 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Dense and Sparse Rewards in Robot Policy Learning
Paper and Code
Aug 06, 2021

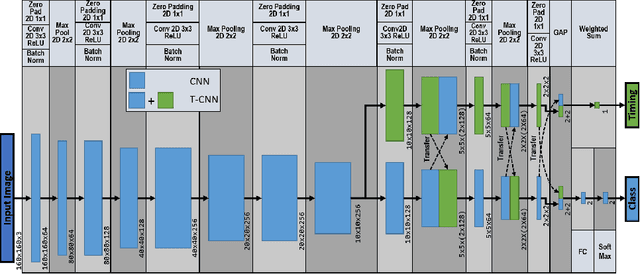
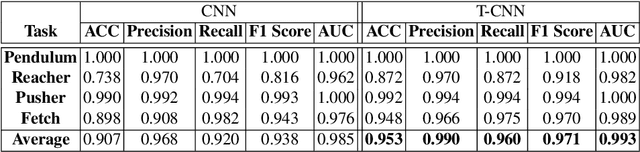
Deep Reinforcement Learning (DRL) is a promising approach for teaching robots new behaviour. However, one of its main limitations is the need for carefully hand-coded reward signals by an expert. We argue that it is crucial to automate the reward learning process so that new skills can be taught to robots by their users. To address such automation, we consider task success classifiers using visual observations to estimate the rewards in terms of task success. In this work, we study the performance of multiple state-of-the-art deep reinforcement learning algorithms under different types of reward: Dense, Sparse, Visual Dense, and Visual Sparse rewards. Our experiments in various simulation tasks (Pendulum, Reacher, Pusher, and Fetch Reach) show that while DRL agents can learn successful behaviours using visual rewards when the goal targets are distinguishable, their performance may decrease if the task goal is not clearly visible. Our results also show that visual dense rewards are more successful than visual sparse rewards and that there is no single best algorithm for all tasks.