 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Attention Guidance: Universal Negative Guidance for Diffusion Model
May 27, 2025Negative guidance -- explicitly suppressing unwanted attributes -- remains a fundamental challenge in diffusion models, particularly in few-step sampling regimes. While Classifier-Free Guidance (CFG) works well in standard settings, it fails under aggressive sampling step compression due to divergent predictions between positive and negative branches. We present Normalized Attention Guidance (NAG), an efficient, training-free mechanism that applies extrapolation in attention space with L1-based normalization and refinement. NAG restores effective negative guidance where CFG collapses while maintaining fidelity. Unlike existing approaches, NAG generalizes across architectures (UNet, DiT), sampling regimes (few-step, multi-step), and modalities (image, video), functioning as a \textit{universal} plug-in with minimal computational overhead. Through extensive experimentation, we demonstrate consistent improvements in text alignment (CLIP Score), fidelity (FID, PFID), and human-perceived quality (ImageReward). Our ablation studies validate each design component, while user studies confirm significant preference for NAG-guided outputs. As a model-agnostic inference-time approach requiring no retraining, NAG provides effortless negative guidance for all modern diffusion frameworks -- pseudocode in the Appendix!
NitroFusion: High-Fidelity Single-Step Diffusion through Dynamic Adversarial Training
Dec 02, 2024We introduce NitroFusion, a fundamentally different approach to single-step diffusion that achieves high-quality generation through a dynamic adversarial framework. While one-step methods offer dramatic speed advantages, they typically suffer from quality degradation compared to their multi-step counterparts. Just as a panel of art critics provides comprehensive feedback by specializing in different aspects like composition, color, and technique, our approach maintains a large pool of specialized discriminator heads that collectively guide the generation process. Each discriminator group develops expertise in specific quality aspects at different noise levels, providing diverse feedback that enables high-fidelity one-step generation. Our framework combines: (i) a dynamic discriminator pool with specialized discriminator groups to improve generation quality, (ii) strategic refresh mechanisms to prevent discriminator overfitting, and (iii) global-local discriminator heads for multi-scale quality assessment, and unconditional/conditional training for balanced generation. Additionally, our framework uniquely supports flexible deployment through bottom-up refinement, allowing users to dynamically choose between 1-4 denoising steps with the same model for direct quality-speed trade-offs. Through comprehensive experiments, we demonstrate that NitroFusion significantly outperforms existing single-step methods across multiple evaluation metrics, particularly excelling in preserving fine details and global consistency.
FlipSketch: Flipping Static Drawings to Text-Guided Sketch Animations
Nov 16, 2024Sketch animations offer a powerful medium for visual storytelling, from simple flip-book doodles to professional studio productions. While traditional animation requires teams of skilled artists to draw key frames and in-between frames, existing automation attempts still demand significant artistic effort through precise motion paths or keyframe specification. We present FlipSketch, a system that brings back the magic of flip-book animation -- just draw your idea and describe how you want it to move! Our approach harnesses motion priors from text-to-video diffusion models, adapting them to generate sketch animations through three key innovations: (i) fine-tuning for sketch-style frame generation, (ii) a reference frame mechanism that preserves visual integrity of input sketch through noise refinement, and (iii) a dual-attention composition that enables fluid motion without losing visual consistency. Unlike constrained vector animations, our raster frames support dynamic sketch transformations, capturing the expressive freedom of traditional animation. The result is an intuitive system that makes sketch animation as simple as doodling and describing, while maintaining the artistic essence of hand-drawn animation.
Incremental Open-set Domain Adaptation
Aug 31, 2024
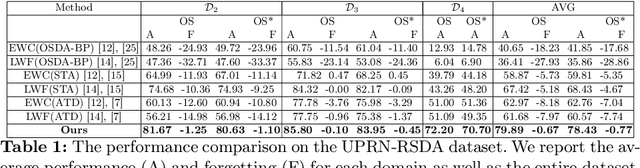
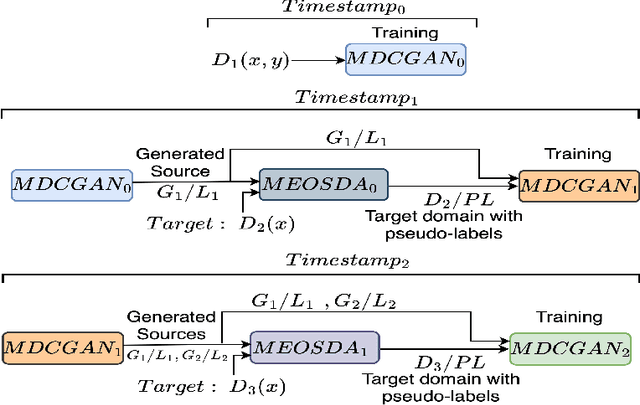
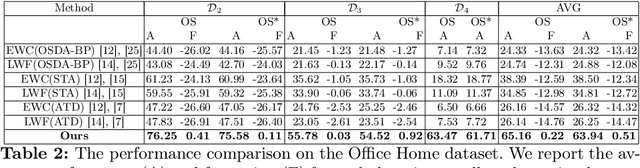
Catastrophic forgetting makes neural network models unstable when learning visual domains consecutively. The neural network model drifts to catastrophic forgetting-induced low performance of previously learnt domains when training with new domains. We illuminate this current neural network model weakness and develop a forgetting-resistant incremental learning strategy. Here, we propose a new unsupervised incremental open-set domain adaptation (IOSDA) issue for image classification. Open-set domain adaptation adds complexity to the incremental domain adaptation issue since each target domain has more classes than the Source domain. In IOSDA, the model learns training with domain streams phase by phase in incremented time. Inference uses test data from all target domains without revealing their identities. We proposed IOSDA-Net, a two-stage learning pipeline, to solve the problem. The first module replicates prior domains from random noise using a generative framework and creates a pseudo source domain. In the second step, this pseudo source is adapted to the present target domain. We test our model on Office-Home, DomainNet, and UPRN-RSDA, a newly curated optical remote sensing dataset.
Do Generalised Classifiers really work on Human Drawn Sketches?
Jul 04, 2024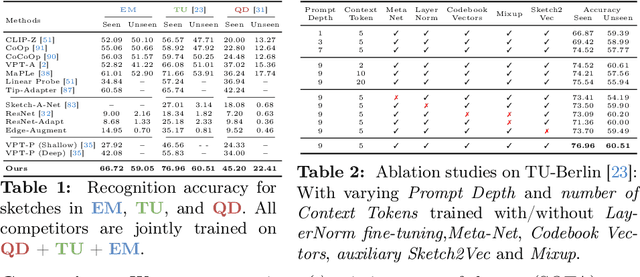
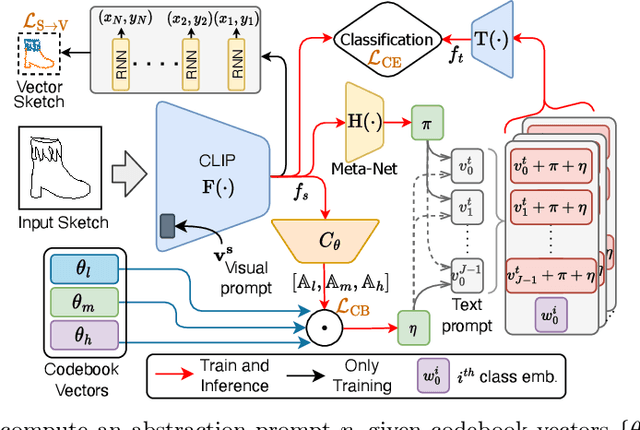
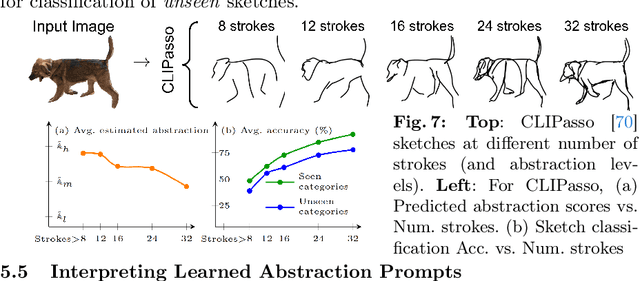
This paper, for the first time, marries large foundation models with human sketch understanding. We demonstrate what this brings -- a paradigm shift in terms of generalised sketch representation learning (e.g., classification). This generalisation happens on two fronts: (i) generalisation across unknown categories (i.e., open-set), and (ii) generalisation traversing abstraction levels (i.e., good and bad sketches), both being timely challenges that remain unsolved in the sketch literature. Our design is intuitive and centred around transferring the already stellar generalisation ability of CLIP to benefit generalised learning for sketches. We first "condition" the vanilla CLIP model by learning sketch-specific prompts using a novel auxiliary head of raster to vector sketch conversion. This importantly makes CLIP "sketch-aware". We then make CLIP acute to the inherently different sketch abstraction levels. This is achieved by learning a codebook of abstraction-specific prompt biases, a weighted combination of which facilitates the representation of sketches across abstraction levels -- low abstract edge-maps, medium abstract sketches in TU-Berlin, and highly abstract doodles in QuickDraw. Our framework surpasses popular sketch representation learning algorithms in both zero-shot and few-shot setups and in novel settings across different abstraction boundaries.
SketchINR: A First Look into Sketches as Implicit Neural Representations
Mar 14, 2024We propose SketchINR, to advance the representation of vector sketches with implicit neural models. A variable length vector sketch is compressed into a latent space of fixed dimension that implicitly encodes the underlying shape as a function of time and strokes. The learned function predicts the $xy$ point coordinates in a sketch at each time and stroke. Despite its simplicity, SketchINR outperforms existing representations at multiple tasks: (i) Encoding an entire sketch dataset into a fixed size latent vector, SketchINR gives $60\times$ and $10\times$ data compression over raster and vector sketches, respectively. (ii) SketchINR's auto-decoder provides a much higher-fidelity representation than other learned vector sketch representations, and is uniquely able to scale to complex vector sketches such as FS-COCO. (iii) SketchINR supports parallelisation that can decode/render $\sim$$100\times$ faster than other learned vector representations such as SketchRNN. (iv) SketchINR, for the first time, emulates the human ability to reproduce a sketch with varying abstraction in terms of number and complexity of strokes. As a first look at implicit sketches, SketchINR's compact high-fidelity representation will support future work in modelling long and complex sketches.
What Sketch Explainability Really Means for Downstream Tasks
Mar 14, 2024



In this paper, we explore the unique modality of sketch for explainability, emphasising the profound impact of human strokes compared to conventional pixel-oriented studies. Beyond explanations of network behavior, we discern the genuine implications of explainability across diverse downstream sketch-related tasks. We propose a lightweight and portable explainability solution -- a seamless plugin that integrates effortlessly with any pre-trained model, eliminating the need for re-training. Demonstrating its adaptability, we present four applications: highly studied retrieval and generation, and completely novel assisted drawing and sketch adversarial attacks. The centrepiece to our solution is a stroke-level attribution map that takes different forms when linked with downstream tasks. By addressing the inherent non-differentiability of rasterisation, we enable explanations at both coarse stroke level (SLA) and partial stroke level (P-SLA), each with its advantages for specific downstream tasks.
Doodle Your 3D: From Abstract Freehand Sketches to Precise 3D Shapes
Dec 07, 2023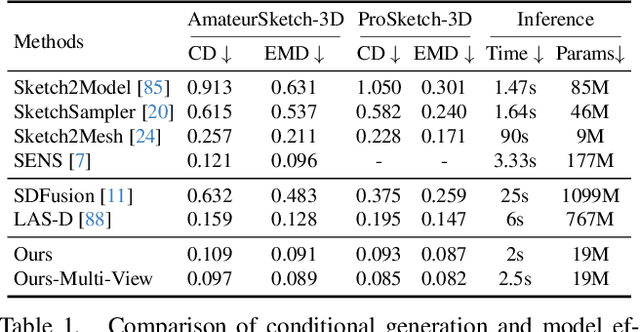
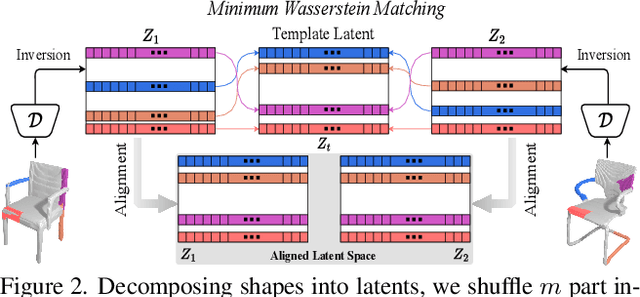
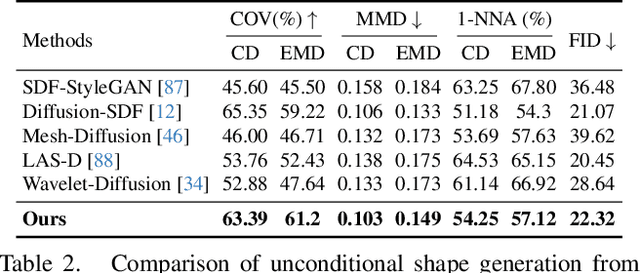
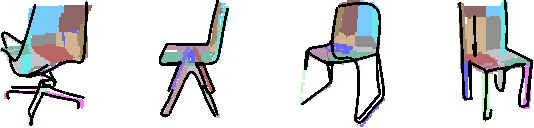
In this paper, we democratise 3D content creation, enabling precise generation of 3D shapes from abstract sketches while overcoming limitations tied to drawing skills. We introduce a novel part-level modelling and alignment framework that facilitates abstraction modelling and cross-modal correspondence. Leveraging the same part-level decoder, our approach seamlessly extends to sketch modelling by establishing correspondence between CLIPasso edgemaps and projected 3D part regions, eliminating the need for a dataset pairing human sketches and 3D shapes. Additionally, our method introduces a seamless in-position editing process as a byproduct of cross-modal part-aligned modelling. Operating in a low-dimensional implicit space, our approach significantly reduces computational demands and processing time.
Cryo-shift: Reducing domain shift in cryo-electron subtomograms with unsupervised domain adaptation and randomization
Nov 17, 2021

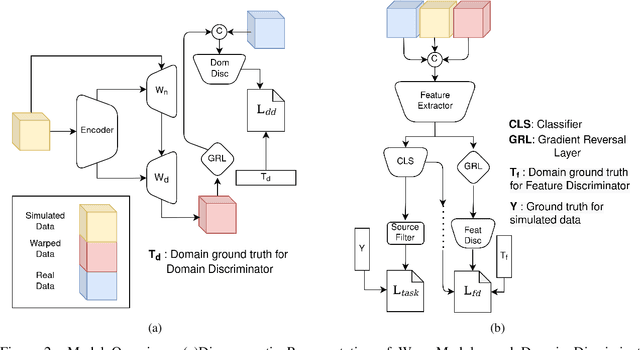

Cryo-Electron Tomography (cryo-ET) is a 3D imaging technology that enables the visualization of subcellular structures in situ at near-atomic resolution. Cellular cryo-ET images help in resolving the structures of macromolecules and determining their spatial relationship in a single cell, which has broad significance in cell and structural biology. Subtomogram classification and recognition constitute a primary step in the systematic recovery of these macromolecular structures. Supervised deep learning methods have been proven to be highly accurate and efficient for subtomogram classification, but suffer from limited applicability due to scarcity of annotated data. While generating simulated data for training supervised models is a potential solution, a sizeable difference in the image intensity distribution in generated data as compared to real experimental data will cause the trained models to perform poorly in predicting classes on real subtomograms. In this work, we present Cryo-Shift, a fully unsupervised domain adaptation and randomization framework for deep learning-based cross-domain subtomogram classification. We use unsupervised multi-adversarial domain adaption to reduce the domain shift between features of simulated and experimental data. We develop a network-driven domain randomization procedure with `warp' modules to alter the simulated data and help the classifier generalize better on experimental data. We do not use any labeled experimental data to train our model, whereas some of the existing alternative approaches require labeled experimental samples for cross-domain classification. Nevertheless, Cryo-Shift outperforms the existing alternative approaches in cross-domain subtomogram classification in extensive evaluation studies demonstrated herein using both simulated and experimental data.
* 14 pages
A distillation based approach for the diagnosis of diseases
Aug 07, 2021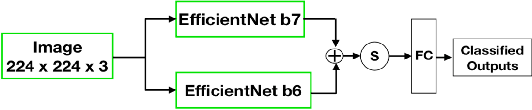
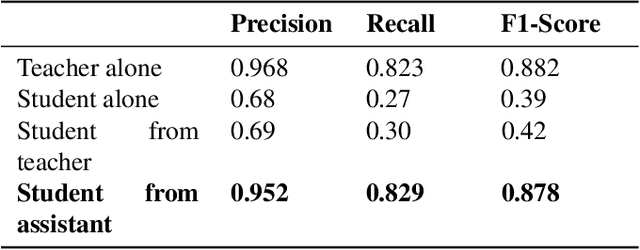
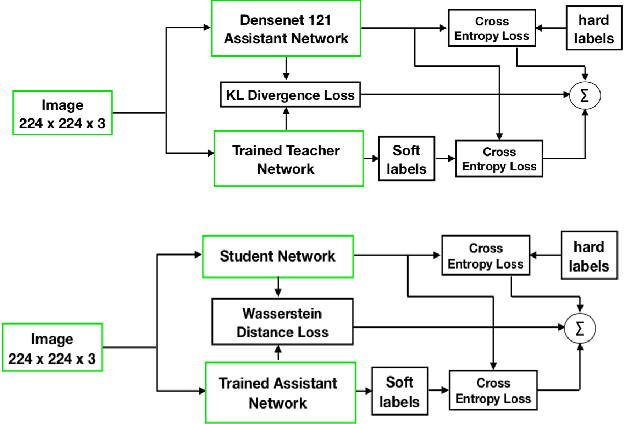
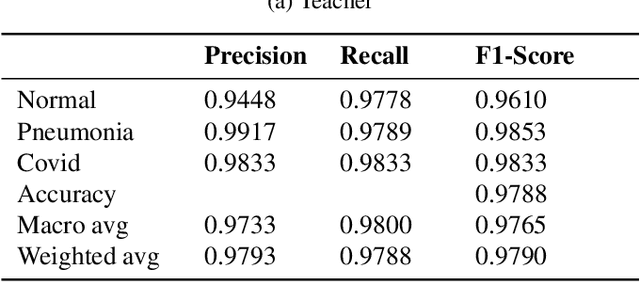
Presently, Covid-19 is a serious threat to the world at large. Efforts are being made to reduce disease screening times and in the development of a vaccine to resist this disease, even as thousands succumb to it everyday. We propose a novel method of automated screening of diseases like Covid-19 and pneumonia from Chest X-Ray images with the help of Computer Vision. Unlike computer vision classification algorithms which come with heavy computational costs, we propose a knowledge distillation based approach which allows us to bring down the model depth, while preserving the accuracy. We make use of an augmentation of the standard distillation module with an auxiliary intermediate assistant network that aids in the continuity of the flow of information. Following this approach, we are able to build an extremely light student network, consisting of just 3 convolutional blocks without any compromise on accuracy. We thus propose a method of classification of diseases which can not only lead to faster screening, but can also operate seamlessly on low-end devices.