 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Knowledge Distillation of a Deep Neural Network for Multi-Script identification
Feb 20, 2021
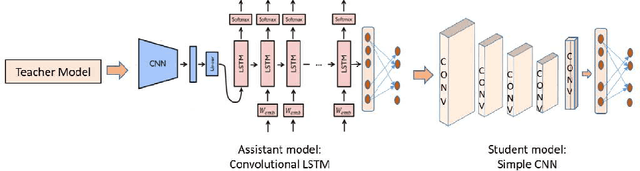
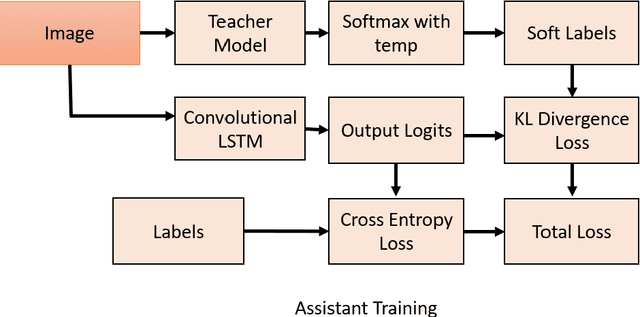

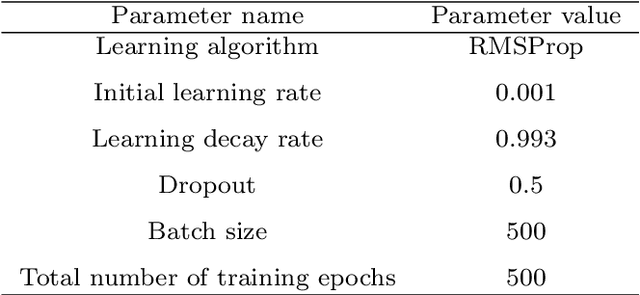
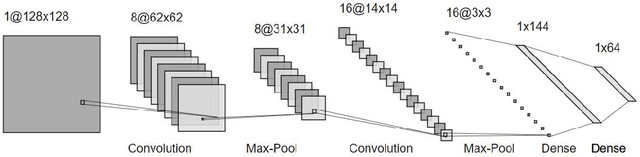
Multi-lingual script identification is a difficult task consisting of different language with complex backgrounds in scene text images. According to the current research scenario, deep neural networks are employed as teacher models to train a smaller student network by utilizing the teacher model's predictions. This process is known as dark knowledge transfer. It has been quite successful in many domains where the final result obtained is unachievable through directly training the student network with a simple architecture. In this paper, we explore dark knowledge transfer approach using long short-term memory(LSTM) and CNN based assistant model and various deep neural networks as the teacher model, with a simple CNN based student network, in this domain of multi-script identification from natural scene text images. We explore the performance of different teacher models and their ability to transfer knowledge to a student network. Although the small student network's limited size, our approach obtains satisfactory results on a well-known script identification dataset CVSI-2015.
A Skip-connected Multi-column Network for Isolated Handwritten Bangla Character and Digit recognition
Apr 27, 2020

Finding local invariant patterns in handwrit-ten characters and/or digits for optical character recognition is a difficult task. Variations in writing styles from one person to another make this task challenging. We have proposed a non-explicit feature extraction method using a multi-scale multi-column skip convolutional neural network in this work. Local and global features extracted from different layers of the proposed architecture are combined to derive the final feature descriptor encoding a character or digit image. Our method is evaluated on four publicly available datasets of isolated handwritten Bangla characters and digits. Exhaustive comparative analysis against contemporary methods establishes the efficacy of our proposed approach.
A Genetic Algorithm based Kernel-size Selection Approach for a Multi-column Convolutional Neural Network
Dec 28, 2019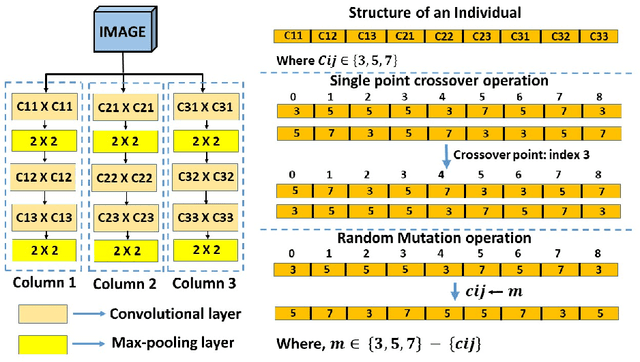
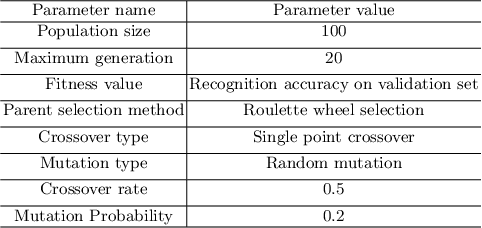
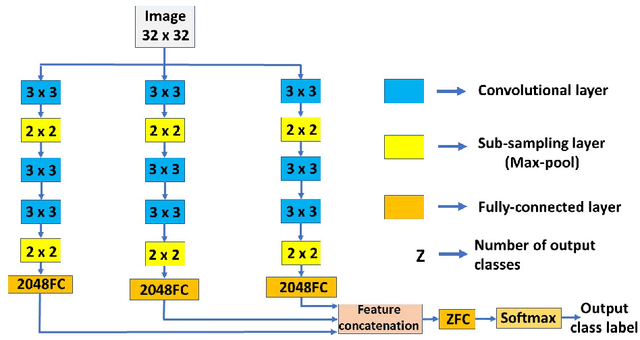
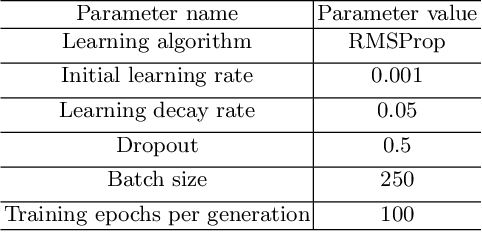
Deep neural network-based architectures give promising results in various domains including \textit{pattern recognition}. Finding the optimal combination of the hyper-parameters of such a large-sized architecture is tedious and requires a large number of laboratory experiments. But, identifying the optimal combination of a hyper-parameter or appropriate kernel size for a given architecture of deep learning is always a challenging and tedious task. Here, we introduced a genetic algorithm-based technique to reduce the efforts of finding the optimal combination of a hyper-parameter (kernel size) of a convolutional neural network-based architecture. The method is evaluated on three popular datasets of different handwritten Bangla characters and digits.
Handwritten Isolated Bangla Compound Character Recognition: a new benchmark using a novel deep learning approach
Feb 02, 2018



In this work, a novel deep learning technique for the recognition of handwritten Bangla isolated compound character is presented and a new benchmark of recognition accuracy on the CMATERdb 3.1.3.3 dataset is reported. Greedy layer wise training of Deep Neural Network has helped to make significant strides in various pattern recognition problems. We employ layerwise training to Deep Convolutional Neural Networks (DCNN) in a supervised fashion and augment the training process with the RMSProp algorithm to achieve faster convergence. We compare results with those obtained from standard shallow learning methods with predefined features, as well as standard DCNNs. Supervised layerwise trained DCNNs are found to outperform standard shallow learning models such as Support Vector Machines as well as regular DCNNs of similar architecture by achieving error rate of 9.67% thereby setting a new benchmark on the CMATERdb 3.1.3.3 with recognition accuracy of 90.33%, representing an improvement of nearly 10%.
An Improved Feature Descriptor for Recognition of Handwritten Bangla Alphabet
Jan 22, 2015
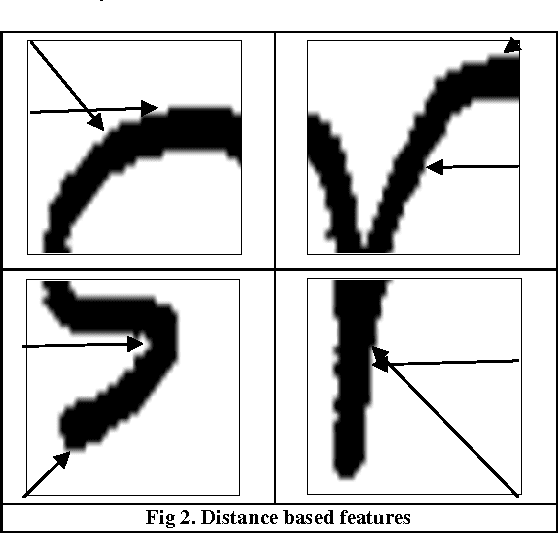
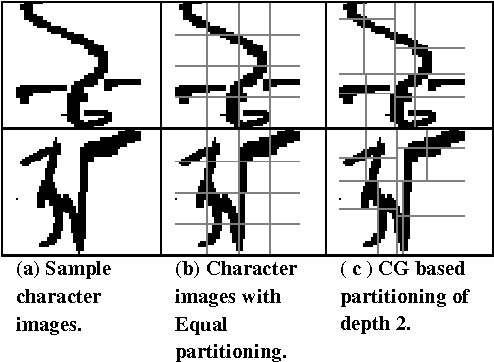
Appropriate feature set for representation of pattern classes is one of the most important aspects of handwritten character recognition. The effectiveness of features depends on the discriminating power of the features chosen to represent patterns of different classes. However, discriminatory features are not easily measurable. Investigative experimentation is necessary for identifying discriminatory features. In the present work we have identified a new variation of feature set which significantly outperforms on handwritten Bangla alphabet from the previously used feature set. 132 number of features in all viz. modified shadow features, octant and centroid features, distance based features, quad tree based longest run features are used here. Using this feature set the recognition performance increases sharply from the 75.05% observed in our previous work [7], to 85.40% on 50 character classes with MLP based classifier on the same dataset.
A GA Based approach for selection of local features for recognition of handwritten Bangla numerals
Jan 22, 2015

Soft computing approaches are mainly designed to address the real world ill-defined, imprecisely formulated problems, combining different kind of novel models of computation, such as neural networks, genetic algorithms (GAs. Handwritten digit recognition is a typical example of one such problem. In the current work we have developed a two-pass approach where the first pass classifier performs a coarse classification, based on some global features of the input pattern by restricting the possibility of classification decisions within a group of classes, smaller than the number of classes considered initially. In the second pass, the group specific classifiers concentrate on the features extracted from the selected local regions, and refine the earlier decision by combining the local and the global features for selecting the true class of the input pattern from the group of candidate classes selected in the first pass. To optimize the selection of local regions a GA based approach has been developed here. The maximum recognition performance on Bangla digit samples as achieved on the test set, during the first pass of the two pass approach is 93.35%. After combining the results of the two stage classifiers, an overall success rate of 95.25% is achieved.
Design of a novel convex hull based feature set for recognition of isolated handwritten Roman numerals
Jan 22, 2015

In this paper, convex hull based features are used for recognition of isolated Roman numerals using a Multi Layer Perceptron (MLP) based classifier. Experiments of convex hull based features for handwritten character recognition are few in numbers. Convex hull of a pattern and the centroid of the convex hull both are affine invariant attributes. In this work, 25 features are extracted based on different bays attributes of the convex hull of the digit patterns. Then these patterns are divided into four sub-images with respect to the centroid of the convex hull boundary. From each such sub-image 25 bays features are also calculated. In all 125 convex hull based features are extracted for each numeric digit patterns under the current experiment. The performance of the designed feature set is tested on the standard MNIST data set, consisting of 60000 training and 10000 test images of handwritten Roman using an MLP based classifier a maximum success rate of 97.44% is achieved on the test data.
A two-pass fuzzy-geno approach to pattern classification
Oct 15, 2014


The work presents an extension of the fuzzy approach to 2-D shape recognition [1] through refinement of initial or coarse classification decisions under a two pass approach. In this approach, an unknown pattern is classified by refining possible classification decisions obtained through coarse classification of the same. To build a fuzzy model of a pattern class horizontal and vertical fuzzy partitions on the sample images of the class are optimized using genetic algorithm. To make coarse classification decisions about an unknown pattern, the fuzzy representation of the pattern is compared with models of all pattern classes through a specially designed similarity measure. Coarse classification decisions are refined in the second pass to obtain the final classification decision of the unknown pattern. To do so, optimized horizontal and vertical fuzzy partitions are again created on certain regions of the image frame, specific to each group of similar type of pattern classes. It is observed through experiments that the technique improves the overall recognition rate from 86.2%, in the first pass, to 90.4% after the second pass, with 500 training samples of handwritten digits.
Recognition of Handwritten Bangla Basic Characters and Digits using Convex Hull based Feature Set
Oct 02, 2014



In dealing with the problem of recognition of handwritten character patterns of varying shapes and sizes, selection of a proper feature set is important to achieve high recognition performance. The current research aims to evaluate the performance of the convex hull based feature set, i.e. 125 features in all computed over different bays attributes of the convex hull of a pattern, for effective recognition of isolated handwritten Bangla basic characters and digits. On experimentation with a database of 10000 samples, the maximum recognition rate of 76.86% is observed for handwritten Bangla characters. For Bangla numerals the maximum success rate of 99.45%. is achieved on a database of 12000 sample. The current work validates the usefulness of a new kind of feature set for recognition of handwritten Bangla basic characters and numerals.
Human Face Recognition using Gabor based Kernel Entropy Component Analysis
Dec 05, 2013
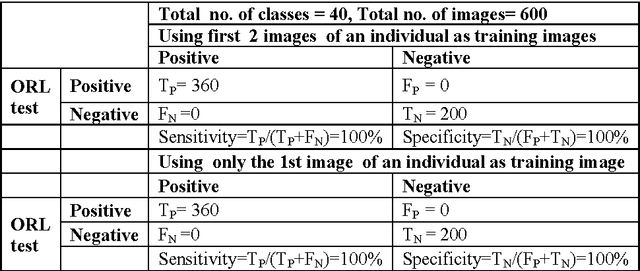
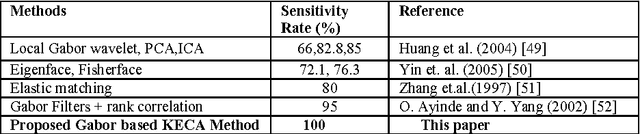
In this paper, we present a novel Gabor wavelet based Kernel Entropy Component Analysis (KECA) method by integrating the Gabor wavelet transformation (GWT) of facial images with the KECA method for enhanced face recognition performance. Firstly, from the Gabor wavelet transformed images the most important discriminative desirable facial features characterized by spatial frequency, spatial locality and orientation selectivity to cope with the variations due to illumination and facial expression changes were derived. After that KECA, relating to the Renyi entropy is extended to include cosine kernel function. The KECA with the cosine kernels is then applied on the extracted most important discriminating feature vectors of facial images to obtain only those real kernel ECA eigenvectors that are associated with eigenvalues having positive entropy contribution. Finally, these real KECA features are used for image classification using the L1, L2 distance measures; the Mahalanobis distance measure and the cosine similarity measure. The feasibility of the Gabor based KECA method with the cosine kernel has been successfully tested on both frontal and pose-angled face recognition, using datasets from the ORL, FRAV2D and the FERET database.