 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing a Knowledge Graph from Unstructured Documents without External Alignment
Paper and Code

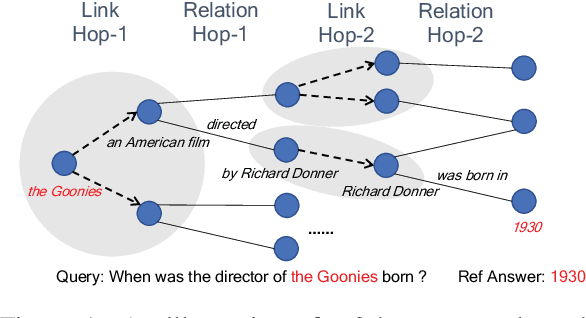
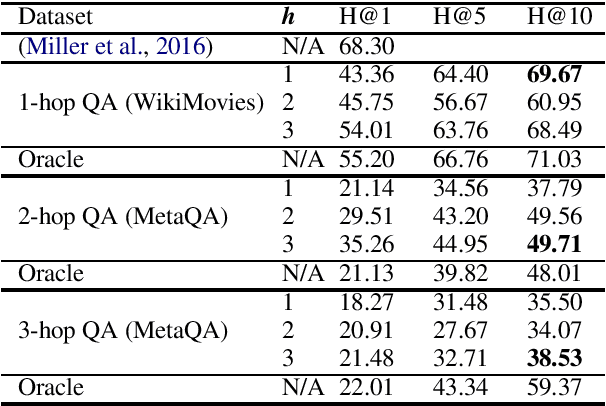

Knowledge graphs (KGs) are relevant to many NLP tasks, but building a reliable domain-specific KG is time-consuming and expensive. A number of methods for constructing KGs with minimized human intervention have been proposed, but still require a process to align into the human-annotated knowledge base. To overcome this issue, we propose a novel method to automatically construct a KG from unstructured documents that does not require external alignment and explore its use to extract desired information. To summarize our approach, we first extract knowledge tuples in their surface form from unstructured documents, encode them using a pre-trained language model, and link the surface-entities via the encoding to form the graph structure. We perform experiments with benchmark datasets such as WikiMovies and MetaQA. The experimental results show that our method can successfully create and search a KG with 18K documents and achieve 69.7% hits@10 (close to an oracle model) on a query retrieval task.