 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Transfer Learning for Multilingual Coreference Resolution
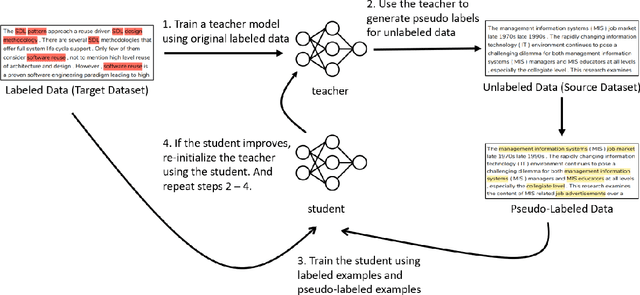
Jan 22, 2023Entity coreference resolution is an important research problem with many applications, including information extraction and question answering. Coreference resolution for English has been studied extensively. However, there is relatively little work for other languages. A problem that frequently occurs when working with a non-English language is the scarcity of annotated training data. To overcome this challenge, we design a simple but effective ensemble-based framework that combines various transfer learning (TL) techniques. We first train several models using different TL methods. Then, during inference, we compute the unweighted average scores of the models' predictions to extract the final set of predicted clusters. Furthermore, we also propose a low-cost TL method that bootstraps coreference resolution models by utilizing Wikipedia anchor texts. Leveraging the idea that the coreferential links naturally exist between anchor texts pointing to the same article, our method builds a sizeable distantly-supervised dataset for the target language that consists of tens of thousands of documents. We can pre-train a model on the pseudo-labeled dataset before finetuning it on the final target dataset. Experimental results on two benchmark datasets, OntoNotes and SemEval, confirm the effectiveness of our methods. Our best ensembles consistently outperform the baseline approach of simple training by up to 7.68% in the F1 score. These ensembles also achieve new state-of-the-art results for three languages: Arabic, Dutch, and Spanish.
Improving Candidate Retrieval with Entity Profile Generation for Wikidata Entity Linking
Mar 14, 2022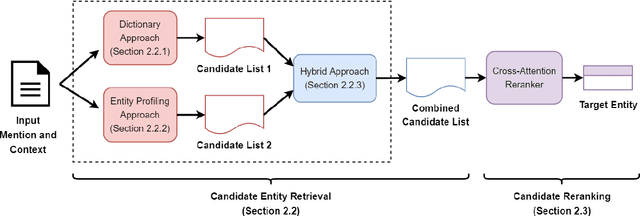
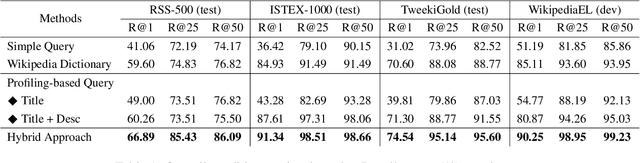
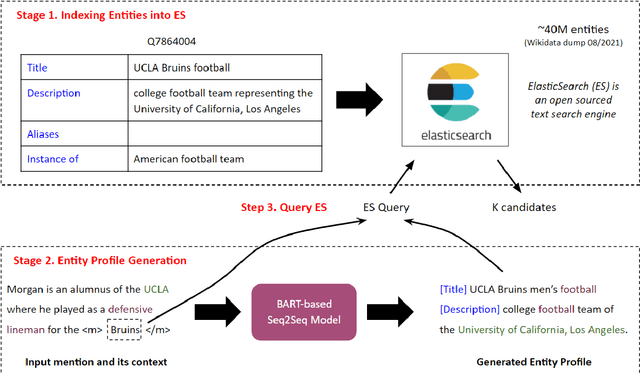
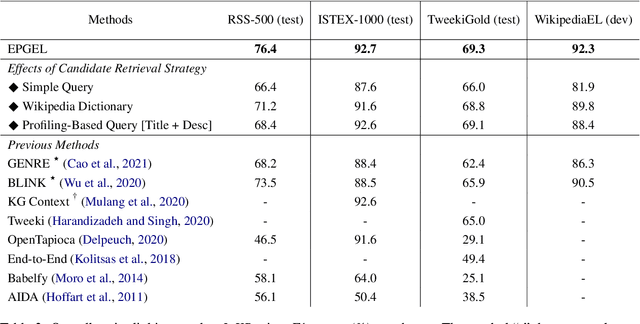
Entity linking (EL) is the task of linking entity mentions in a document to referent entities in a knowledge base (KB). Many previous studies focus on Wikipedia-derived KBs. There is little work on EL over Wikidata, even though it is the most extensive crowdsourced KB. The scale of Wikidata can open up many new real-world applications, but its massive number of entities also makes EL challenging. To effectively narrow down the search space, we propose a novel candidate retrieval paradigm based on entity profiling. Wikidata entities and their textual fields are first indexed into a text search engine (e.g., Elasticsearch). During inference, given a mention and its context, we use a sequence-to-sequence (seq2seq) model to generate the profile of the target entity, which consists of its title and description. We use the profile to query the indexed search engine to retrieve candidate entities. Our approach complements the traditional approach of using a Wikipedia anchor-text dictionary, enabling us to further design a highly effective hybrid method for candidate retrieval. Combined with a simple cross-attention reranker, our complete EL framework achieves state-of-the-art results on three Wikidata-based datasets and strong performance on TACKBP-2010.
A Unified Transformer-based Framework for Duplex Text Normalization
Aug 23, 2021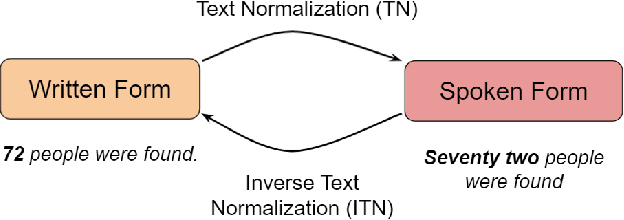
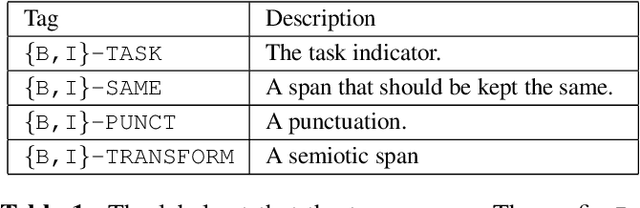
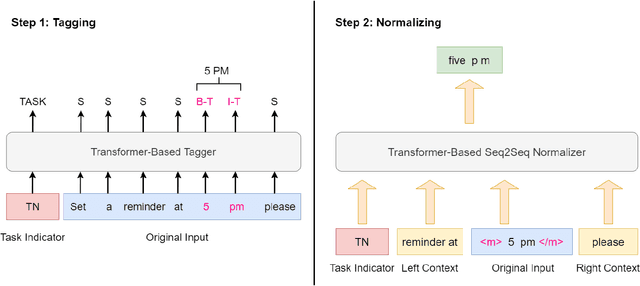
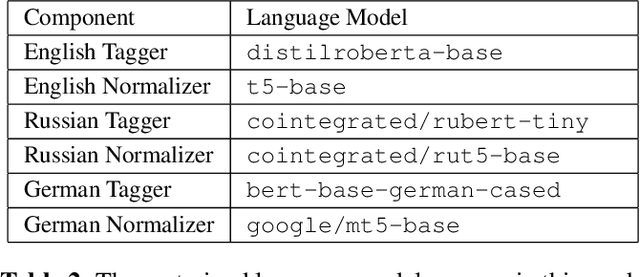
Text normalization (TN) and inverse text normalization (ITN) are essential preprocessing and postprocessing steps for text-to-speech synthesis and automatic speech recognition, respectively. Many methods have been proposed for either TN or ITN, ranging from weighted finite-state transducers to neural networks. Despite their impressive performance, these methods aim to tackle only one of the two tasks but not both. As a result, in a complete spoken dialog system, two separate models for TN and ITN need to be built. This heterogeneity increases the technical complexity of the system, which in turn increases the cost of maintenance in a production setting. Motivated by this observation, we propose a unified framework for building a single neural duplex system that can simultaneously handle TN and ITN. Combined with a simple but effective data augmentation method, our systems achieve state-of-the-art results on the Google TN dataset for English and Russian. They can also reach over 95% sentence-level accuracy on an internal English TN dataset without any additional fine-tuning. In addition, we also create a cleaned dataset from the Spoken Wikipedia Corpora for German and report the performance of our systems on the dataset. Overall, experimental results demonstrate the proposed duplex text normalization framework is highly effective and applicable to a range of domains and languages
End-to-end Neural Coreference Resolution Revisited: A Simple yet Effective Baseline
Jul 13, 2021


Since the first end-to-end neural coreference resolution model was introduced, many extensions to the model have been proposed, ranging from using higher-order inference to directly optimizing evaluation metrics using reinforcement learning. Despite improving the coreference resolution performance by a large margin, these extensions add a lot of extra complexity to the original model. Motivated by this observation and the recent advances in pre-trained Transformer language models, we propose a simple yet effective baseline for coreference resolution. Our model is a simplified version of the original neural coreference resolution model, however, it achieves impressive performance, outperforming all recent extended works on the public English OntoNotes benchmark. Our work provides evidence for the necessity of carefully justifying the complexity of existing or newly proposed models, as introducing a conceptual or practical simplification to an existing model can still yield competitive results.
A Joint Learning Approach based on Self-Distillation for Keyphrase Extraction from Scientific Documents
Oct 22, 2020

Keyphrase extraction is the task of extracting a small set of phrases that best describe a document. Most existing benchmark datasets for the task typically have limited numbers of annotated documents, making it challenging to train increasingly complex neural networks. In contrast, digital libraries store millions of scientific articles online, covering a wide range of topics. While a significant portion of these articles contain keyphrases provided by their authors, most other articles lack such kind of annotations. Therefore, to effectively utilize these large amounts of unlabeled articles, we propose a simple and efficient joint learning approach based on the idea of self-distillation. Experimental results show that our approach consistently improves the performance of baseline models for keyphrase extraction. Furthermore, our best models outperform previous methods for the task, achieving new state-of-the-art results on two public benchmarks: Inspec and SemEval-2017.
ISA: An Intelligent Shopping Assistant
Jul 07, 2020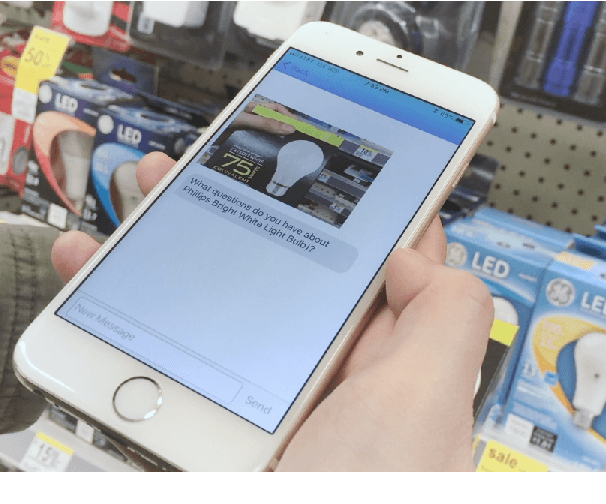
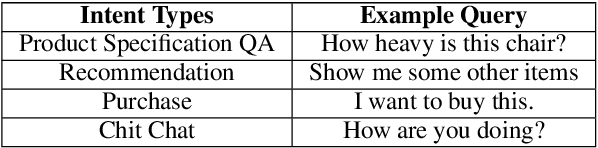
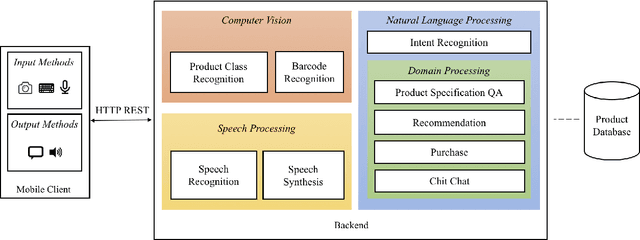

Despite the growth of e-commerce, brick-and-mortar stores are still the preferred destinations for many people. In this paper, we present ISA, a mobile-based intelligent shopping assistant that is designed to improve shopping experience in physical stores. ISA assists users by leveraging advanced techniques in computer vision, speech processing, and natural language processing. An in-store user only needs to take a picture or scan the barcode of the product of interest, and then the user can talk to the assistant about the product. The assistant can also guide the user through the purchase process or recommend other similar products to the user. We take a data-driven approach in building the engines of ISA's natural language processing component, and the engines achieve good performance.
A Simple but Effective BERT Model for Dialog State Tracking on Resource-Limited Systems
Oct 28, 2019

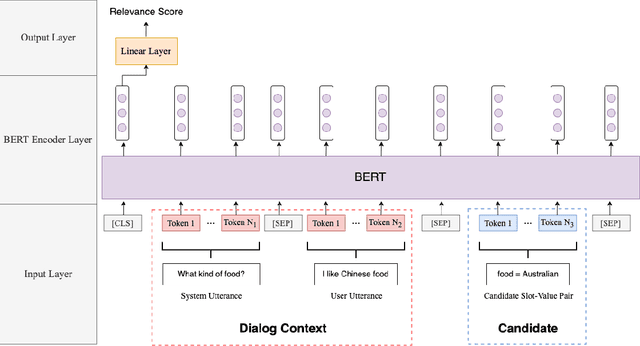
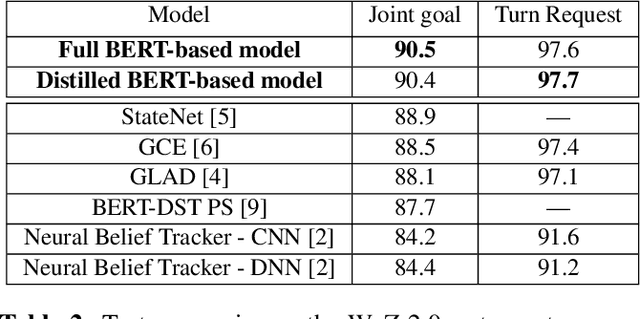
In a task-oriented dialog system, the goal of dialog state tracking (DST) is to monitor the state of the conversation from the dialog history. Recently, many deep learning based methods have been proposed for the task. Despite their impressive performance, current neural architectures for DST are typically heavily-engineered and conceptually complex, making it difficult to implement, debug, and maintain them in a production setting. In this work, we propose a simple but effective DST model based on BERT. In addition to its simplicity, our approach also has a number of other advantages: (a) the number of parameters does not grow with the ontology size (b) the model can operate in situations where the domain ontology may change dynamically. Experimental results demonstrate that our BERT-based model outperforms previous methods by a large margin, achieving new state-of-the-art results on the standard WoZ 2.0 dataset. Finally, to make the model small and fast enough for resource-restricted systems, we apply the knowledge distillation method to compress our model. The final compressed model achieves comparable results with the original model while being 8x smaller and 7x faster.
Supervised Transfer Learning for Product Information Question Answering
Jan 08, 2019
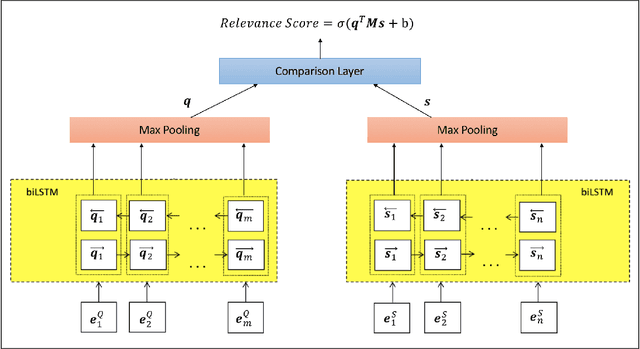


Popular e-commerce websites such as Amazon offer community question answering systems for users to pose product related questions and experienced customers may provide answers voluntarily. In this paper, we show that the large volume of existing community question answering data can be beneficial when building a system for answering questions related to product facts and specifications. Our experimental results demonstrate that the performance of a model for answering questions related to products listed in the Home Depot website can be improved by a large margin via a simple transfer learning technique from an existing large-scale Amazon community question answering dataset. Transfer learning can result in an increase of about 10% in accuracy in the experimental setting where we restrict the size of the data of the target task used for training. As an application of this work, we integrate the best performing model trained in this work into a mobile-based shopping assistant and show its usefulness.