 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve, Rerank, Read, then Iterate: Answering Open-Domain Questions of Arbitrary Complexity from Text
Paper and Code


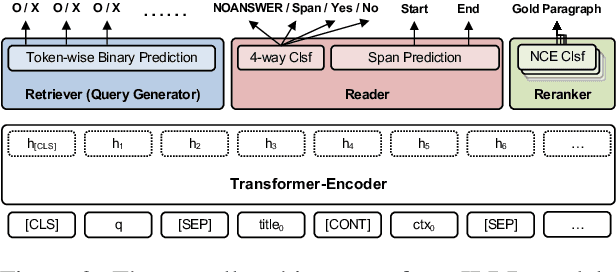

Current approaches to open-domain question answering often make crucial assumptions that prevent them from generalizing to real-world settings, including the access to parameterized retrieval systems well-tuned for the task, access to structured metadata like knowledge bases and web links, or a priori knowledge of the complexity of questions to be answered (e.g., single-hop or multi-hop). To address these limitations, we propose a unified system to answer open-domain questions of arbitrary complexity directly from text that works with off-the-shelf retrieval systems on arbitrary text collections. We employ a single multi-task model to perform all the necessary subtasks---retrieving supporting facts, reranking them, and predicting the answer from all retrieved documents---in an iterative fashion. To emulate a more realistic setting, we also constructed a new unified benchmark by collecting about 200 multi-hop questions that require three Wikipedia pages to answer, and combining them with existing datasets. We show that our model not only outperforms state-of-the-art systems on several existing benchmarks that exclusively feature single-hop or multi-hop open-domain questions, but also achieves strong performance on the new benchmark.