 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifiedCrawl: Aggregated Common Crawl for Affordable Adaptation of LLMs on Low-Resource Languages
Nov 21, 2024



Large language models (LLMs) under-perform on low-resource languages due to limited training data. We present a method to efficiently collect text data for low-resource languages from the entire Common Crawl corpus. Our approach, UnifiedCrawl, filters and extracts common crawl using minimal compute resources, yielding mono-lingual datasets much larger than previously available sources. We demonstrate that leveraging this data to fine-tuning multilingual LLMs via efficient adapter methods (QLoRA) significantly boosts performance on the low-resource language, while minimizing VRAM usage. Our experiments show large improvements in language modeling perplexity and an increase in few-shot prompting scores. Our work and released source code provide an affordable approach to improve LLMs for low-resource languages using consumer hardware. Our source code is available here at https://github.com/bethelmelesse/unifiedcrawl.
Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
FiE: Building a Global Probability Space by Leveraging Early Fusion in Encoder for Open-Domain Question Answering
Nov 18, 2022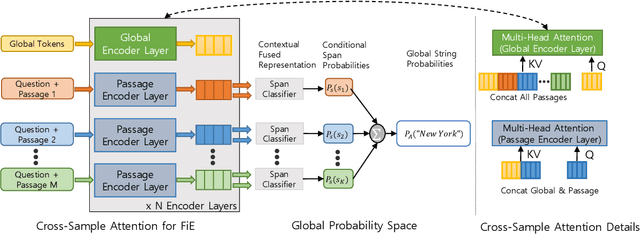



Generative models have recently started to outperform extractive models in Open Domain Question Answering, largely by leveraging their decoder to attend over multiple encoded passages and combining their information. However, generative models tend to be larger than extractive models due to the need for a decoder, run slower during inference due to auto-regressive decoder beam search, and their generated output often suffers from hallucinations. We propose to extend transformer encoders with the ability to fuse information from multiple passages, using global representation to provide cross-sample attention over all tokens across samples. Furthermore, we propose an alternative answer span probability calculation to better aggregate answer scores in the global space of all samples. Using our proposed method, we outperform the current state-of-the-art method by $2.5$ Exact Match score on the Natural Question dataset while using only $25\%$ of parameters and $35\%$ of the latency during inference, and $4.4$ Exact Match on WebQuestions dataset. When coupled with synthetic data augmentation, we outperform larger models on the TriviaQA dataset as well. The latency and parameter savings of our method make it particularly attractive for open-domain question answering, as these models are often compute-intensive.
You Only Need One Model for Open-domain Question Answering
Dec 14, 2021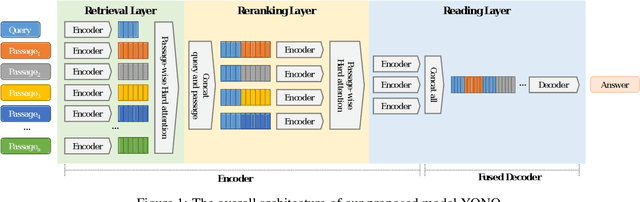
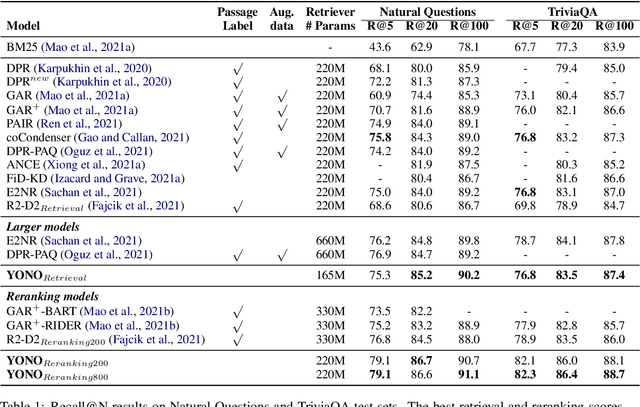
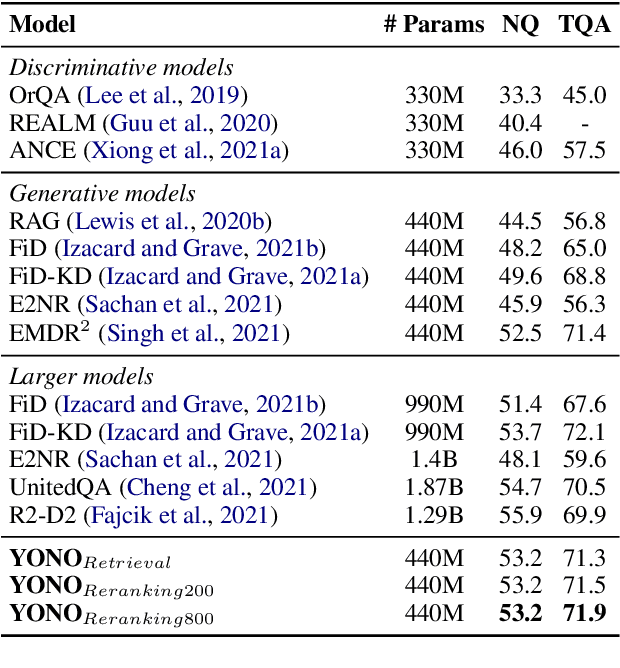
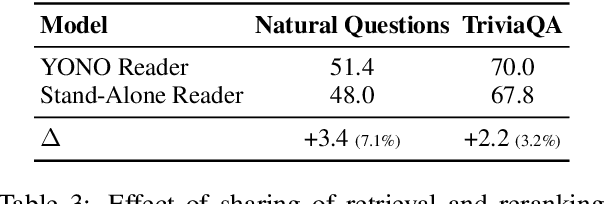
Recent works for Open-domain Question Answering refer to an external knowledge base using a retriever model, optionally rerank the passages with a separate reranker model and generate an answer using an another reader model. Despite performing related tasks, the models have separate parameters and are weakly-coupled during training. In this work, we propose casting the retriever and the reranker as hard-attention mechanisms applied sequentially within the transformer architecture and feeding the resulting computed representations to the reader. In this singular model architecture the hidden representations are progressively refined from the retriever to the reranker to the reader, which is more efficient use of model capacity and also leads to better gradient flow when we train it in an end-to-end manner. We also propose a pre-training methodology to effectively train this architecture. We evaluate our model on Natural Questions and TriviaQA open datasets and for a fixed parameter budget, our model outperforms the previous state-of-the-art model by 1.0 and 0.7 exact match scores.