 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Span-Selective Linear Attention Transformers for Effective and Robust Schema-Guided Dialogue State Tracking
Jun 15, 2023



In schema-guided dialogue state tracking models estimate the current state of a conversation using natural language descriptions of the service schema for generalization to unseen services. Prior generative approaches which decode slot values sequentially do not generalize well to variations in schema, while discriminative approaches separately encode history and schema and fail to account for inter-slot and intent-slot dependencies. We introduce SPLAT, a novel architecture which achieves better generalization and efficiency than prior approaches by constraining outputs to a limited prediction space. At the same time, our model allows for rich attention among descriptions and history while keeping computation costs constrained by incorporating linear-time attention. We demonstrate the effectiveness of our model on the Schema-Guided Dialogue (SGD) and MultiWOZ datasets. Our approach significantly improves upon existing models achieving 85.3 JGA on the SGD dataset. Further, we show increased robustness on the SGD-X benchmark: our model outperforms the more than 30$\times$ larger D3ST-XXL model by 5.0 points.
Co-attentional Transformers for Story-Based Video Understanding
Oct 27, 2020

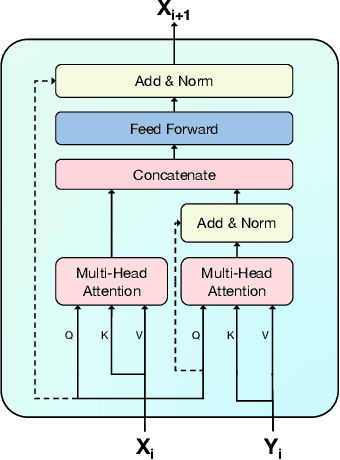
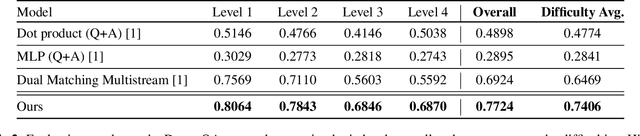
Inspired by recent trends in vision and language learning, we explore applications of attention mechanisms for visio-lingual fusion within an application to story-based video understanding. Like other video-based QA tasks, video story understanding requires agents to grasp complex temporal dependencies. However, as it focuses on the narrative aspect of video it also requires understanding of the interactions between different characters, as well as their actions and their motivations. We propose a novel co-attentional transformer model to better capture long-term dependencies seen in visual stories such as dramas and measure its performance on the video question answering task. We evaluate our approach on the recently introduced DramaQA dataset which features character-centered video story understanding questions. Our model outperforms the baseline model by 8 percentage points overall, at least 4.95 and up to 12.8 percentage points on all difficulty levels and manages to beat the winner of the DramaQA challenge.