 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-in, Bias-out: Balanced and Real-time MoCap Solving
Sep 25, 2023



Real-time optical Motion Capture (MoCap) systems have not benefited from the advances in modern data-driven modeling. In this work we apply machine learning to solve noisy unstructured marker estimates in real-time and deliver robust marker-based MoCap even when using sparse affordable sensors. To achieve this we focus on a number of challenges related to model training, namely the sourcing of training data and their long-tailed distribution. Leveraging representation learning we design a technique for imbalanced regression that requires no additional data or labels and improves the performance of our model in rare and challenging poses. By relying on a unified representation, we show that training such a model is not bound to high-end MoCap training data acquisition, and exploit the advances in marker-less MoCap to acquire the necessary data. Finally, we take a step towards richer and affordable MoCap by adapting a body model-based inverse kinematics solution to account for measurement and inference uncertainty, further improving performance and robustness. Project page: https://moverseai.github.io/noise-tail
On Coordinate Decoding for Keypoint Estimation Tasks
Oct 19, 2021
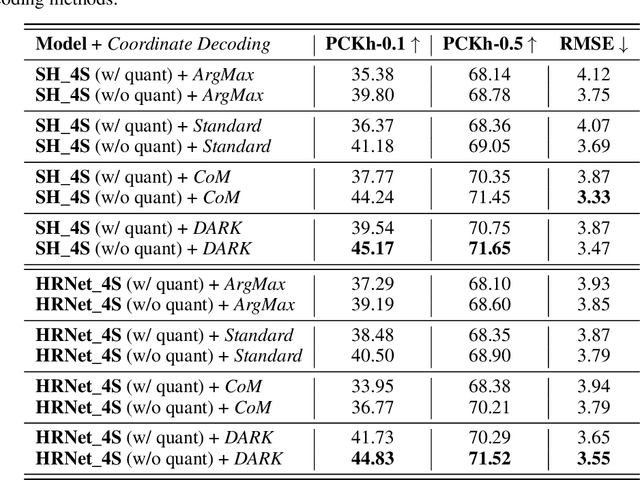


A series of 2D (and 3D) keypoint estimation tasks are built upon heatmap coordinate representation, i.e. a probability map that allows for learnable and spatially aware encoding and decoding of keypoint coordinates on grids, even allowing for sub-pixel coordinate accuracy. In this report, we aim to reproduce the findings of DARK that investigated the 2D heatmap representation by highlighting the importance of the encoding of the ground truth heatmap and the decoding of the predicted heatmap to keypoint coordinates. The authors claim that a) a more principled distribution-aware coordinate decoding method overcomes the limitations of the standard techniques widely used in the literature, and b), that the reconstruction of heatmaps from ground-truth coordinates by generating accurate and continuous heatmap distributions lead to unbiased model training, contrary to the standard coordinate encoding process that quantizes the keypoint coordinates on the resolution of the input image grid.
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 19, 2021

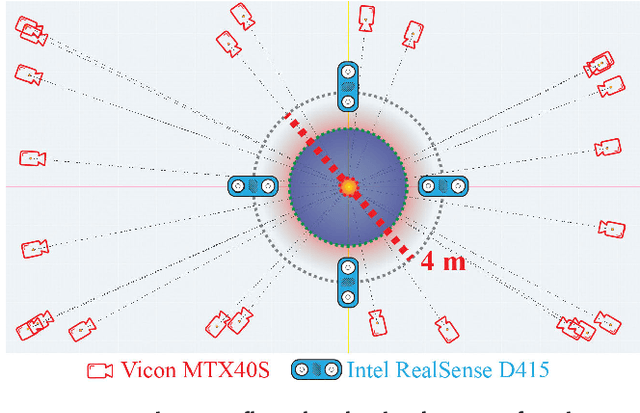
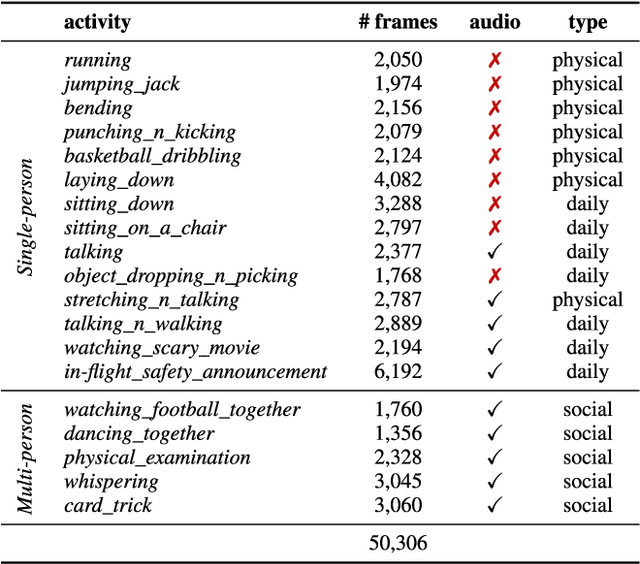
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.
DeepMoCap: Deep Optical Motion Capture Using Multiple Depth Sensors and Retro-Reflectors
Oct 14, 2021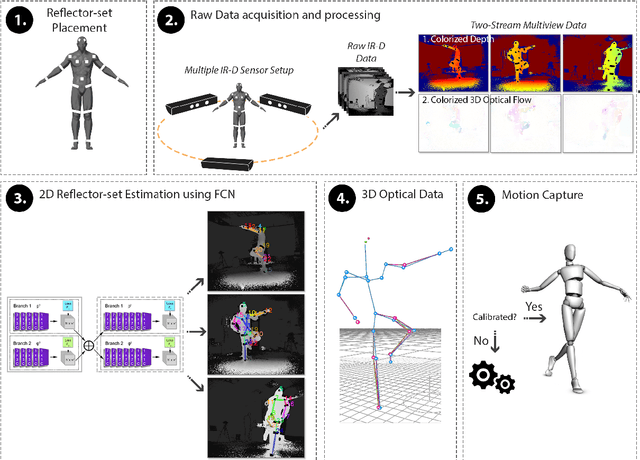
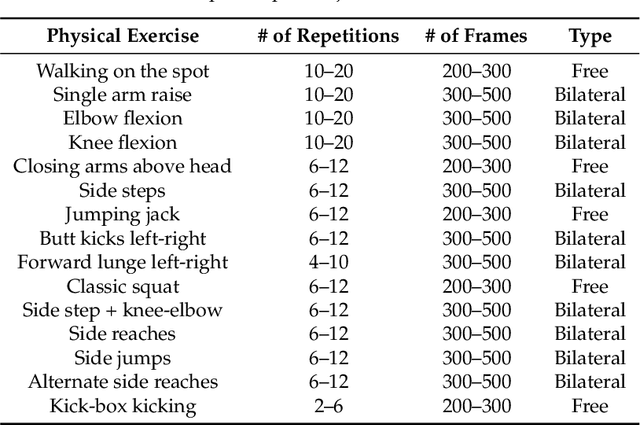
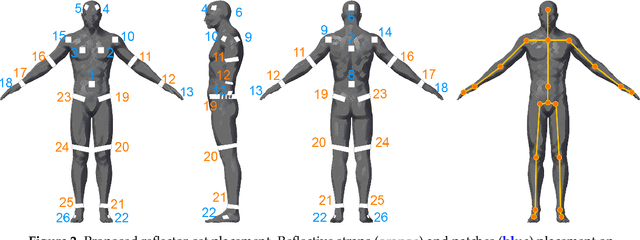
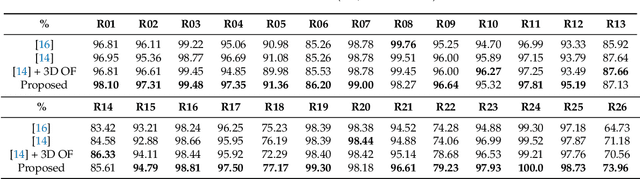
In this paper, a marker-based, single-person optical motion capture method (DeepMoCap) is proposed using multiple spatio-temporally aligned infrared-depth sensors and retro-reflective straps and patches (reflectors). DeepMoCap explores motion capture by automatically localizing and labeling reflectors on depth images and, subsequently, on 3D space. Introducing a non-parametric representation to encode the temporal correlation among pairs of colorized depthmaps and 3D optical flow frames, a multi-stage Fully Convolutional Network (FCN) architecture is proposed to jointly learn reflector locations and their temporal dependency among sequential frames. The extracted reflector 2D locations are spatially mapped in 3D space, resulting in robust 3D optical data extraction. The subject's motion is efficiently captured by applying a template-based fitting technique on the extracted optical data. Two datasets have been created and made publicly available for evaluation purposes; one comprising multi-view depth and 3D optical flow annotated images (DMC2.5D), and a second, consisting of spatio-temporally aligned multi-view depth images along with skeleton, inertial and ground truth MoCap data (DMC3D). The FCN model outperforms its competitors on the DMC2.5D dataset using 2D Percentage of Correct Keypoints (PCK) metric, while the motion capture outcome is evaluated against RGB-D and inertial data fusion approaches on DMC3D, outperforming the next best method by 4.5% in total 3D PCK accuracy.
Self-Supervised Deep Depth Denoising
Sep 04, 2019
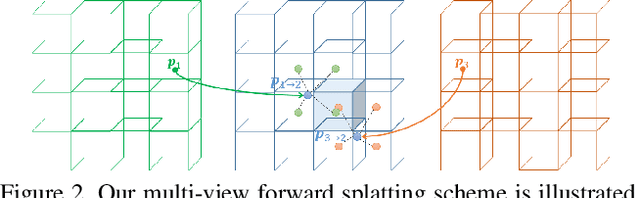
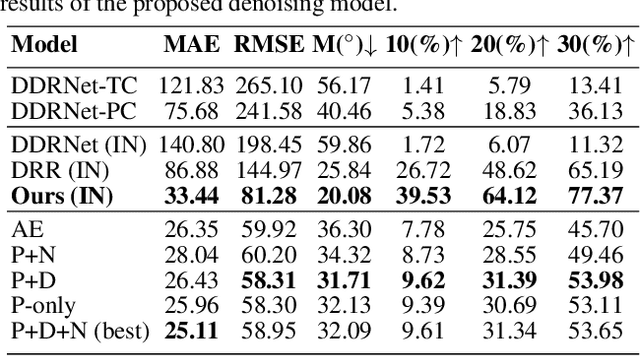
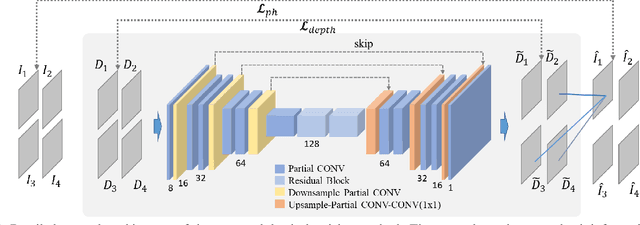
Depth perception is considered an invaluable source of information for various vision tasks. However, depth maps acquired using consumer-level sensors still suffer from non-negligible noise. This fact has recently motivated researchers to exploit traditional filters, as well as the deep learning paradigm, in order to suppress the aforementioned non-uniform noise, while preserving geometric details. Despite the effort, deep depth denoising is still an open challenge mainly due to the lack of clean data that could be used as ground truth. In this paper, we propose a fully convolutional deep autoencoder that learns to denoise depth maps, surpassing the lack of ground truth data. Specifically, the proposed autoencoder exploits multiple views of the same scene from different points of view in order to learn to suppress noise in a self-supervised end-to-end manner using depth and color information during training, yet only depth during inference. To enforce selfsupervision, we leverage a differentiable rendering technique to exploit photometric supervision, which is further regularized using geometric and surface priors. As the proposed approach relies on raw data acquisition, a large RGB-D corpus is collected using Intel RealSense sensors. Complementary to a quantitative evaluation, we demonstrate the effectiveness of the proposed self-supervised denoising approach on established 3D reconstruction applications. Code is avalable at https://github.com/VCL3D/DeepDepthDenoising
An Integrated Platform for Live 3D Human Reconstruction and Motion Capturing
Dec 08, 2017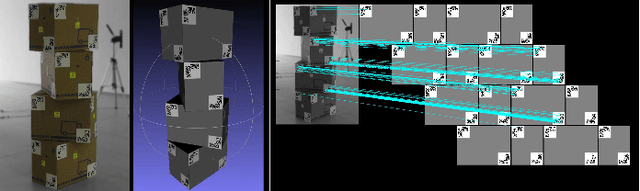

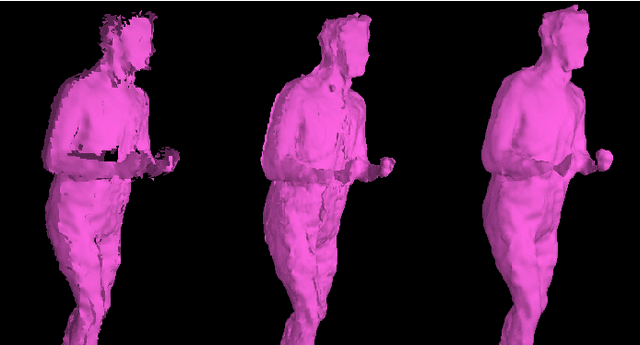

The latest developments in 3D capturing, processing, and rendering provide means to unlock novel 3D application pathways. The main elements of an integrated platform, which target tele-immersion and future 3D applications, are described in this paper, addressing the tasks of real-time capturing, robust 3D human shape/appearance reconstruction, and skeleton-based motion tracking. More specifically, initially, the details of a multiple RGB-depth (RGB-D) capturing system are given, along with a novel sensors' calibration method. A robust, fast reconstruction method from multiple RGB-D streams is then proposed, based on an enhanced variation of the volumetric Fourier transform-based method, parallelized on the Graphics Processing Unit, and accompanied with an appropriate texture-mapping algorithm. On top of that, given the lack of relevant objective evaluation methods, a novel framework is proposed for the quantitative evaluation of real-time 3D reconstruction systems. Finally, a generic, multiple depth stream-based method for accurate real-time human skeleton tracking is proposed. Detailed experimental results with multi-Kinect2 data sets verify the validity of our arguments and the effectiveness of the proposed system and methodologies.
* 16 pages, 12 figures, 3 tables