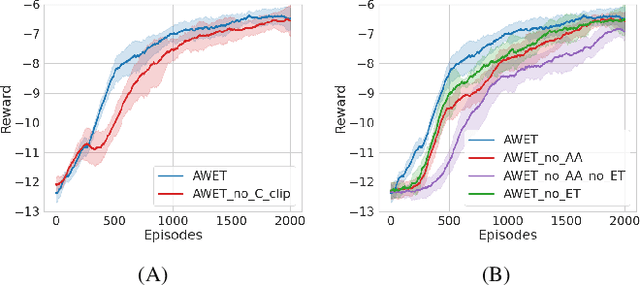
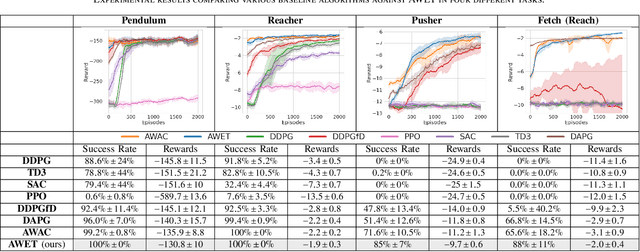
Learning robotic tasks in the real world is still highly challenging and effective practical solutions remain to be found. Traditional methods used in this area are imitation learning and reinforcement learning, but they both have limitations when applied to real robots. Combining reinforcement learning with pre-collected demonstrations is a promising approach that can help in learning control policies to solve robotic tasks. In this paper, we propose an algorithm that uses novel techniques to leverage offline expert data using offline and online training to obtain faster convergence and improved performance. The proposed algorithm (AWET) weights the critic losses with a novel agent advantage weight to improve over the expert data. In addition, AWET makes use of an automatic early termination technique to stop and discard policy rollouts that are not similar to expert trajectories -- to prevent drifting far from the expert data. In an ablation study, AWET showed improved and promising performance when compared to state-of-the-art baselines on four standard robotic tasks.
A Study on Dense and Sparse Rewards in Robot Policy Learning
Aug 06, 2021

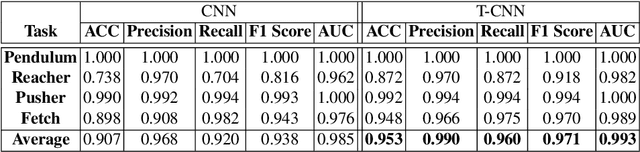
Deep Reinforcement Learning (DRL) is a promising approach for teaching robots new behaviour. However, one of its main limitations is the need for carefully hand-coded reward signals by an expert. We argue that it is crucial to automate the reward learning process so that new skills can be taught to robots by their users. To address such automation, we consider task success classifiers using visual observations to estimate the rewards in terms of task success. In this work, we study the performance of multiple state-of-the-art deep reinforcement learning algorithms under different types of reward: Dense, Sparse, Visual Dense, and Visual Sparse rewards. Our experiments in various simulation tasks (Pendulum, Reacher, Pusher, and Fetch Reach) show that while DRL agents can learn successful behaviours using visual rewards when the goal targets are distinguishable, their performance may decrease if the task goal is not clearly visible. Our results also show that visual dense rewards are more successful than visual sparse rewards and that there is no single best algorithm for all tasks.