 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNNC: A Visual Analytics System for Comparative Studies of Deep Convolutional Neural Networks
Oct 25, 2021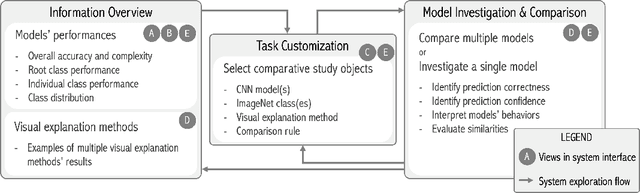
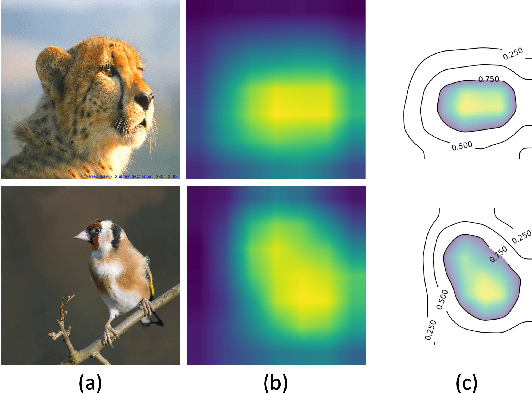

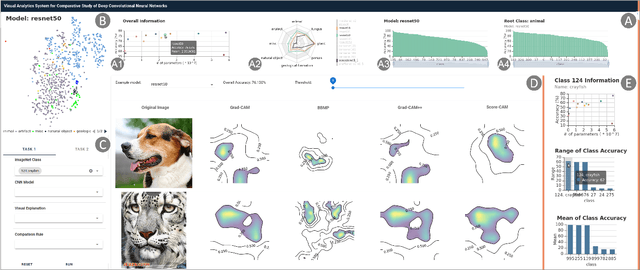
The rapid development of Convolutional Neural Networks (CNNs) in recent years has triggered significant breakthroughs in many machine learning (ML) applications. The ability to understand and compare various CNN models available is thus essential. The conventional approach with visualizing each model's quantitative features, such as classification accuracy and computational complexity, is not sufficient for a deeper understanding and comparison of the behaviors of different models. Moreover, most of the existing tools for assessing CNN behaviors only support comparison between two models and lack the flexibility of customizing the analysis tasks according to user needs. This paper presents a visual analytics system, CNN Comparator (CNNC), that supports the in-depth inspection of a single CNN model as well as comparative studies of two or more models. The ability to compare a larger number of (e.g., tens of) models especially distinguishes our system from previous ones. With a carefully designed model visualization and explaining support, CNNC facilitates a highly interactive workflow that promptly presents both quantitative and qualitative information at each analysis stage. We demonstrate CNNC's effectiveness for assisting ML practitioners in evaluating and comparing multiple CNN models through two use cases and one preliminary evaluation study using the image classification tasks on the ImageNet dataset.
A Deep Generative Model for Matrix Reordering
Oct 11, 2021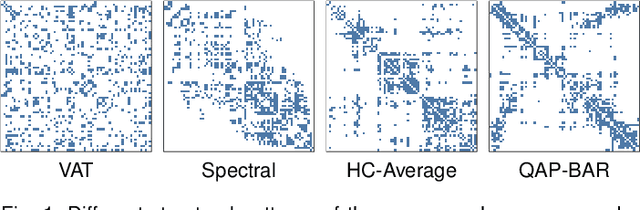
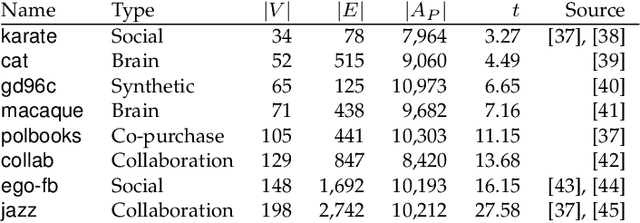
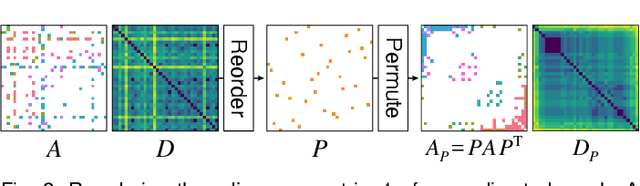

Depending on the node ordering, an adjacency matrix can highlight distinct characteristics of a graph. Deriving a "proper" node ordering is thus a critical step in visualizing a graph as an adjacency matrix. Users often try multiple matrix reorderings using different methods until they find one that meets the analysis goal. However, this trial-and-error approach is laborious and disorganized, which is especially challenging for novices. This paper presents a technique that enables users to effortlessly find a matrix reordering they want. Specifically, we design a generative model that learns a latent space of diverse matrix reorderings of the given graph. We also construct an intuitive user interface from the learned latent space by creating a map of various matrix reorderings. We demonstrate our approach through quantitative and qualitative evaluations of the generated reorderings and learned latent spaces. The results show that our model is capable of learning a latent space of diverse matrix reorderings. Most existing research in this area generally focused on developing algorithms that can compute "better" matrix reorderings for particular circumstances. This paper introduces a fundamentally new approach to matrix visualization of a graph, where a machine learning model learns to generate diverse matrix reorderings of a graph.
Supporting Analysis of Dimensionality Reduction Results with Contrastive Learning
May 10, 2019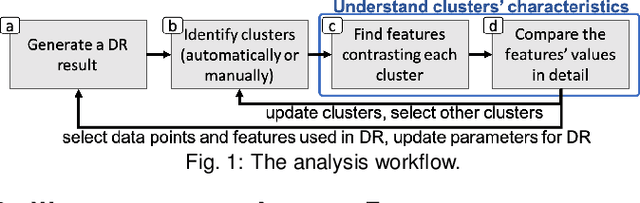
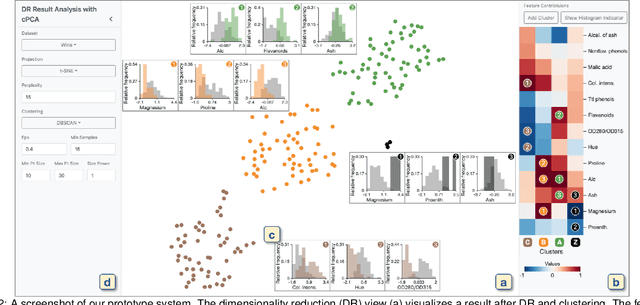
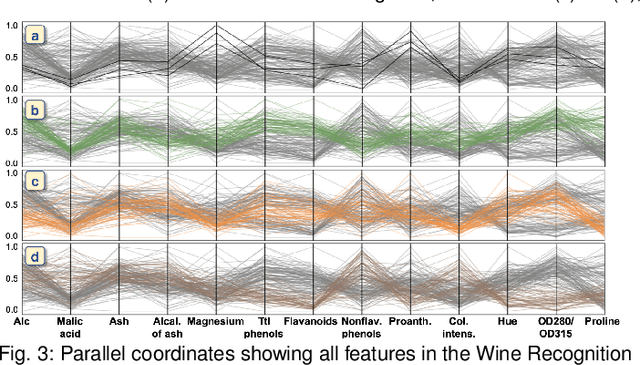
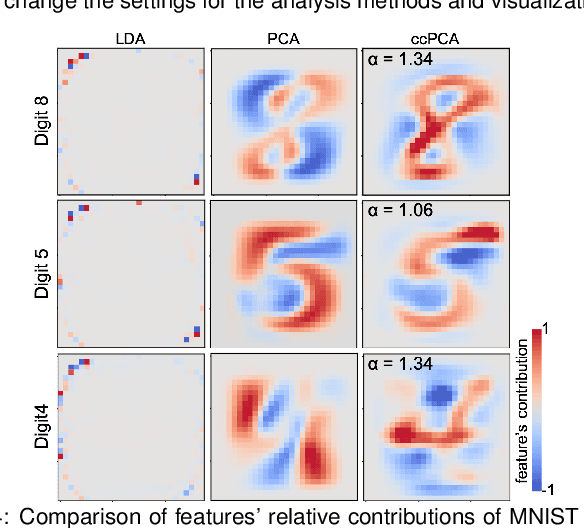
Dimensionality reduction (DR) is frequently used for analyzing and visualizing high-dimensional data as it provides a good first glance of the data. However, to interpret the DR result for gaining useful insights from the data, it would take additional analysis effort such as identifying clusters and understanding their characteristics. While there are many automatic methods (e.g., density-based clustering methods) to identify clusters, effective methods for understanding a cluster's characteristics are still lacking. A cluster can be mostly characterized by its distribution of feature values. Reviewing the original feature values is not a straightforward task when the number of features is large. To address this challenge, we present a visual analytics method that effectively highlights the essential features of a cluster in a DR result. To extract the essential features, we introduce an enhanced usage of contrastive principal component analysis (cPCA). Our method can calculate each feature's relative contribution to the contrast between one cluster and other clusters. With our cPCA-based method, we have created an interactive system including a scalable visualization of clusters' feature contributions. We demonstrate the effectiveness of our method and system with case studies using several publicly available datasets.
A Deep Generative Model for Graph Layout
Apr 27, 2019



As different layouts can characterize different aspects of the same graph, finding a "good" layout of a graph is an important task for graph visualization. In practice, users often visualize a graph in multiple layouts by using different methods and varying parameter settings until they find a layout that best suits the purpose of the visualization. However, this trial-and-error process is often haphazard and time-consuming. To provide users with an intuitive way to navigate the layout design space, we present a technique to systematically visualize a graph in diverse layouts using deep generative models. We design an encoder-decoder architecture to learn a model from a collection of example layouts, where the encoder represents training examples in a latent space and the decoder produces layouts from the latent space. In particular, we train the model to construct a two-dimensional latent space for users to easily explore and generate various layouts. We demonstrate our approach through quantitative and qualitative evaluations of the generated layouts. The results of our evaluations show that our model is capable of learning and generalizing abstract concepts of graph layouts, not just memorizing the training examples. In summary, this paper presents a fundamentally new approach to graph visualization where a machine learning model learns to visualize a graph from examples without manually-defined heuristics.
What Would a Graph Look Like in This Layout? A Machine Learning Approach to Large Graph Visualization
Oct 11, 2017


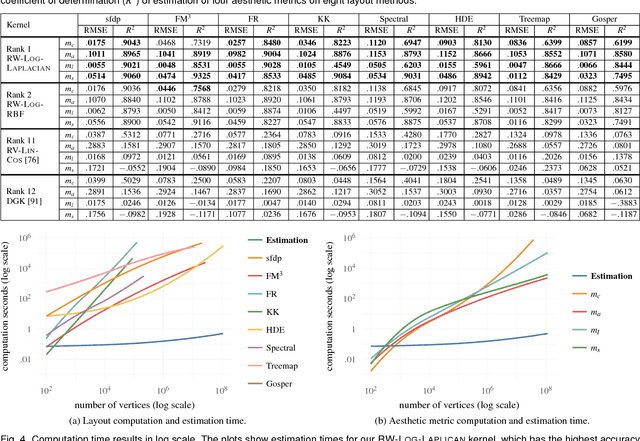
Using different methods for laying out a graph can lead to very different visual appearances, with which the viewer perceives different information. Selecting a "good" layout method is thus important for visualizing a graph. The selection can be highly subjective and dependent on the given task. A common approach to selecting a good layout is to use aesthetic criteria and visual inspection. However, fully calculating various layouts and their associated aesthetic metrics is computationally expensive. In this paper, we present a machine learning approach to large graph visualization based on computing the topological similarity of graphs using graph kernels. For a given graph, our approach can show what the graph would look like in different layouts and estimate their corresponding aesthetic metrics. An important contribution of our work is the development of a new framework to design graph kernels. Our experimental study shows that our estimation calculation is considerably faster than computing the actual layouts and their aesthetic metrics. Also, our graph kernels outperform the state-of-the-art ones in both time and accuracy. In addition, we conducted a user study to demonstrate that the topological similarity computed with our graph kernel matches perceptual similarity assessed by human users.
* Presented at IEEE InfoVis 2017. To appear in IEEE Transactions on Visualization and Computer Graphics