 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-attentional Transformers for Story-Based Video Understanding
Paper and Code
Oct 27, 2020

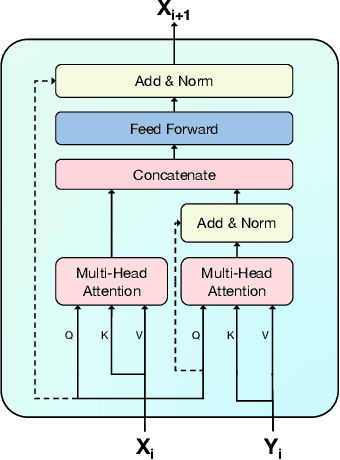
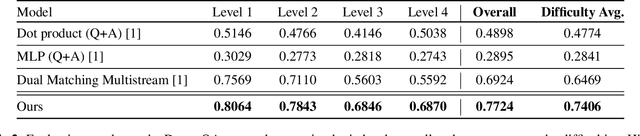
Inspired by recent trends in vision and language learning, we explore applications of attention mechanisms for visio-lingual fusion within an application to story-based video understanding. Like other video-based QA tasks, video story understanding requires agents to grasp complex temporal dependencies. However, as it focuses on the narrative aspect of video it also requires understanding of the interactions between different characters, as well as their actions and their motivations. We propose a novel co-attentional transformer model to better capture long-term dependencies seen in visual stories such as dramas and measure its performance on the video question answering task. We evaluate our approach on the recently introduced DramaQA dataset which features character-centered video story understanding questions. Our model outperforms the baseline model by 8 percentage points overall, at least 4.95 and up to 12.8 percentage points on all difficulty levels and manages to beat the winner of the DramaQA challenge.