 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA distillation based approach for the diagnosis of diseases
Aug 07, 2021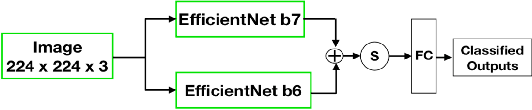
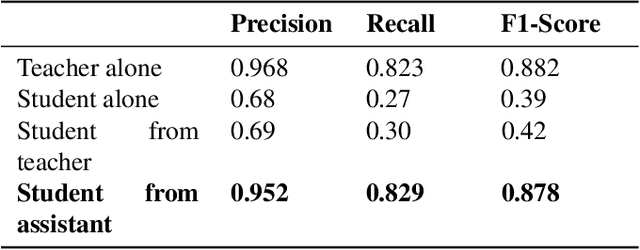
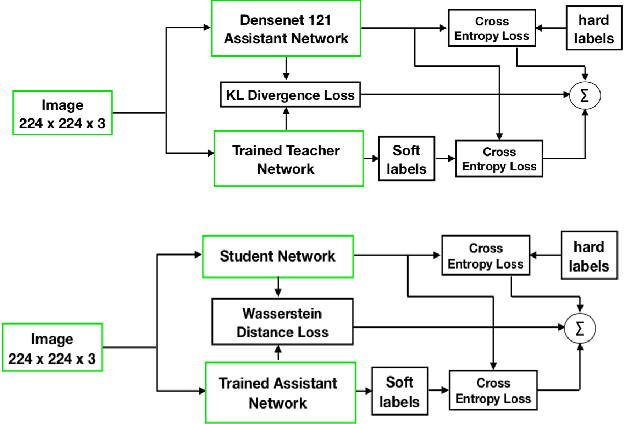
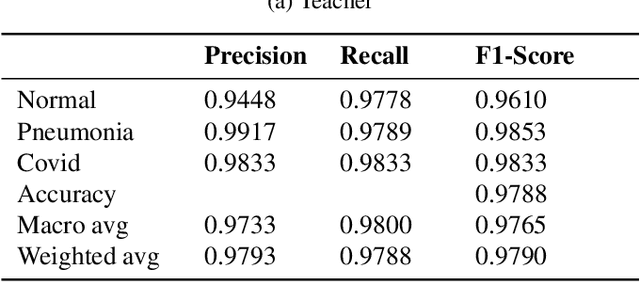
Presently, Covid-19 is a serious threat to the world at large. Efforts are being made to reduce disease screening times and in the development of a vaccine to resist this disease, even as thousands succumb to it everyday. We propose a novel method of automated screening of diseases like Covid-19 and pneumonia from Chest X-Ray images with the help of Computer Vision. Unlike computer vision classification algorithms which come with heavy computational costs, we propose a knowledge distillation based approach which allows us to bring down the model depth, while preserving the accuracy. We make use of an augmentation of the standard distillation module with an auxiliary intermediate assistant network that aids in the continuity of the flow of information. Following this approach, we are able to build an extremely light student network, consisting of just 3 convolutional blocks without any compromise on accuracy. We thus propose a method of classification of diseases which can not only lead to faster screening, but can also operate seamlessly on low-end devices.
Exploring Knowledge Distillation of a Deep Neural Network for Multi-Script identification
Feb 20, 2021
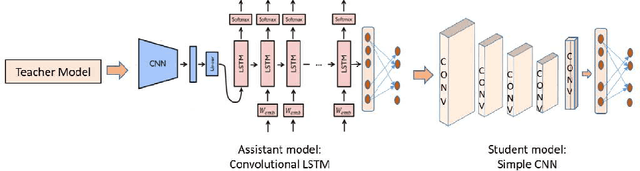
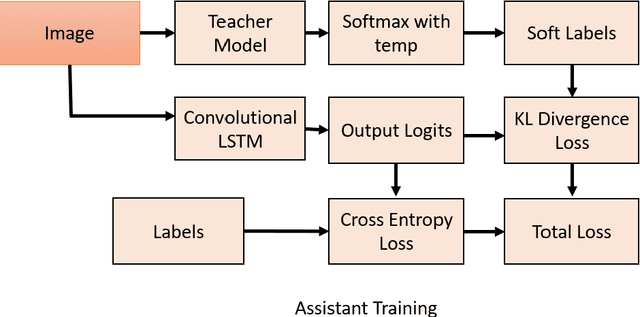

Multi-lingual script identification is a difficult task consisting of different language with complex backgrounds in scene text images. According to the current research scenario, deep neural networks are employed as teacher models to train a smaller student network by utilizing the teacher model's predictions. This process is known as dark knowledge transfer. It has been quite successful in many domains where the final result obtained is unachievable through directly training the student network with a simple architecture. In this paper, we explore dark knowledge transfer approach using long short-term memory(LSTM) and CNN based assistant model and various deep neural networks as the teacher model, with a simple CNN based student network, in this domain of multi-script identification from natural scene text images. We explore the performance of different teacher models and their ability to transfer knowledge to a student network. Although the small student network's limited size, our approach obtains satisfactory results on a well-known script identification dataset CVSI-2015.