 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Attention Guidance: Universal Negative Guidance for Diffusion Model
May 27, 2025Negative guidance -- explicitly suppressing unwanted attributes -- remains a fundamental challenge in diffusion models, particularly in few-step sampling regimes. While Classifier-Free Guidance (CFG) works well in standard settings, it fails under aggressive sampling step compression due to divergent predictions between positive and negative branches. We present Normalized Attention Guidance (NAG), an efficient, training-free mechanism that applies extrapolation in attention space with L1-based normalization and refinement. NAG restores effective negative guidance where CFG collapses while maintaining fidelity. Unlike existing approaches, NAG generalizes across architectures (UNet, DiT), sampling regimes (few-step, multi-step), and modalities (image, video), functioning as a \textit{universal} plug-in with minimal computational overhead. Through extensive experimentation, we demonstrate consistent improvements in text alignment (CLIP Score), fidelity (FID, PFID), and human-perceived quality (ImageReward). Our ablation studies validate each design component, while user studies confirm significant preference for NAG-guided outputs. As a model-agnostic inference-time approach requiring no retraining, NAG provides effortless negative guidance for all modern diffusion frameworks -- pseudocode in the Appendix!
NitroFusion: High-Fidelity Single-Step Diffusion through Dynamic Adversarial Training
Dec 02, 2024We introduce NitroFusion, a fundamentally different approach to single-step diffusion that achieves high-quality generation through a dynamic adversarial framework. While one-step methods offer dramatic speed advantages, they typically suffer from quality degradation compared to their multi-step counterparts. Just as a panel of art critics provides comprehensive feedback by specializing in different aspects like composition, color, and technique, our approach maintains a large pool of specialized discriminator heads that collectively guide the generation process. Each discriminator group develops expertise in specific quality aspects at different noise levels, providing diverse feedback that enables high-fidelity one-step generation. Our framework combines: (i) a dynamic discriminator pool with specialized discriminator groups to improve generation quality, (ii) strategic refresh mechanisms to prevent discriminator overfitting, and (iii) global-local discriminator heads for multi-scale quality assessment, and unconditional/conditional training for balanced generation. Additionally, our framework uniquely supports flexible deployment through bottom-up refinement, allowing users to dynamically choose between 1-4 denoising steps with the same model for direct quality-speed trade-offs. Through comprehensive experiments, we demonstrate that NitroFusion significantly outperforms existing single-step methods across multiple evaluation metrics, particularly excelling in preserving fine details and global consistency.
DemoCaricature: Democratising Caricature Generation with a Rough Sketch
Dec 07, 2023



In this paper, we democratise caricature generation, empowering individuals to effortlessly craft personalised caricatures with just a photo and a conceptual sketch. Our objective is to strike a delicate balance between abstraction and identity, while preserving the creativity and subjectivity inherent in a sketch. To achieve this, we present Explicit Rank-1 Model Editing alongside single-image personalisation, selectively applying nuanced edits to cross-attention layers for a seamless merge of identity and style. Additionally, we propose Random Mask Reconstruction to enhance robustness, directing the model to focus on distinctive identity and style features. Crucially, our aim is not to replace artists but to eliminate accessibility barriers, allowing enthusiasts to engage in the artistry.
ArtAdapter: Text-to-Image Style Transfer using Multi-Level Style Encoder and Explicit Adaptation
Dec 04, 2023This work introduces ArtAdapter, a transformative text-to-image (T2I) style transfer framework that transcends traditional limitations of color, brushstrokes, and object shape, capturing high-level style elements such as composition and distinctive artistic expression. The integration of a multi-level style encoder with our proposed explicit adaptation mechanism enables ArtAdapte to achieve unprecedented fidelity in style transfer, ensuring close alignment with textual descriptions. Additionally, the incorporation of an Auxiliary Content Adapter (ACA) effectively separates content from style, alleviating the borrowing of content from style references. Moreover, our novel fast finetuning approach could further enhance zero-shot style representation while mitigating the risk of overfitting. Comprehensive evaluations confirm that ArtAdapter surpasses current state-of-the-art methods.
ArtFusion: Controllable Arbitrary Style Transfer using Dual Conditional Latent Diffusion Models
Jun 19, 2023Arbitrary Style Transfer (AST) aims to transform images by adopting the style from any selected artwork. Nonetheless, the need to accommodate diverse and subjective user preferences poses a significant challenge. While some users wish to preserve distinct content structures, others might favor a more pronounced stylization. Despite advances in feed-forward AST methods, their limited customizability hinders their practical application. We propose a new approach, ArtFusion, which provides a flexible balance between content and style. In contrast to traditional methods reliant on biased similarity losses, ArtFusion utilizes our innovative Dual Conditional Latent Diffusion Probabilistic Models (Dual-cLDM). This approach mitigates repetitive patterns and enhances subtle artistic aspects like brush strokes and genre-specific features. Despite the promising results of conditional diffusion probabilistic models (cDM) in various generative tasks, their introduction to style transfer is challenging due to the requirement for paired training data. ArtFusion successfully navigates this issue, offering more practical and controllable stylization. A key element of our approach involves using a single image for both content and style during model training, all the while maintaining effective stylization during inference. ArtFusion outperforms existing approaches on outstanding controllability and faithful presentation of artistic details, providing evidence of its superior style transfer capabilities. Furthermore, the Dual-cLDM utilized in ArtFusion carries the potential for a variety of complex multi-condition generative tasks, thus greatly broadening the impact of our research.
Conditional Human Sketch Synthesis with Explicit Abstraction Control
Jun 15, 2023
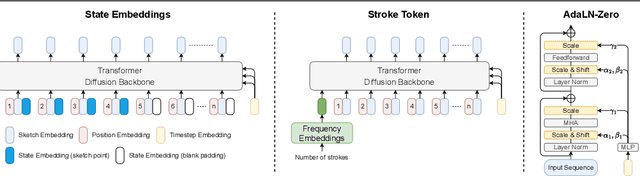

This paper presents a novel free-hand sketch synthesis approach addressing explicit abstraction control in class-conditional and photo-to-sketch synthesis. Abstraction is a vital aspect of sketches, as it defines the fundamental distinction between a sketch and an image. Previous works relied on implicit control to achieve different levels of abstraction, leading to inaccurate control and synthesized sketches deviating from human sketches. To resolve this challenge, we propose two novel abstraction control mechanisms, state embeddings and the stroke token, integrated into a transformer-based latent diffusion model (LDM). These mechanisms explicitly provide the required amount of points or strokes to the model, enabling accurate point-level and stroke-level control in synthesized sketches while preserving recognizability. Outperforming state-of-the-art approaches, our method effectively generates diverse, non-rigid and human-like sketches. The proposed approach enables coherent sketch synthesis and excels in representing human habits with desired abstraction levels, highlighting the potential of sketch synthesis for real-world applications.