 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Video Transformers for Action Understanding with VLM-aided Training
Mar 24, 2024
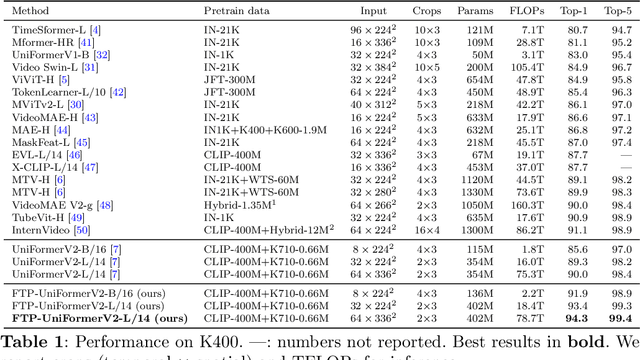

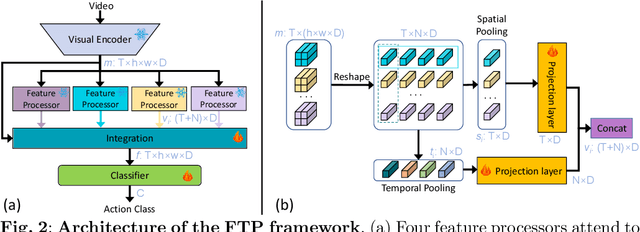
Owing to their ability to extract relevant spatio-temporal video embeddings, Vision Transformers (ViTs) are currently the best performing models in video action understanding. However, their generalization over domains or datasets is somewhat limited. In contrast, Visual Language Models (VLMs) have demonstrated exceptional generalization performance, but are currently unable to process videos. Consequently, they cannot extract spatio-temporal patterns that are crucial for action understanding. In this paper, we propose the Four-tiered Prompts (FTP) framework that takes advantage of the complementary strengths of ViTs and VLMs. We retain ViTs' strong spatio-temporal representation ability but improve the visual encodings to be more comprehensive and general by aligning them with VLM outputs. The FTP framework adds four feature processors that focus on specific aspects of human action in videos: action category, action components, action description, and context information. The VLMs are only employed during training, and inference incurs a minimal computation cost. Our approach consistently yields state-of-the-art performance. For instance, we achieve remarkable top-1 accuracy of 93.8% on Kinetics-400 and 83.4% on Something-Something V2, surpassing VideoMAEv2 by 2.8% and 2.6%, respectively.