 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPs and KANs for data-driven learning in physical problems: A performance comparison
Apr 15, 2025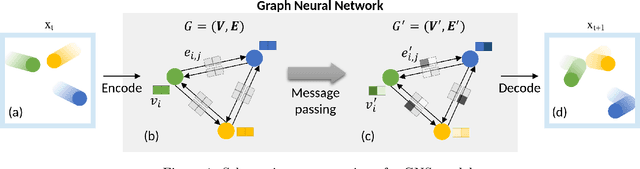

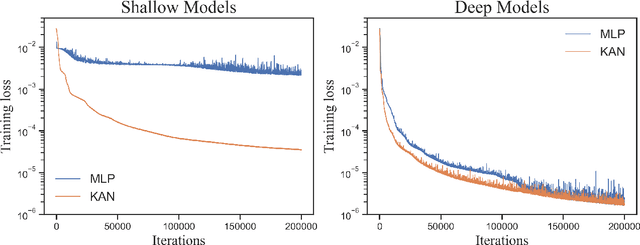

There is increasing interest in solving partial differential equations (PDEs) by casting them as machine learning problems. Recently, there has been a spike in exploring Kolmogorov-Arnold Networks (KANs) as an alternative to traditional neural networks represented by Multi-Layer Perceptrons (MLPs). While showing promise, their performance advantages in physics-based problems remain largely unexplored. Several critical questions persist: Can KANs capture complex physical dynamics and under what conditions might they outperform traditional architectures? In this work, we present a comparative study of KANs and MLPs for learning physical systems governed by PDEs. We assess their performance when applied in deep operator networks (DeepONet) and graph network-based simulators (GNS), and test them on physical problems that vary significantly in scale and complexity. Drawing inspiration from the Kolmogorov Representation Theorem, we examine the behavior of KANs and MLPs across shallow and deep network architectures. Our results reveal that although KANs do not consistently outperform MLPs when configured as deep neural networks, they demonstrate superior expressiveness in shallow network settings, significantly outpacing MLPs in accuracy over our test cases. This suggests that KANs are a promising choice, offering a balance of efficiency and accuracy in applications involving physical systems.
MKOR: Momentum-Enabled Kronecker-Factor-Based Optimizer Using Rank-1 Updates
Jun 02, 2023



This work proposes a Momentum-Enabled Kronecker-Factor-Based Optimizer Using Rank-1 updates, called MKOR, that improves the training time and convergence properties of deep neural networks (DNNs). Second-order techniques, while enjoying higher convergence rates vs first-order counterparts, have cubic complexity with respect to either the model size and/or the training batch size. Hence they exhibit poor scalability and performance in transformer models, e.g. large language models (LLMs), because the batch sizes in these models scale by the attention mechanism sequence length, leading to large model size and batch sizes. MKOR's complexity is quadratic with respect to the model size, alleviating the computation bottlenecks in second-order methods. Because of their high computation complexity, state-of-the-art implementations of second-order methods can only afford to update the second order information infrequently, and thus do not fully exploit the promise of better convergence from these updates. By reducing the communication complexity of the second-order updates as well as achieving a linear communication complexity, MKOR increases the frequency of second order updates. We also propose a hybrid version of MKOR (called MKOR-H) that mid-training falls backs to a first order optimizer if the second order updates no longer accelerate convergence. Our experiments show that MKOR outperforms state -of-the-art first order methods, e.g. the LAMB optimizer, and best implementations of second-order methods, i.e. KAISA/KFAC, up to 2.57x and 1.85x respectively on BERT-Large-Uncased on 64 GPUs.