 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Representation Learning Approach to Feature Drift Detection in Wireless Networks
May 15, 2025AI is foreseen to be a centerpiece in next generation wireless networks enabling enabling ubiquitous communication as well as new services. However, in real deployment, feature distribution changes may degrade the performance of AI models and lead to undesired behaviors. To counter for undetected model degradation, we propose ALERT; a method that can detect feature distribution changes and trigger model re-training that works well on two wireless network use cases: wireless fingerprinting and link anomaly detection. ALERT includes three components: representation learning, statistical testing and utility assessment. We rely on MLP for designing the representation learning component, on Kolmogorov-Smirnov and Population Stability Index tests for designing the statistical testing and a new function for utility assessment. We show the superiority of the proposed method against ten standard drift detection methods available in the literature on two wireless network use cases.
An Ensemble Scheme for Proactive Dominant Data Migration of Pervasive Tasks at the Edge
Oct 12, 2024Nowadays, a significant focus within the research community on the intelligent management of data at the confluence of the Internet of Things (IoT) and Edge Computing (EC) is observed. In this manuscript, we propose a scheme to be implemented by autonomous edge nodes concerning their identifications of the appropriate data to be migrated to particular locations within the infrastructure, thereby facilitating the effective processing of requests. Our objective is to equip nodes with the capability to comprehend the access patterns relating to offloaded data-driven tasks and to predict which data ought to be returned to the original nodes associated with those tasks. It is evident that these tasks depend on the processing of data that is absent from the original hosting nodes, thereby underscoring the essential data assets that necessitate access. To infer these data intervals, we utilize an ensemble approach that integrates a statistically oriented model and a machine learning framework. As a result, we are able to identify the dominant data assets in addition to detecting the density of the requests. A detailed analysis of the suggested method is provided by presenting the related formulations, which is also assessed and compared with models found in the relevant literature.
BundleMoCap: Efficient, Robust and Smooth Motion Capture from Sparse Multiview Videos
Nov 21, 2023



Capturing smooth motions from videos using markerless techniques typically involves complex processes such as temporal constraints, multiple stages with data-driven regression and optimization, and bundle solving over temporal windows. These processes can be inefficient and require tuning multiple objectives across stages. In contrast, BundleMoCap introduces a novel and efficient approach to this problem. It solves the motion capture task in a single stage, eliminating the need for temporal smoothness objectives while still delivering smooth motions. BundleMoCap outperforms the state-of-the-art without increasing complexity. The key concept behind BundleMoCap is manifold interpolation between latent keyframes. By relying on a local manifold smoothness assumption, we can efficiently solve a bundle of frames using a single code. Additionally, the method can be implemented as a sliding window optimization and requires only the first frame to be properly initialized, reducing the overall computational burden. BundleMoCap's strength lies in its ability to achieve high-quality motion capture results with simplicity and efficiency. More details can be found at https://moverseai.github.io/bundle/.
Noise-in, Bias-out: Balanced and Real-time MoCap Solving
Sep 25, 2023



Real-time optical Motion Capture (MoCap) systems have not benefited from the advances in modern data-driven modeling. In this work we apply machine learning to solve noisy unstructured marker estimates in real-time and deliver robust marker-based MoCap even when using sparse affordable sensors. To achieve this we focus on a number of challenges related to model training, namely the sourcing of training data and their long-tailed distribution. Leveraging representation learning we design a technique for imbalanced regression that requires no additional data or labels and improves the performance of our model in rare and challenging poses. By relying on a unified representation, we show that training such a model is not bound to high-end MoCap training data acquisition, and exploit the advances in marker-less MoCap to acquire the necessary data. Finally, we take a step towards richer and affordable MoCap by adapting a body model-based inverse kinematics solution to account for measurement and inference uncertainty, further improving performance and robustness. Project page: https://moverseai.github.io/noise-tail
Monitoring and Proactive Management of QoS Levels in Pervasive Applications
Jun 11, 2022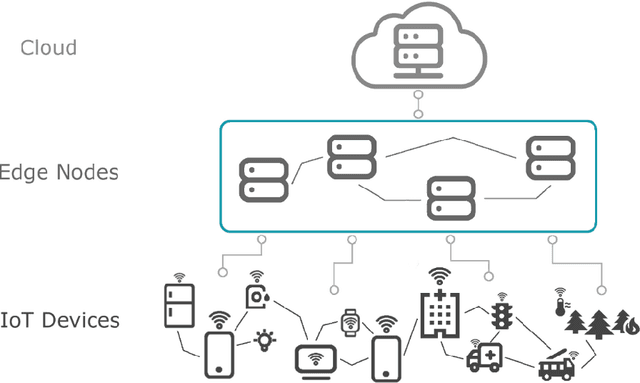
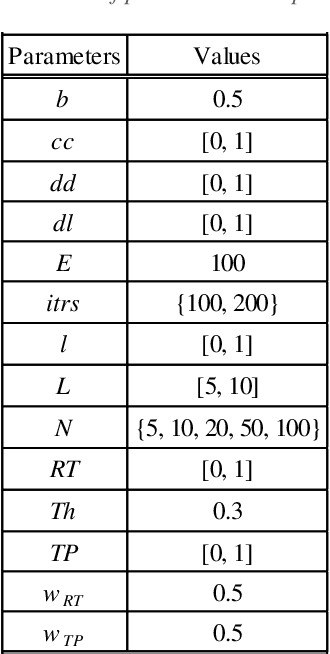
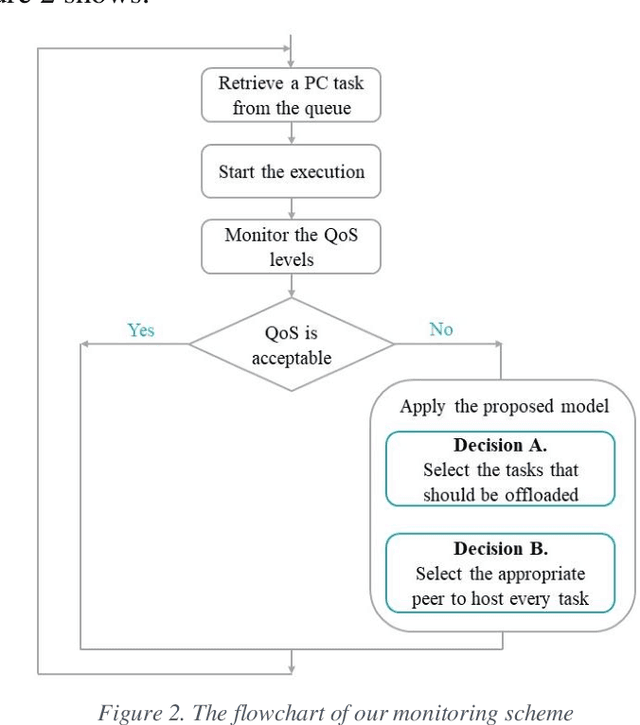
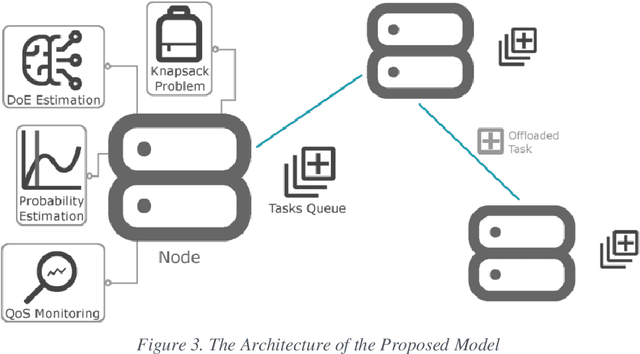
The advent of Edge Computing (EC) as a promising paradigm that provides multiple computation and analytics capabilities close to data sources opens new pathways for novel applications. Nonetheless, the limited computational capabilities of EC nodes and the expectation of ensuring high levels of QoS during tasks execution impose strict requirements for innovative management approaches. Motivated by the need of maintaining a minimum level of QoS during EC nodes functioning, we elaborate a distributed and intelligent decision-making approach for tasks scheduling. Our aim is to enhance the behavior of EC nodes making them capable of securing high QoS levels. We propose that nodes continuously monitor QoS levels and systematically evaluate the probability of violating them to proactively decide some tasks to be offloaded to peer nodes or Cloud. We present, describe and evaluate the proposed scheme through multiple experimental scenarios revealing its performance and the benefits of the envisioned monitoring mechanism when serving processing requests in very dynamic environments like the EC.
A Proactive Management Scheme for Data Synopses at the Edge
Jul 22, 2021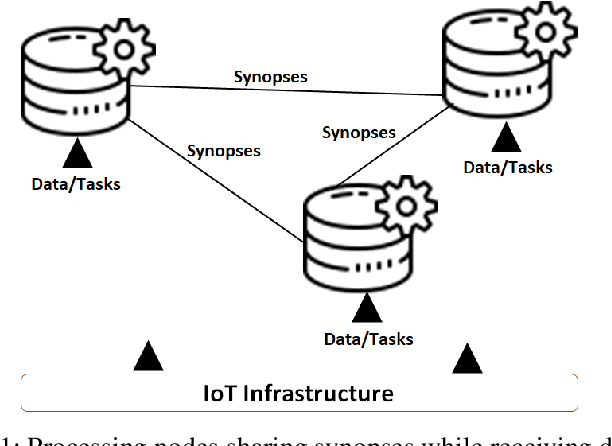
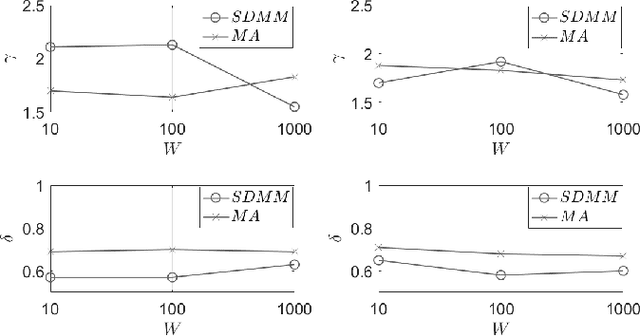
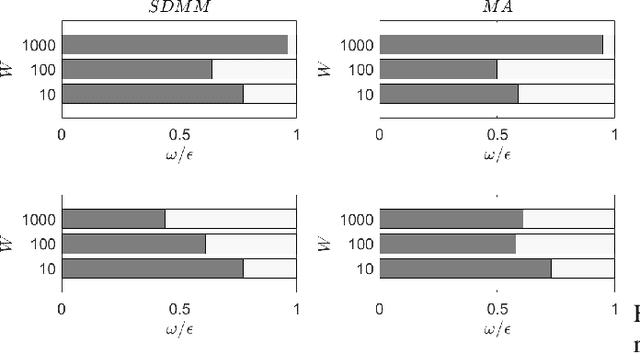
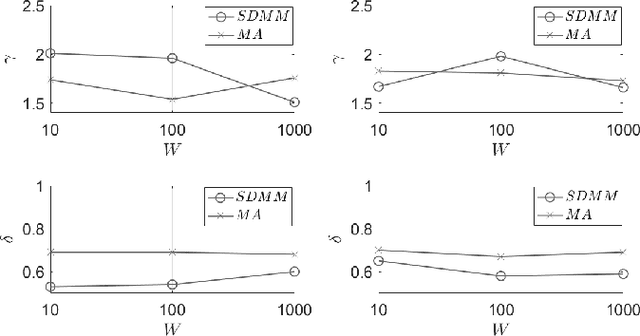
The combination of the infrastructure provided by the Internet of Things (IoT) with numerous processing nodes present at the Edge Computing (EC) ecosystem opens up new pathways to support intelligent applications. Such applications can be provided upon humongous volumes of data collected by IoT devices being transferred to the edge nodes through the network. Various processing activities can be performed on the discussed data and multiple collaborative opportunities between EC nodes can facilitate the execution of the desired tasks. In order to support an effective interaction between edge nodes, the knowledge about the geographically distributed data should be shared. Obviously, the migration of large amounts of data will harm the stability of the network stability and its performance. In this paper, we recommend the exchange of data synopses than real data between EC nodes to provide them with the necessary knowledge about peer nodes owning similar data. This knowledge can be valuable when considering decisions such as data/service migration and tasks offloading. We describe an continuous reasoning model that builds a temporal similarity map of the available datasets to get nodes understanding the evolution of data in their peers. We support the proposed decision making mechanism through an intelligent similarity extraction scheme based on an unsupervised machine learning model, and, at the same time, combine it with a statistical measure that represents the trend of the so-called discrepancy quantum. Our model can reveal the differences in the exchanged synopses and provide a datasets similarity map which becomes the appropriate knowledge base to support the desired processing activities. We present the problem under consideration and suggest a solution for that, while, at the same time, we reveal its advantages and disadvantages through a large number of experiments.
An Intelligent Edge-Centric Queries Allocation Scheme based on Ensemble Models
Aug 12, 2020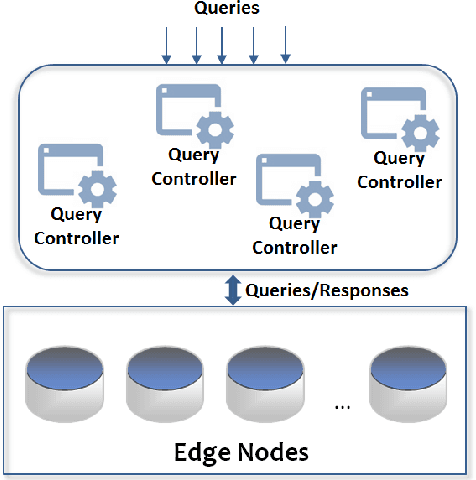
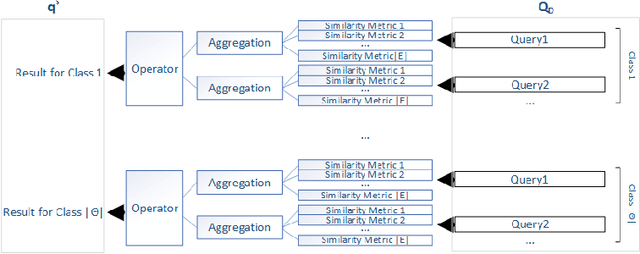
The combination of Internet of Things (IoT) and Edge Computing (EC) can assist in the delivery of novel applications that will facilitate end users activities. Data collected by numerous devices present in the IoT infrastructure can be hosted into a set of EC nodes becoming the subject of processing tasks for the provision of analytics. Analytics are derived as the result of various queries defined by end users or applications. Such queries can be executed in the available EC nodes to limit the latency in the provision of responses. In this paper, we propose a meta-ensemble learning scheme that supports the decision making for the allocation of queries to the appropriate EC nodes. Our learning model decides over queries' and nodes' characteristics. We provide the description of a matching process between queries and nodes after concluding the contextual information for each envisioned characteristic adopted in our meta-ensemble scheme. We rely on widely known ensemble models, combine them and offer an additional processing layer to increase the performance. The aim is to result a subset of EC nodes that will host each incoming query. Apart from the description of the proposed model, we report on its evaluation and the corresponding results. Through a large set of experiments and a numerical analysis, we aim at revealing the pros and cons of the proposed scheme.
Data Synopses Management based on a Deep Learning Model
Aug 01, 2020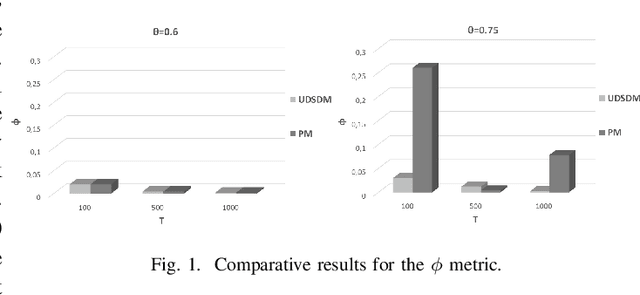
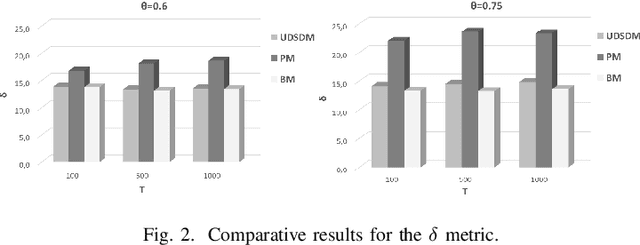
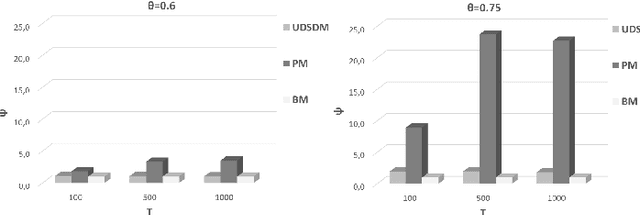
Pervasive computing involves the placement of processing services close to end users to support intelligent applications. With the advent of the Internet of Things (IoT) and the Edge Computing (EC), one can find room for placing services at various points in the interconnection of the aforementioned infrastructures. Of significant importance is the processing of the collected data. Such a processing can be realized upon the EC nodes that exhibit increased computational capabilities compared to IoT devices. An ecosystem of intelligent nodes is created at the EC giving the opportunity to support cooperative models. Nodes become the hosts of geo-distributed datasets formulated by the IoT devices reports. Upon the datasets, a number of queries/tasks can be executed. Queries/tasks can be offloaded for performance reasons. However, an offloading action should be carefully designed being always aligned with the data present to the hosting node. In this paper, we present a model to support the cooperative aspect in the EC infrastructure. We argue on the delivery of data synopses to EC nodes making them capable to take offloading decisions fully aligned with data present at peers. Nodes exchange data synopses to inform their peers. We propose a scheme that detects the appropriate time to distribute synopses trying to avoid the network overloading especially when synopses are frequently extracted due to the high rates at which IoT devices report data to EC nodes. Our approach involves a Deep Learning model for learning the distribution of calculated synopses and estimate future trends. Upon these trends, we are able to find the appropriate time to deliver synopses to peer nodes. We provide the description of the proposed mechanism and evaluate it based on real datasets. An extensive experimentation upon various scenarios reveals the pros and cons of the approach by giving numerical results.
Proactive Tasks Management based on a Deep Learning Model
Jul 31, 2020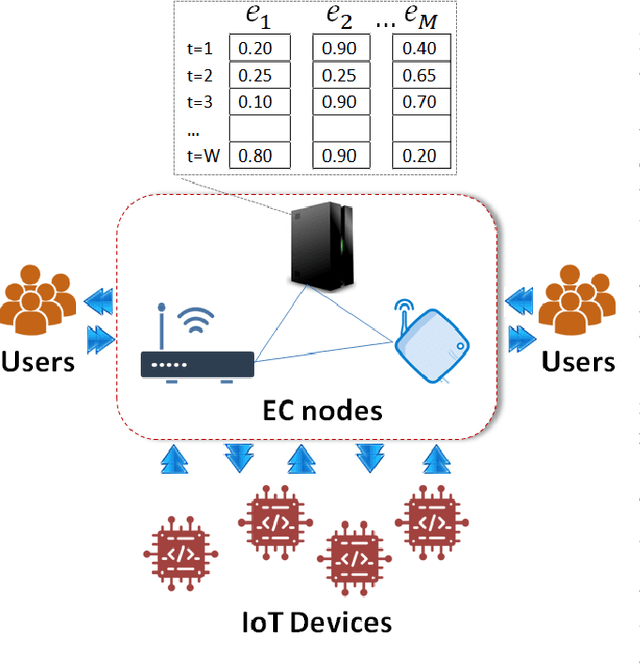
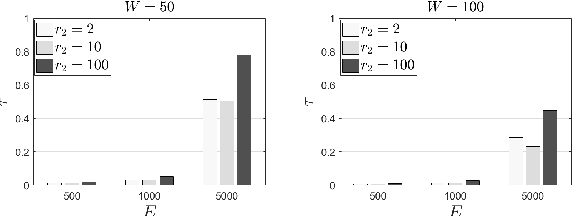
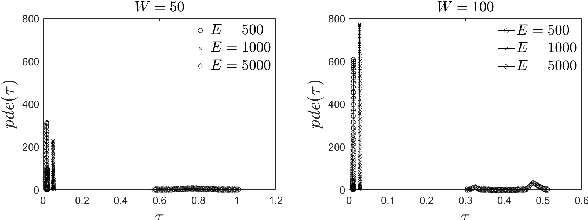
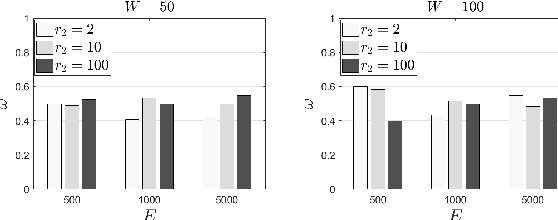
Pervasive computing applications deal with intelligence surrounding users that can facilitate their activities. This intelligence is provided in the form of software components incorporated in embedded systems or devices in close distance with end users.One example infrastructure that can host intelligent pervasive services is the Edge Computing (EC) infrastructure. EC nodes can execute a number of tasks for data collected by devices present in the Internet of Things (IoT) infrastructure. In this paper, we propose an intelligent, proactive tasks management model based on the demand. Demand depicts the number of users or applications interested in using the available tasks in EC nodes, thus, characterizing their popularity. We rely on a Deep Machine Learning (DML) model and more specifically on a Long Short Term Memory (LSTM) network to learn the distribution of demand indicators for each task and estimate the future interest. This information is combined with historical observations and support a decision making scheme to conclude which tasks will be offloaded due to limited interest on them. We have to notice that in our decision making, we also take into consideration the load that every task may add to the processing node where it will be allocated. The description of our model is accompanied by a large set of experimental simulations for evaluating the proposed mechanism. We provide numerical results and reveal that the proposed scheme is capable of deciding on the fly while concluding the most efficient allocation.
On the Use of Interpretable Machine Learning for the Management of Data Quality
Jul 29, 2020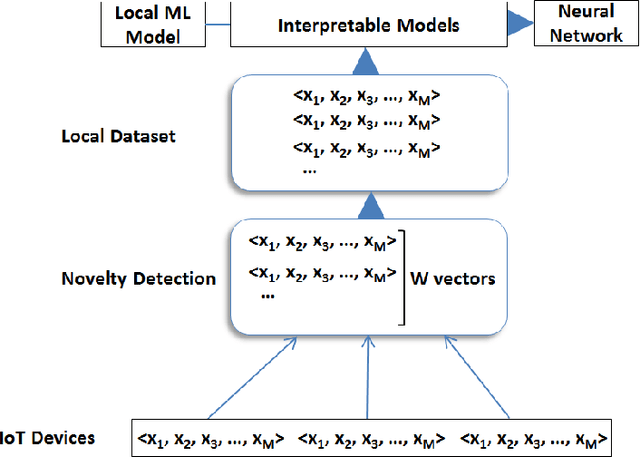
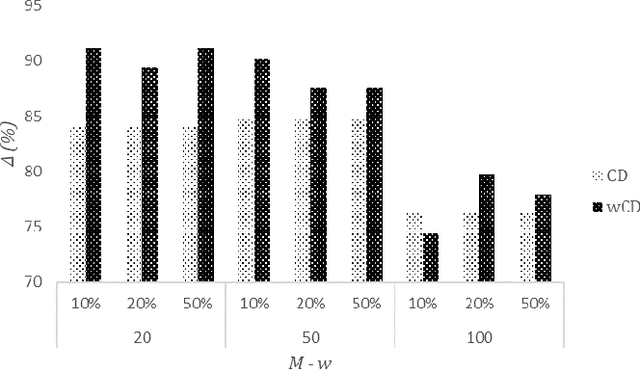
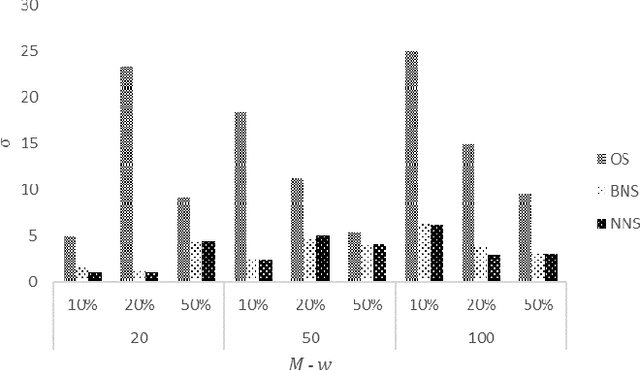
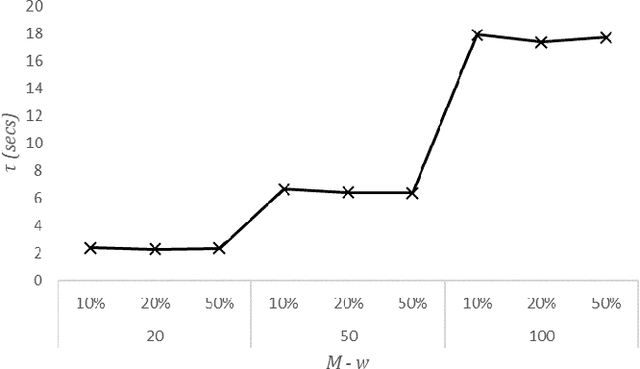
Data quality is a significant issue for any application that requests for analytics to support decision making. It becomes very important when we focus on Internet of Things (IoT) where numerous devices can interact to exchange and process data. IoT devices are connected to Edge Computing (EC) nodes to report the collected data, thus, we have to secure data quality not only at the IoT but also at the edge of the network. In this paper, we focus on the specific problem and propose the use of interpretable machine learning to deliver the features that are important to be based for any data processing activity. Our aim is to secure data quality, at least, for those features that are detected as significant in the collected datasets. We have to notice that the selected features depict the highest correlation with the remaining in every dataset, thus, they can be adopted for dimensionality reduction. We focus on multiple methodologies for having interpretability in our learning models and adopt an ensemble scheme for the final decision. Our scheme is capable of timely retrieving the final result and efficiently select the appropriate features. We evaluate our model through extensive simulations and present numerical results. Our aim is to reveal its performance under various experimental scenarios that we create varying a set of parameters adopted in our mechanism.