 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBundleMoCap: Efficient, Robust and Smooth Motion Capture from Sparse Multiview Videos
Nov 21, 2023



Capturing smooth motions from videos using markerless techniques typically involves complex processes such as temporal constraints, multiple stages with data-driven regression and optimization, and bundle solving over temporal windows. These processes can be inefficient and require tuning multiple objectives across stages. In contrast, BundleMoCap introduces a novel and efficient approach to this problem. It solves the motion capture task in a single stage, eliminating the need for temporal smoothness objectives while still delivering smooth motions. BundleMoCap outperforms the state-of-the-art without increasing complexity. The key concept behind BundleMoCap is manifold interpolation between latent keyframes. By relying on a local manifold smoothness assumption, we can efficiently solve a bundle of frames using a single code. Additionally, the method can be implemented as a sliding window optimization and requires only the first frame to be properly initialized, reducing the overall computational burden. BundleMoCap's strength lies in its ability to achieve high-quality motion capture results with simplicity and efficiency. More details can be found at https://moverseai.github.io/bundle/.
Noise-in, Bias-out: Balanced and Real-time MoCap Solving
Sep 25, 2023



Real-time optical Motion Capture (MoCap) systems have not benefited from the advances in modern data-driven modeling. In this work we apply machine learning to solve noisy unstructured marker estimates in real-time and deliver robust marker-based MoCap even when using sparse affordable sensors. To achieve this we focus on a number of challenges related to model training, namely the sourcing of training data and their long-tailed distribution. Leveraging representation learning we design a technique for imbalanced regression that requires no additional data or labels and improves the performance of our model in rare and challenging poses. By relying on a unified representation, we show that training such a model is not bound to high-end MoCap training data acquisition, and exploit the advances in marker-less MoCap to acquire the necessary data. Finally, we take a step towards richer and affordable MoCap by adapting a body model-based inverse kinematics solution to account for measurement and inference uncertainty, further improving performance and robustness. Project page: https://moverseai.github.io/noise-tail
Hybrid Skip: A Biologically Inspired Skip Connection for the UNet Architecture
Jul 11, 2022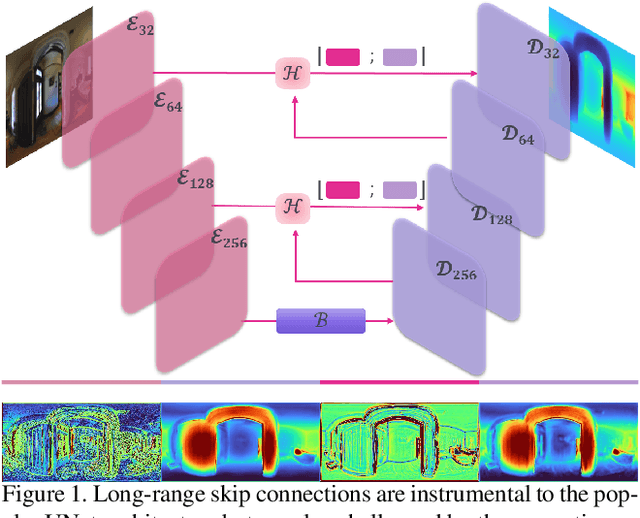

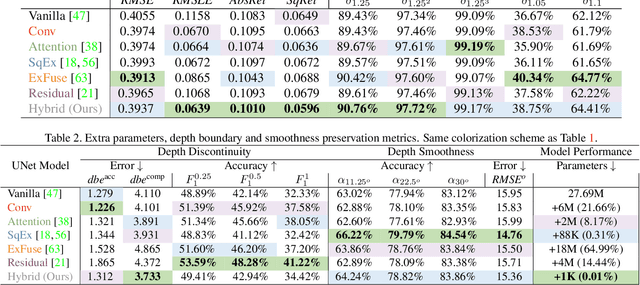
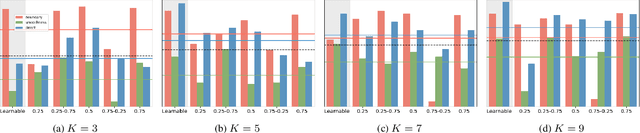
In this work we introduce a biologically inspired long-range skip connection for the UNet architecture that relies on the perceptual illusion of hybrid images, being images that simultaneously encode two images. The fusion of early encoder features with deeper decoder ones allows UNet models to produce finer-grained dense predictions. While proven in segmentation tasks, the network's benefits are down-weighted for dense regression tasks as these long-range skip connections additionally result in texture transfer artifacts. Specifically for depth estimation, this hurts smoothness and introduces false positive edges which are detrimental to the task due to the depth maps' piece-wise smooth nature. The proposed HybridSkip connections show improved performance in balancing the trade-off between edge preservation, and the minimization of texture transfer artifacts that hurt smoothness. This is achieved by the proper and balanced exchange of information that Hybrid-Skip connections offer between the high and low frequency, encoder and decoder features, respectively.
* Project page at https://vcl3d.github.io/HybridSkip/
A benchmark with decomposed distribution shifts for 360 monocular depth estimation
Dec 01, 2021



In this work we contribute a distribution shift benchmark for a computer vision task; monocular depth estimation. Our differentiation is the decomposition of the wider distribution shift of uncontrolled testing on in-the-wild data, to three distinct distribution shifts. Specifically, we generate data via synthesis and analyze them to produce covariate (color input), prior (depth output) and concept (their relationship) distribution shifts. We also synthesize combinations and show how each one is indeed a different challenge to address, as stacking them produces increased performance drops and cannot be addressed horizontally using standard approaches.
Pano3D: A Holistic Benchmark and a Solid Baseline for $360^o$ Depth Estimation
Sep 06, 2021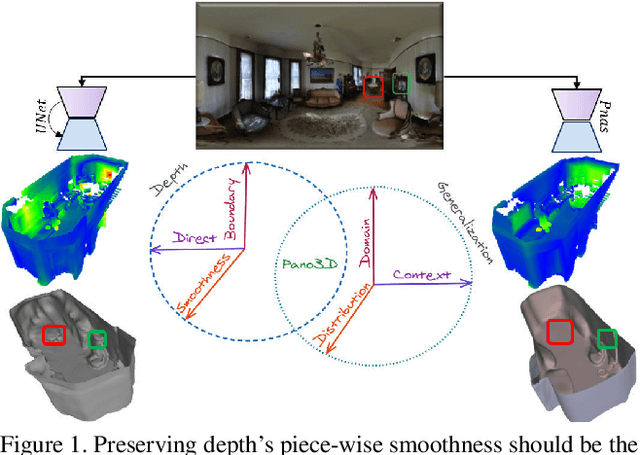
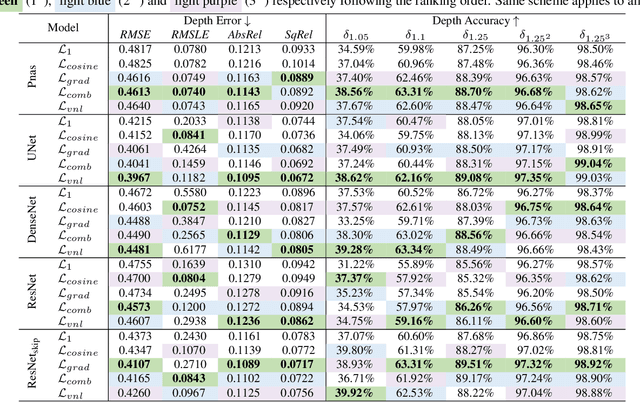

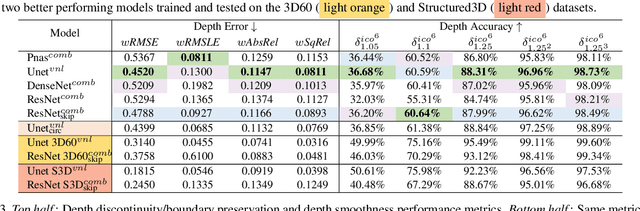
Pano3D is a new benchmark for depth estimation from spherical panoramas. It aims to assess performance across all depth estimation traits, the primary direct depth estimation performance targeting precision and accuracy, and also the secondary traits, boundary preservation, and smoothness. Moreover, Pano3D moves beyond typical intra-dataset evaluation to inter-dataset performance assessment. By disentangling the capacity to generalize to unseen data into different test splits, Pano3D represents a holistic benchmark for $360^o$ depth estimation. We use it as a basis for an extended analysis seeking to offer insights into classical choices for depth estimation. This results in a solid baseline for panoramic depth that follow-up works can build upon to steer future progress.
SHREC 2020 track: 6D Object Pose Estimation
Oct 19, 2020
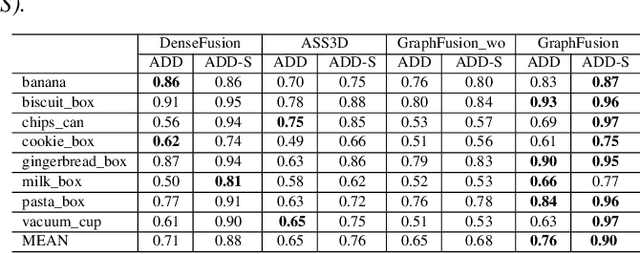
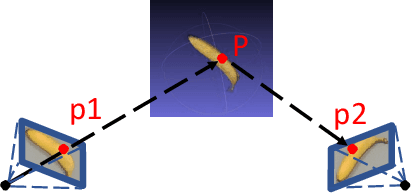
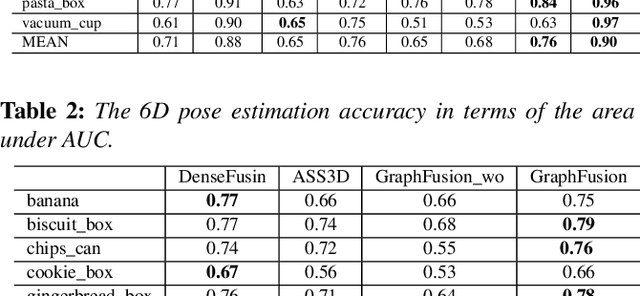
6D pose estimation is crucial for augmented reality, virtual reality, robotic manipulation and visual navigation. However, the problem is challenging due to the variety of objects in the real world. They have varying 3D shape and their appearances in captured images are affected by sensor noise, changing lighting conditions and occlusions between objects. Different pose estimation methods have different strengths and weaknesses, depending on feature representations and scene contents. At the same time, existing 3D datasets that are used for data-driven methods to estimate 6D poses have limited view angles and low resolution. To address these issues, we organize the Shape Retrieval Challenge benchmark on 6D pose estimation and create a physically accurate simulator that is able to generate photo-realistic color-and-depth image pairs with corresponding ground truth 6D poses. From captured color and depth images, we use this simulator to generate a 3D dataset which has 400 photo-realistic synthesized color-and-depth image pairs with various view angles for training, and another 100 captured and synthetic images for testing. Five research groups register in this track and two of them submitted their results. Data-driven methods are the current trend in 6D object pose estimation and our evaluation results show that approaches which fully exploit the color and geometric features are more robust for 6D pose estimation of reflective and texture-less objects and occlusion. This benchmark and comparative evaluation results have the potential to further enrich and boost the research of 6D object pose estimation and its applications.
DronePose: Photorealistic UAV-Assistant Dataset Synthesis for 3D Pose Estimation via a Smooth Silhouette Loss
Aug 21, 2020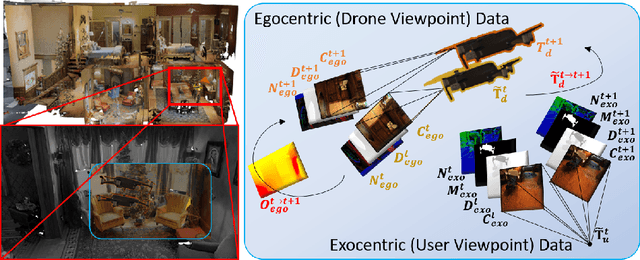
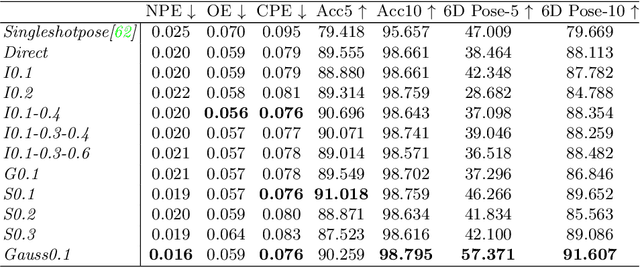


In this work we consider UAVs as cooperative agents supporting human users in their operations. In this context, the 3D localisation of the UAV assistant is an important task that can facilitate the exchange of spatial information between the user and the UAV. To address this in a data-driven manner, we design a data synthesis pipeline to create a realistic multimodal dataset that includes both the exocentric user view, and the egocentric UAV view. We then exploit the joint availability of photorealistic and synthesized inputs to train a single-shot monocular pose estimation model. During training we leverage differentiable rendering to supplement a state-of-the-art direct regression objective with a novel smooth silhouette loss. Our results demonstrate its qualitative and quantitative performance gains over traditional silhouette objectives. Our data and code are available at https://vcl3d.github.io/DronePose