 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-NVS-w: Geometry-Aware Novel View Synthesis In-the-Wild with an SDF Renderer
Jan 13, 2026We introduce Geo-NVS-w, a geometry-aware framework for high-fidelity novel view synthesis from unstructured, in-the-wild image collections. While existing in-the-wild methods already excel at novel view synthesis, they often lack geometric grounding on complex surfaces, sometimes producing results that contain inconsistencies. Geo-NVS-w addresses this limitation by leveraging an underlying geometric representation based on a Signed Distance Function (SDF) to guide the rendering process. This is complemented by a novel Geometry-Preservation Loss which ensures that fine structural details are preserved. Our framework achieves competitive rendering performance, while demonstrating a 4-5x reduction reduction in energy consumption compared to similar methods. We demonstrate that Geo-NVS-w is a robust method for in-the-wild NVS, yielding photorealistic results with sharp, geometrically coherent details.
Which Direction to Choose? An Analysis on the Representation Power of Self-Supervised ViTs in Downstream Tasks
Sep 18, 2025Self-Supervised Learning (SSL) for Vision Transformers (ViTs) has recently demonstrated considerable potential as a pre-training strategy for a variety of computer vision tasks, including image classification and segmentation, both in standard and few-shot downstream contexts. Two pre-training objectives dominate the landscape of SSL techniques: Contrastive Learning and Masked Image Modeling. Features (or tokens) extracted from the final transformer attention block -- specifically, the keys, queries, and values -- as well as features obtained after the final block's feed-forward layer, have become a common foundation for addressing downstream tasks. However, in many existing approaches, these pre-trained ViT features are further processed through additional transformation layers, often involving lightweight heads or combined with distillation, to achieve superior task performance. Although such methods can improve task outcomes, to the best of our knowledge, a comprehensive analysis of the intrinsic representation capabilities of unaltered ViT features has yet to be conducted. This study aims to bridge this gap by systematically evaluating the use of these unmodified features across image classification and segmentation tasks, in both standard and few-shot contexts. The classification and segmentation rules that we use are either hyperplane based (as in logistic regression) or cosine-similarity based, both of which rely on the presence of interpretable directions in the ViT's latent space. Based on the previous rules and without the use of additional feature transformations, we conduct an analysis across token types, tasks, and pre-trained ViT models. This study provides insights into the optimal choice for token type and decision rule based on the task, context, and the pre-training objective, while reporting detailed findings on two widely-used datasets.
HAL-NeRF: High Accuracy Localization Leveraging Neural Radiance Fields
Apr 11, 2025



Precise camera localization is a critical task in XR applications and robotics. Using only the camera captures as input to a system is an inexpensive option that enables localization in large indoor and outdoor environments, but it presents challenges in achieving high accuracy. Specifically, camera relocalization methods, such as Absolute Pose Regression (APR), can localize cameras with a median translation error of more than $0.5m$ in outdoor scenes. This paper presents HAL-NeRF, a high-accuracy localization method that combines a CNN pose regressor with a refinement module based on a Monte Carlo particle filter. The Nerfacto model, an implementation of Neural Radiance Fields (NeRFs), is used to augment the data for training the pose regressor and to measure photometric loss in the particle filter refinement module. HAL-NeRF leverages Nerfacto's ability to synthesize high-quality novel views, significantly improving the performance of the localization pipeline. HAL-NeRF achieves state-of-the-art results that are conventionally measured as the average of the median per scene errors. The translation error was $0.025m$ and the rotation error was $0.59$ degrees and 0.04m and 0.58 degrees on the 7-Scenes dataset and Cambridge Landmarks datasets respectively, with the trade-off of increased computational time. This work highlights the potential of combining APR with NeRF-based refinement techniques to advance monocular camera relocalization accuracy.
Unsupervised Interpretable Basis Extraction for Concept-Based Visual Explanations
Mar 19, 2023



An important line of research attempts to explain CNN image classifier predictions and intermediate layer representations in terms of human understandable concepts. In this work, we expand on previous works in the literature that use annotated concept datasets to extract interpretable feature space directions and propose an unsupervised post-hoc method to extract a disentangling interpretable basis by looking for the rotation of the feature space that explains sparse one-hot thresholded transformed representations of pixel activations. We do experimentation with existing popular CNNs and demonstrate the effectiveness of our method in extracting an interpretable basis across network architectures and training datasets. We make extensions to the existing basis interpretability metrics found in the literature and show that, intermediate layer representations become more interpretable when transformed to the bases extracted with our method. Finally, using the basis interpretability metrics, we compare the bases extracted with our method with the bases derived with a supervised approach and find that, in one aspect, the proposed unsupervised approach has a strength that constitutes a limitation of the supervised one and give potential directions for future research.
Cross-Stitched Multi-task Dual Recursive Networks for Unified Single Image Deraining and Desnowing
Nov 15, 2022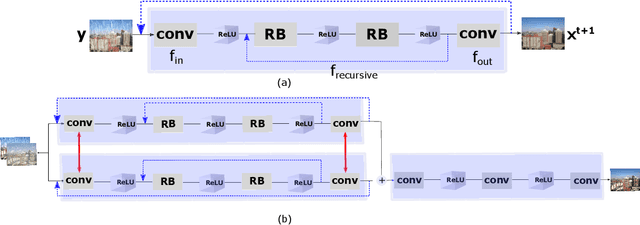
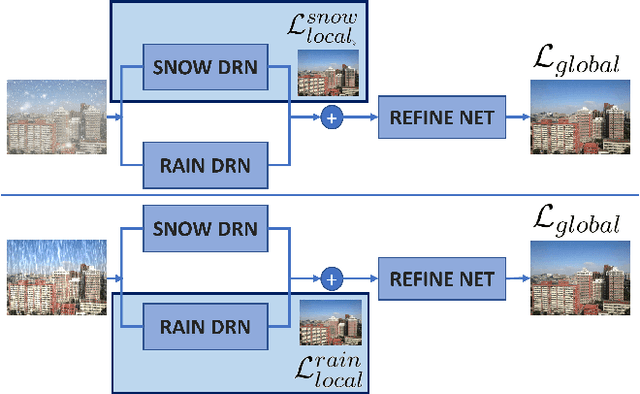

We present the Cross-stitched Multi-task Unified Dual Recursive Network (CMUDRN) model targeting the task of unified deraining and desnowing in a multi-task learning setting. This unified model borrows from the basic Dual Recursive Network (DRN) architecture developed by Cai et al. The proposed model makes use of cross-stitch units that enable multi-task learning across two separate DRN models, each tasked for single image deraining and desnowing, respectively. By fixing cross-stitch units at several layers of basic task-specific DRN networks, we perform multi-task learning over the two separate DRN models. To enable blind image restoration, on top of these structures we employ a simple neural fusion scheme which merges the output of each DRN. The separate task-specific DRN models and the fusion scheme are simultaneously trained by enforcing local and global supervision. Local supervision is applied on the two DRN submodules, and global supervision is applied on the data fusion submodule of the proposed model. Consequently, we both enable feature sharing across task-specific DRN models and control the image restoration behavior of the DRN submodules. An ablation study shows the strength of the hypothesized CMUDRN model, and experiments indicate that its performance is comparable or better than baseline DRN models on the single image deraining and desnowing tasks. Moreover, CMUDRN enables blind image restoration for the two underlying image restoration tasks, by unifying task-specific image restoration pipelines via a naive parametric fusion scheme. The CMUDRN implementation is available at https://github.com/VCL3D/CMUDRN.
Hybrid Skip: A Biologically Inspired Skip Connection for the UNet Architecture
Jul 11, 2022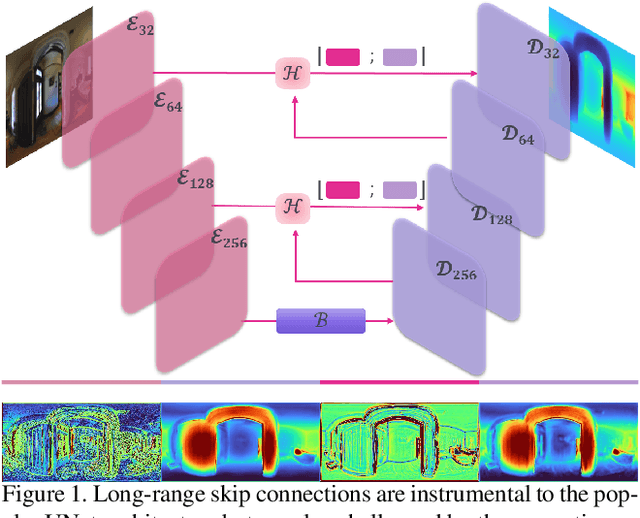

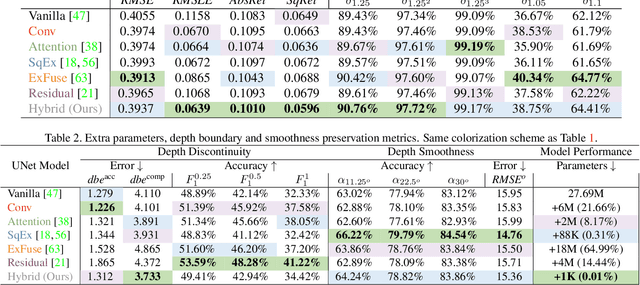
In this work we introduce a biologically inspired long-range skip connection for the UNet architecture that relies on the perceptual illusion of hybrid images, being images that simultaneously encode two images. The fusion of early encoder features with deeper decoder ones allows UNet models to produce finer-grained dense predictions. While proven in segmentation tasks, the network's benefits are down-weighted for dense regression tasks as these long-range skip connections additionally result in texture transfer artifacts. Specifically for depth estimation, this hurts smoothness and introduces false positive edges which are detrimental to the task due to the depth maps' piece-wise smooth nature. The proposed HybridSkip connections show improved performance in balancing the trade-off between edge preservation, and the minimization of texture transfer artifacts that hurt smoothness. This is achieved by the proper and balanced exchange of information that Hybrid-Skip connections offer between the high and low frequency, encoder and decoder features, respectively.
* Project page at https://vcl3d.github.io/HybridSkip/
Monocular Spherical Depth Estimation with Explicitly Connected Weak Layout Cues
Jun 22, 2022
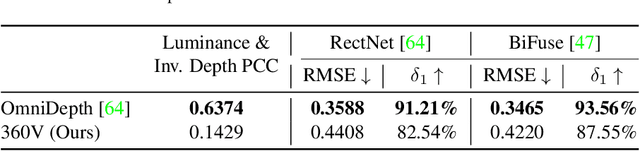
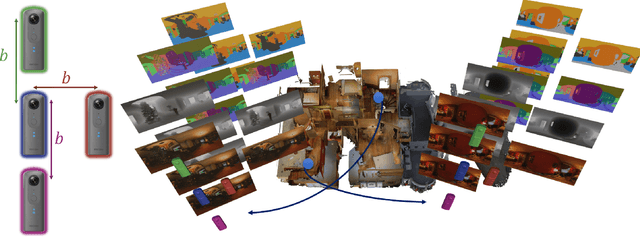

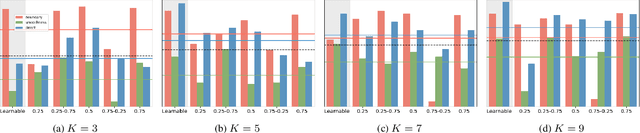
Spherical cameras capture scenes in a holistic manner and have been used for room layout estimation. Recently, with the availability of appropriate datasets, there has also been progress in depth estimation from a single omnidirectional image. While these two tasks are complementary, few works have been able to explore them in parallel to advance indoor geometric perception, and those that have done so either relied on synthetic data, or used small scale datasets, as few options are available that include both layout annotations and dense depth maps in real scenes. This is partly due to the necessity of manual annotations for room layouts. In this work, we move beyond this limitation and generate a 360 geometric vision (360V) dataset that includes multiple modalities, multi-view stereo data and automatically generated weak layout cues. We also explore an explicit coupling between the two tasks to integrate them into a singleshot trained model. We rely on depth-based layout reconstruction and layout-based depth attention, demonstrating increased performance across both tasks. By using single 360 cameras to scan rooms, the opportunity for facile and quick building-scale 3D scanning arises.
* Project page at https://vcl3d.github.io/ExplicitLayoutDepth/
Towards Full-to-Empty Room Generation with Structure-Aware Feature Encoding and Soft Semantic Region-Adaptive Normalization
Dec 10, 2021


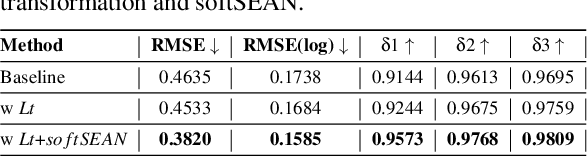
The task of transforming a furnished room image into a background-only is extremely challenging since it requires making large changes regarding the scene context while still preserving the overall layout and style. In order to acquire photo-realistic and structural consistent background, existing deep learning methods either employ image inpainting approaches or incorporate the learning of the scene layout as an individual task and leverage it later in a not fully differentiable semantic region-adaptive normalization module. To tackle these drawbacks, we treat scene layout generation as a feature linear transformation problem and propose a simple yet effective adjusted fully differentiable soft semantic region-adaptive normalization module (softSEAN) block. We showcase the applicability in diminished reality and depth estimation tasks, where our approach besides the advantages of mitigating training complexity and non-differentiability issues, surpasses the compared methods both quantitatively and qualitatively. Our softSEAN block can be used as a drop-in module for existing discriminative and generative models. Implementation is available on vcl3d.github.io/PanoDR/.
A benchmark with decomposed distribution shifts for 360 monocular depth estimation
Dec 01, 2021



In this work we contribute a distribution shift benchmark for a computer vision task; monocular depth estimation. Our differentiation is the decomposition of the wider distribution shift of uncontrolled testing on in-the-wild data, to three distinct distribution shifts. Specifically, we generate data via synthesis and analyze them to produce covariate (color input), prior (depth output) and concept (their relationship) distribution shifts. We also synthesize combinations and show how each one is indeed a different challenge to address, as stacking them produces increased performance drops and cannot be addressed horizontally using standard approaches.
On Coordinate Decoding for Keypoint Estimation Tasks
Oct 19, 2021
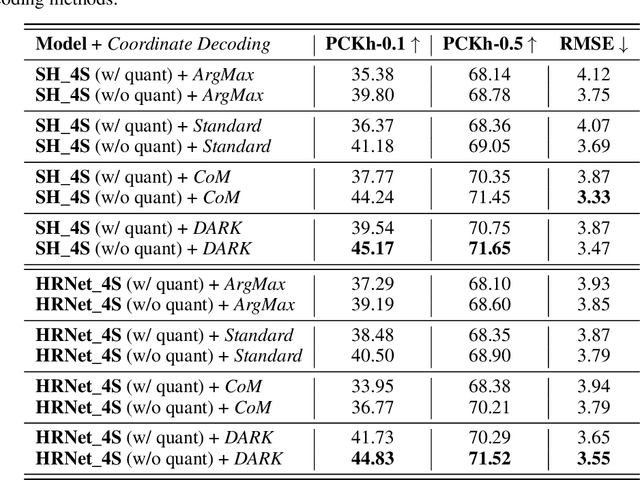


A series of 2D (and 3D) keypoint estimation tasks are built upon heatmap coordinate representation, i.e. a probability map that allows for learnable and spatially aware encoding and decoding of keypoint coordinates on grids, even allowing for sub-pixel coordinate accuracy. In this report, we aim to reproduce the findings of DARK that investigated the 2D heatmap representation by highlighting the importance of the encoding of the ground truth heatmap and the decoding of the predicted heatmap to keypoint coordinates. The authors claim that a) a more principled distribution-aware coordinate decoding method overcomes the limitations of the standard techniques widely used in the literature, and b), that the reconstruction of heatmaps from ground-truth coordinates by generating accurate and continuous heatmap distributions lead to unbiased model training, contrary to the standard coordinate encoding process that quantizes the keypoint coordinates on the resolution of the input image grid.