 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUM Parts: Benchmarking Part-Level Semantic Segmentation of Urban Meshes
Mar 21, 2025Semantic segmentation in urban scene analysis has mainly focused on images or point clouds, while textured meshes - offering richer spatial representation - remain underexplored. This paper introduces SUM Parts, the first large-scale dataset for urban textured meshes with part-level semantic labels, covering about 2.5 km2 with 21 classes. The dataset was created using our own annotation tool, which supports both face- and texture-based annotations with efficient interactive selection. We also provide a comprehensive evaluation of 3D semantic segmentation and interactive annotation methods on this dataset. Our project page is available at https://tudelft3d.github.io/SUMParts/.
Building-PCC: Building Point Cloud Completion Benchmarks
Apr 24, 2024With the rapid advancement of 3D sensing technologies, obtaining 3D shape information of objects has become increasingly convenient. Lidar technology, with its capability to accurately capture the 3D information of objects at long distances, has been widely applied in the collection of 3D data in urban scenes. However, the collected point cloud data often exhibit incompleteness due to factors such as occlusion, signal absorption, and specular reflection. This paper explores the application of point cloud completion technologies in processing these incomplete data and establishes a new real-world benchmark Building-PCC dataset, to evaluate the performance of existing deep learning methods in the task of urban building point cloud completion. Through a comprehensive evaluation of different methods, we analyze the key challenges faced in building point cloud completion, aiming to promote innovation in the field of 3D geoinformation applications. Our source code is available at https://github.com/tudelft3d/Building-PCC-Building-Point-Cloud-Completion-Benchmarks.git.
Unsupervised Roofline Extraction from True Orthophotos for LoD2 Building Model Reconstruction
Oct 02, 2023This paper discusses the reconstruction of LoD2 building models from 2D and 3D data for large-scale urban environments. Traditional methods involve the use of LiDAR point clouds, but due to high costs and long intervals associated with acquiring such data for rapidly developing areas, researchers have started exploring the use of point clouds generated from (oblique) aerial images. However, using such point clouds for traditional plane detection-based methods can result in significant errors and introduce noise into the reconstructed building models. To address this, this paper presents a method for extracting rooflines from true orthophotos using line detection for the reconstruction of building models at the LoD2 level. The approach is able to extract relatively complete rooflines without the need for pre-labeled training data or pre-trained models. These lines can directly be used in the LoD2 building model reconstruction process. The method is superior to existing plane detection-based methods and state-of-the-art deep learning methods in terms of the accuracy and completeness of the reconstructed building. Our source code is available at https://github.com/tudelft3d/Roofline-extraction-from-orthophotos.
PSSNet: Planarity-sensible Semantic Segmentation of Large-scale Urban Meshes
Feb 09, 2022

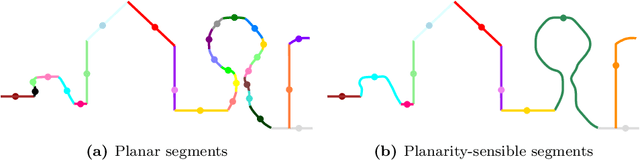
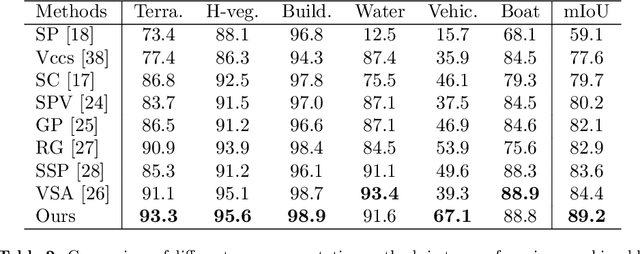
We introduce a novel deep learning-based framework to interpret 3D urban scenes represented as textured meshes. Based on the observation that object boundaries typically align with the boundaries of planar regions, our framework achieves semantic segmentation in two steps: planarity-sensible over-segmentation followed by semantic classification. The over-segmentation step generates an initial set of mesh segments that capture the planar and non-planar regions of urban scenes. In the subsequent classification step, we construct a graph that encodes geometric and photometric features of the segments in its nodes and multi-scale contextual features in its edges. The final semantic segmentation is obtained by classifying the segments using a graph convolutional network. Experiments and comparisons on a large semantic urban mesh benchmark demonstrate that our approach outperforms the state-of-the-art methods in terms of boundary quality and mean IoU (intersection over union). Besides, we also introduce several new metrics for evaluating mesh over-segmentation methods dedicated for semantic segmentation, and our proposed over-segmentation approach outperforms state-of-the-art methods on all metrics. Our source code will be released when the paper is accepted.
SUM: A Benchmark Dataset of Semantic Urban Meshes
Feb 27, 2021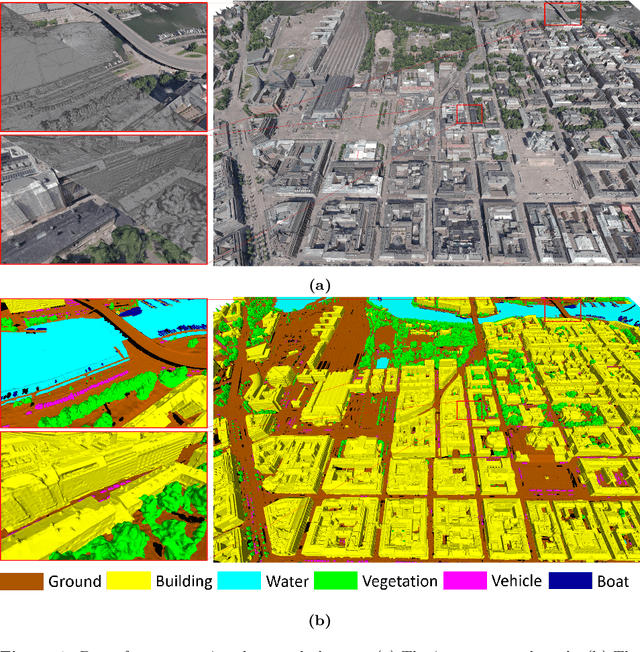
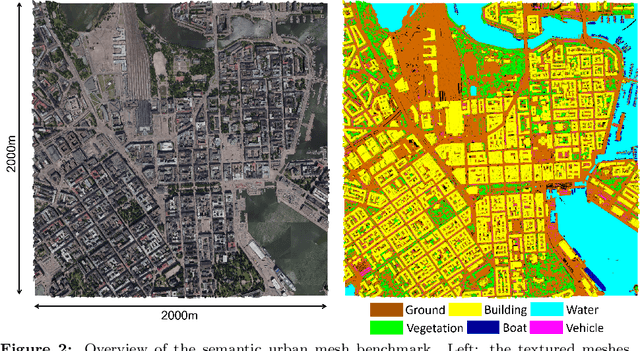
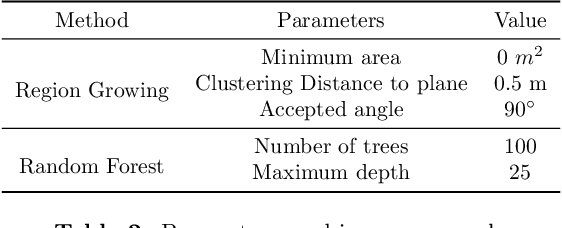
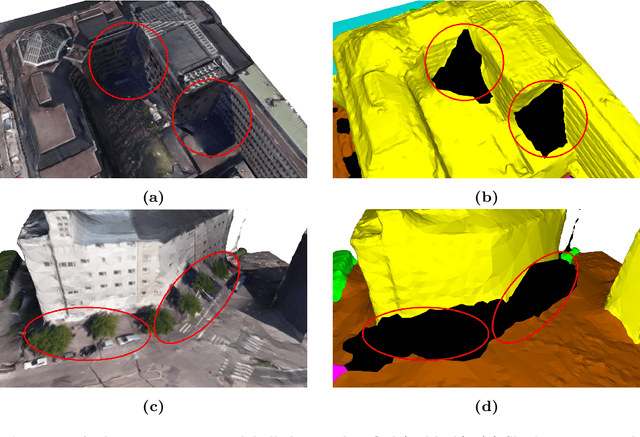
Recent developments in data acquisition technology allow us to collect 3D texture meshes quickly. Those can help us understand and analyse the urban environment, and as a consequence are useful for several applications like spatial analysis and urban planning. Semantic segmentation of texture meshes through deep learning methods can enhance this understanding, but it requires a lot of labelled data. This paper introduces a new benchmark dataset of semantic urban meshes, a novel semi-automatic annotation framework, and an open-source annotation tool for 3D meshes. In particular, our dataset covers about 4 km2 in Helsinki (Finland), with six classes, and we estimate that we save about 600 hours of labelling work using our annotation framework, which includes initial segmentation and interactive refinement. Furthermore, we compare the performance of several representative 3D semantic segmentation methods on our annotated dataset. The results show our initial segmentation outperforms other methods and achieves an overall accuracy of 93.0% and mIoU of 66.2% with less training time compared to other deep learning methods. We also evaluate the effect of the input training data, which shows that our method only requires about 7% (which covers about 0.23 km2) to approach robust and adequate results whereas KPConv needs at least 33% (which covers about 1.0 km2).