 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Neural Coreference Resolution Revisited: A Simple yet Effective Baseline
Paper and Code
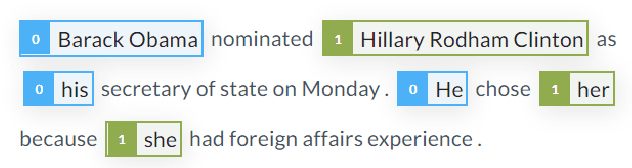

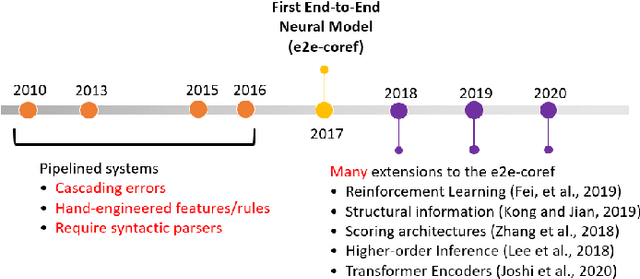

Since the first end-to-end neural coreference resolution model was introduced, many extensions to the model have been proposed, ranging from using higher-order inference to directly optimizing evaluation metrics using reinforcement learning. Despite improving the coreference resolution performance by a large margin, these extensions add a lot of extra complexity to the original model. Motivated by this observation and the recent advances in pre-trained Transformer language models, we propose a simple yet effective baseline for coreference resolution. Our model is a simplified version of the original neural coreference resolution model, however, it achieves impressive performance, outperforming all recent extended works on the public English OntoNotes benchmark. Our work provides evidence for the necessity of carefully justifying the complexity of existing or newly proposed models, as introducing a conceptual or practical simplification to an existing model can still yield competitive results.