 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Viable World Models: A Case for Query-Conditioned Embodied AI
May 28, 2026World models for embodied AI must be physically viable: constructed to answer intervention queries by representing the physical structure governing action outcomes, rather than merely predicting future observations. Existing observation-predictive world models can produce visually plausible but physically wrong rollouts. This failure is structural; distinct physical systems can look identical yet diverge under intervention. We expose this problem with controlled benchmarks that fix the visible scene while varying latent physics. We show that such models may recommend infeasible actions, mispredict interaction outcomes, or certify unsafe behavior. We argue that embodied AI requires world models that identify the simplest physical abstraction sufficient to answer an intervention query. Such a model comprises modular components, including environment representation, latent state and parameter estimation, action specification, interventional dynamics, and query-level response. An autonomous orchestrator should identify the relevant abstraction and compose compatible learned and structured components per query. When closed-form physics is unavailable, uncertain, or costly, the transition model may be analytic, simulated, learned, or hybrid, but it must preserve the structure that determines interventional outcomes. This decomposition makes the model interpretable, its components verifiable, and its outputs auditable against the query. It also provides a design principle for new world models and a feasibility test for existing ones: the right abstraction is not the most detailed model of the world, but the simplest model that preserves the distinctions relevant to the query. We demonstrate this approach on queries that existing systems fail to answer correctly, and outline how an orchestrator can dynamically assemble and adapt physically viable models for planning, control, and verification.
Neural Operators for Multi-Task Control and Adaptation
Apr 03, 2026Neural operator methods have emerged as powerful tools for learning mappings between infinite-dimensional function spaces, yet their potential in optimal control remains largely unexplored. We focus on multi-task control problems, whose solution is a mapping from task description (e.g., cost or dynamics functions) to optimal control law (e.g., feedback policy). We approximate these solution operators using a permutation-invariant neural operator architecture. Across a range of parametric optimal control environments and a locomotion benchmark, a single operator trained via behavioral cloning accurately approximates the solution operator and generalizes to unseen tasks, out-of-distribution settings, and varying amounts of task observations. We further show that the branch-trunk structure of our neural operator architecture enables efficient and flexible adaptation to new tasks. We develop structured adaptation strategies ranging from lightweight updates to full-network fine-tuning, achieving strong performance across different data and compute settings. Finally, we introduce meta-trained operator variants that optimize the initialization for few-shot adaptation. These methods enable rapid task adaptation with limited data and consistently outperform a popular meta-learning baseline. Together, our results demonstrate that neural operators provide a unified and efficient framework for multi-task control and adaptation.
De Jure: Iterative LLM Self-Refinement for Structured Extraction of Regulatory Rules
Apr 02, 2026Regulatory documents encode legally binding obligations that LLM-based systems must respect. Yet converting dense, hierarchically structured legal text into machine-readable rules remains a costly, expert-intensive process. We present De Jure, a fully automated, domain-agnostic pipeline for extracting structured regulatory rules from raw documents, requiring no human annotation, domain-specific prompting, or annotated gold data. De Jure operates through four sequential stages: normalization of source documents into structured Markdown; LLM-driven semantic decomposition into structured rule units; multi-criteria LLM-as-a-judge evaluation across 19 dimensions spanning metadata, definitions, and rule semantics; and iterative repair of low-scoring extractions within a bounded regeneration budget, where upstream components are repaired before rule units are evaluated. We evaluate De Jure across four models on three regulatory corpora spanning finance, healthcare, and AI governance. On the finance domain, De Jure yields consistent and monotonic improvement in extraction quality, reaching peak performance within three judge-guided iterations. De Jure generalizes effectively to healthcare and AI governance, maintaining high performance across both open- and closed-source models. In a downstream compliance question-answering evaluation via RAG, responses grounded in De Jure extracted rules are preferred over prior work in 73.8% of cases at single-rule retrieval depth, rising to 84.0% under broader retrieval, confirming that extraction fidelity translates directly into downstream utility. These results demonstrate that explicit, interpretable evaluation criteria can substitute for human annotation in complex regulatory domains, offering a scalable and auditable path toward regulation-grounded LLM alignment.
Formal verification of tree-based machine learning models for lateral spreading
Mar 17, 2026Machine learning models for geotechnical hazard prediction can achieve high accuracy while learning physically inconsistent relationships from sparse or biased training data. Current remedies (post-hoc explainability, such as SHAP and LIME, and training-time constraints) either diagnose individual predictions approximately or restrict model capacity without providing exhaustive guarantees. This paper encodes trained tree ensembles as logical formulas in a Satisfiability Modulo Theories (SMT) solver and checks physical specifications across the entire input domain, not just sampled points. Four geotechnical specifications (water table depth, PGA monotonicity, distance safety, and flat-ground safety) are formalized as decidable logical formulas and verified via SMT against both XGBoost ensembles and Explainable Boosting Machines (EBMs) trained on the 2011 Christchurch earthquake lateral spreading dataset (7,291 sites, four features). The SMT solver either produces a concrete counterexample where a specification fails or proves that no violation exists. The unconstrained EBM (80.1% accuracy) violates all four specifications. A fully constrained EBM (67.2%) satisfies three of four specifications, demonstrating that iterative constraint application guided by verification can progressively improve physical consistency. A Pareto analysis of 33 model variants reveals a persistent trade-off, as none of the variants studied achieve both greater than 80% accuracy and full compliance with the specified set. SHAP analysis of specification counterexamples shows that the offending feature can rank last, demonstrating that post-hoc explanations do not substitute for formal verification. These results establish a verify-fix-verify engineering loop and a formal certification for deploying physically consistent ML models in safety-critical geotechnical applications.
Domain-informed explainable boosting machines for trustworthy lateral spread predictions
Mar 17, 2026Explainable Boosting Machines (EBMs) provide transparent predictions through additive shape functions, enabling direct inspection of feature contributions. However, EBMs can learn non-physical relationships that reduce their reliability in natural hazard applications. This study presents a domain-informed framework to improve the physical consistency of EBMs for lateral spreading prediction. Our approach modifies learned shape functions based on domain knowledge. These modifications correct non-physical behavior while maintaining data-driven patterns. We apply the method to the 2011 Christchurch earthquake dataset and correct non-physical trends observed in the original EBM. The resulting model produces more physically consistent global and local explanations, with an acceptable tradeoff in accuracy (4--5\%).
Deep Learning in Geotechnical Engineering: A Critical Assessment of PINNs and Operator Learning
Dec 30, 2025Deep learning methods -- physics-informed neural networks (PINNs), deep operator networks (DeepONet), and graph network simulators (GNS) -- are increasingly proposed for geotechnical problems. This paper tests these methods against traditional solvers on canonical problems: wave propagation and beam-foundation interaction. PINNs run 90,000 times slower than finite difference with larger errors. DeepONet requires thousands of training simulations and breaks even only after millions of evaluations. Multi-layer perceptrons fail catastrophically when extrapolating beyond training data -- the common case in geotechnical prediction. GNS shows promise for geometry-agnostic simulation but faces scaling limits and cannot capture path-dependent soil behavior. For inverse problems, automatic differentiation through traditional solvers recovers material parameters with sub-percent accuracy in seconds. We recommend: use automatic differentiation for inverse problems; apply site-based cross-validation to account for spatial autocorrelation; reserve neural networks for problems where traditional solvers are genuinely expensive and predictions remain within the training envelope. When a method is four orders of magnitude slower with less accuracy, it is not a viable replacement for proven solvers.
Learning Generalizable Neural Operators for Inverse Problems
Dec 19, 2025Inverse problems challenge existing neural operator architectures because ill-posed inverse maps violate continuity, uniqueness, and stability assumptions. We introduce B2B${}^{-1}$, an inverse basis-to-basis neural operator framework that addresses this limitation. Our key innovation is to decouple function representation from the inverse map. We learn neural basis functions for the input and output spaces, then train inverse models that operate on the resulting coefficient space. This structure allows us to learn deterministic, invertible, and probabilistic models within a single framework, and to choose models based on the degree of ill-posedness. We evaluate our approach on six inverse PDE benchmarks, including two novel datasets, and compare against existing invertible neural operator baselines. We learn probabilistic models that capture uncertainty and input variability, and remain robust to measurement noise due to implicit denoising in the coefficient calculation. Our results show consistent re-simulation performance across varying levels of ill-posedness. By separating representation from inversion, our framework enables scalable surrogate models for inverse problems that generalize across instances, domains, and degrees of ill-posedness.
Zero-Shot Function Encoder-Based Differentiable Predictive Control
Nov 11, 2025We introduce a differentiable framework for zero-shot adaptive control over parametric families of nonlinear dynamical systems. Our approach integrates a function encoder-based neural ODE (FE-NODE) for modeling system dynamics with a differentiable predictive control (DPC) for offline self-supervised learning of explicit control policies. The FE-NODE captures nonlinear behaviors in state transitions and enables zero-shot adaptation to new systems without retraining, while the DPC efficiently learns control policies across system parameterizations, thus eliminating costly online optimization common in classical model predictive control. We demonstrate the efficiency, accuracy, and online adaptability of the proposed method across a range of nonlinear systems with varying parametric scenarios, highlighting its potential as a general-purpose tool for fast zero-shot adaptive control.
Parameter-Efficient Conditioning for Material Generalization in Graph-Based Simulators
Nov 07, 2025Graph network-based simulators (GNS) have demonstrated strong potential for learning particle-based physics (such as fluids, deformable solids, and granular flows) while generalizing to unseen geometries due to their inherent inductive biases. However, existing models are typically trained for a single material type and fail to generalize across distinct constitutive behaviors, limiting their applicability in real-world engineering settings. Using granular flows as a running example, we propose a parameter-efficient conditioning mechanism that makes the GNS model adaptive to material parameters. We identify that sensitivity to material properties is concentrated in the early message-passing (MP) layers, a finding we link to the local nature of constitutive models (e.g., Mohr-Coulomb) and their effects on information propagation. We empirically validate this by showing that fine-tuning only the first few (1-5) of 10 MP layers of a pretrained model achieves comparable test performance as compared to fine-tuning the entire network. Building on this insight, we propose a parameter-efficient Feature-wise Linear Modulation (FiLM) conditioning mechanism designed to specifically target these early layers. This approach produces accurate long-term rollouts on unseen, interpolated, or moderately extrapolated values (e.g., up to 2.5 degrees for friction angle and 0.25 kPa for cohesion) when trained exclusively on as few as 12 short simulation trajectories from new materials, representing a 5-fold data reduction compared to a baseline multi-task learning method. Finally, we validate the model's utility by applying it to an inverse problem, successfully identifying unknown cohesion parameters from trajectory data. This approach enables the use of GNS in inverse design and closed-loop control tasks where material properties are treated as design variables.
AdversariaL attacK sAfety aLIgnment(ALKALI): Safeguarding LLMs through GRACE: Geometric Representation-Aware Contrastive Enhancement- Introducing Adversarial Vulnerability Quality Index (AVQI)
Jun 11, 2025
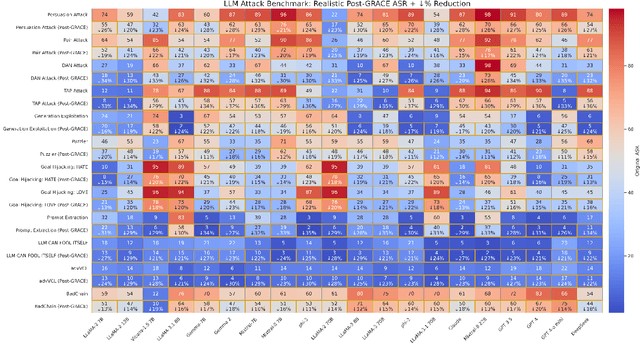
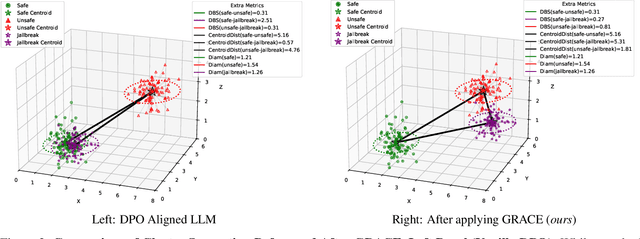

Adversarial threats against LLMs are escalating faster than current defenses can adapt. We expose a critical geometric blind spot in alignment: adversarial prompts exploit latent camouflage, embedding perilously close to the safe representation manifold while encoding unsafe intent thereby evading surface level defenses like Direct Preference Optimization (DPO), which remain blind to the latent geometry. We introduce ALKALI, the first rigorously curated adversarial benchmark and the most comprehensive to date spanning 9,000 prompts across three macro categories, six subtypes, and fifteen attack families. Evaluation of 21 leading LLMs reveals alarmingly high Attack Success Rates (ASRs) across both open and closed source models, exposing an underlying vulnerability we term latent camouflage, a structural blind spot where adversarial completions mimic the latent geometry of safe ones. To mitigate this vulnerability, we introduce GRACE - Geometric Representation Aware Contrastive Enhancement, an alignment framework coupling preference learning with latent space regularization. GRACE enforces two constraints: latent separation between safe and adversarial completions, and adversarial cohesion among unsafe and jailbreak behaviors. These operate over layerwise pooled embeddings guided by a learned attention profile, reshaping internal geometry without modifying the base model, and achieve up to 39% ASR reduction. Moreover, we introduce AVQI, a geometry aware metric that quantifies latent alignment failure via cluster separation and compactness. AVQI reveals when unsafe completions mimic the geometry of safe ones, offering a principled lens into how models internally encode safety. We make the code publicly available at https://anonymous.4open.science/r/alkali-B416/README.md.