 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPTIMA: Optimal One-shot Pruning for LLMs via Quadratic Programming Reconstruction
Dec 15, 2025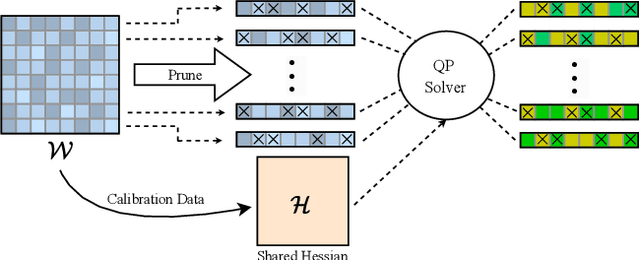
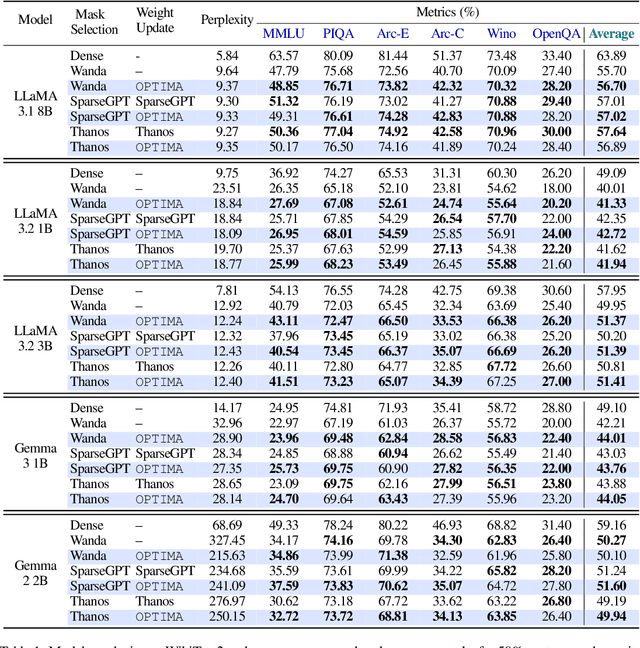
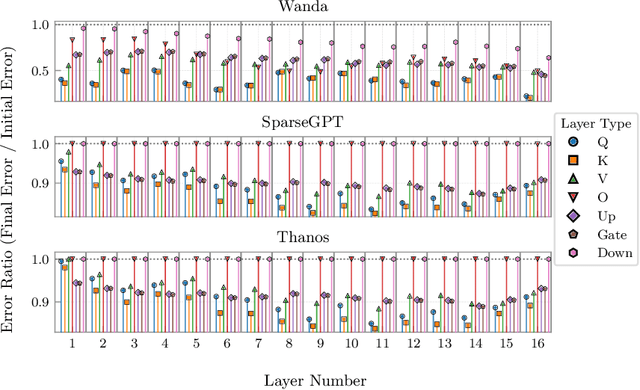
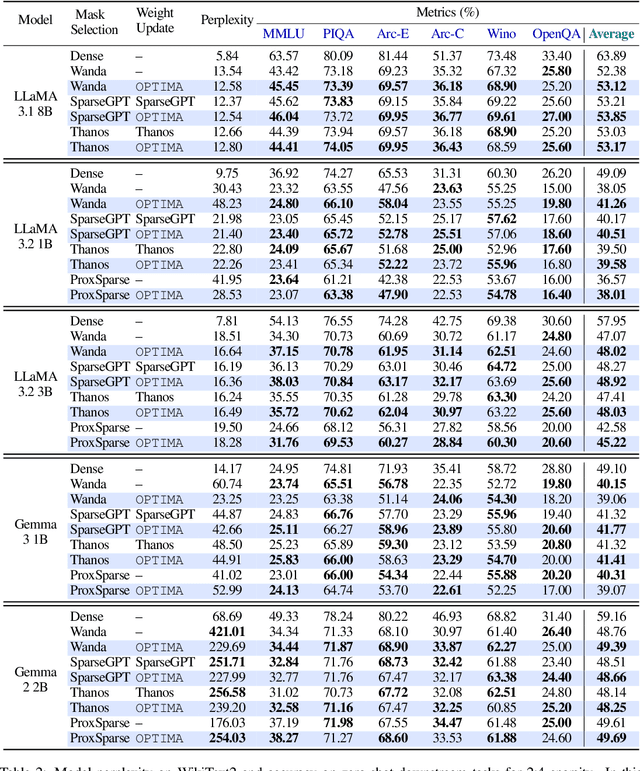
Post-training model pruning is a promising solution, yet it faces a trade-off: simple heuristics that zero weights are fast but degrade accuracy, while principled joint optimization methods recover accuracy but are computationally infeasible at modern scale. One-shot methods such as SparseGPT offer a practical trade-off in optimality by applying efficient, approximate heuristic weight updates. To close this gap, we introduce OPTIMA, a practical one-shot post-training pruning method that balances accuracy and scalability. OPTIMA casts layer-wise weight reconstruction after mask selection as independent, row-wise Quadratic Programs (QPs) that share a common layer Hessian. Solving these QPs yields the per-row globally optimal update with respect to the reconstruction objective given the estimated Hessian. The shared-Hessian structure makes the problem highly amenable to batching on accelerators. We implement an accelerator-friendly QP solver that accumulates one Hessian per layer and solves many small QPs in parallel, enabling one-shot post-training pruning at scale on a single accelerator without fine-tuning. OPTIMA integrates with existing mask selectors and consistently improves zero-shot performance across multiple LLM families and sparsity regimes, yielding up to 3.97% absolute accuracy improvement. On an NVIDIA H100, OPTIMA prunes a 8B-parameter transformer end-to-end in 40 hours with 60GB peak memory. Together, these results set a new state-of-the-art accuracy-efficiency trade-offs for one-shot post-training pruning.
Scaling 6G Subscribers with Fewer BS Antennas using Multi-carrier NOMA in Fixed Wireless Access
Oct 29, 2024This paper introduces a novel power allocation and subcarrier optimization algorithm tailored for fixed wireless access (FWA) networks operating under low-rank channel conditions, where the number of subscriber antennas far exceeds those at the base station (BS). As FWA networks grow to support more users, traditional approaches like orthogonal multiple access (OMA) and non-orthogonal multiple access (NOMA) struggle to maintain high data rates and energy efficiency due to the limited degrees of freedom in low-rank scenarios. Our proposed solution addresses this by combining optimal power-subcarrier allocation with an adaptive time-sharing algorithm that dynamically adjusts decoding orders to optimize performance across multiple users. The algorithm leverages a generalized decision feedback equalizer (GDFE) approach to effectively manage inter-symbol interference and crosstalk, leading to superior data rates and energy savings. Simulation results demonstrate that our approach significantly outperforms existing OMA and NOMA baselines, particularly in low-rank conditions, with substantial gains in both data rate and energy efficiency. The findings highlight the potential of this method to meet the growing demand for scalable, high-performance FWA networks.
SLiM: One-shot Quantized Sparse Plus Low-rank Approximation of LLMs
Oct 12, 2024



Large Language Models (LLMs) have revolutionized natural language understanding and generation tasks but suffer from high memory consumption and slow inference times due to their large parameter sizes. Traditional model compression techniques, such as quantization and pruning, mitigate these issues but often require retraining to maintain accuracy, which is computationally expensive. This paper introduces SLiM, a novel approach for compressing LLMs using a one-shot Quantized Sparse Plus Low-rank Approximation. SLiM eliminates the need for costly retraining by combining a symmetric quantization method (SLiM-Quant) with a saliency-based low-rank approximation. Our method reduces quantization error while leveraging sparse representations compatible with accelerated hardware architectures. Additionally, we propose a parameter-efficient fine-tuning recipe that significantly reduces overhead compared to conventional quantization-aware training. SLiM achieves up to a 5.4% improvement in model accuracy for sparsity patterns like 2:4, and the fine-tuning step further enhances accuracy by up to 5.8%, demonstrating state-of-the-art performance. This work provides a pathway for efficiently deploying large models in memory-constrained environments without compromising accuracy.
SLoPe: Double-Pruned Sparse Plus Lazy Low-Rank Adapter Pretraining of LLMs
May 25, 2024



We propose SLoPe, a Double-Pruned Sparse Plus Lazy Low-rank Adapter Pretraining method for LLMs that improves the accuracy of sparse LLMs while accelerating their pretraining and inference and reducing their memory footprint. Sparse pretraining of LLMs reduces the accuracy of the model, to overcome this, prior work uses dense models during fine-tuning. SLoPe improves the accuracy of sparsely pretrained models by adding low-rank adapters in the final 1% iterations of pretraining without adding significant overheads to the model pretraining and inference. In addition, SLoPe uses a double-pruned backward pass formulation that prunes the transposed weight matrix using N:M sparsity structures to enable an accelerated sparse backward pass. SLoPe accelerates the training and inference of models with billions of parameters up to $1.14\times$ and $1.34\times$ respectively (OPT-33B and OPT-66B) while reducing their memory usage by up to $0.77\times$ and $0.51\times$ for training and inference respectively.
Towards Green Communication: Soft Decoding Scheme for OOK Signals in Zero-Energy Devices
May 03, 2024The booming of Internet-of-Things (IoT) is expected to provide more intelligent and reliable communication services for higher network coverage, massive connectivity, and low-cost solutions for 6G services. However, frequent charging and battery replacement of these massive IoT devices brings a series of challenges. Zero energy devices, which rely on energy-harvesting technologies and can operate without battery replacement or charging, play a pivotal role in facilitating the massive use of IoT devices. In order to enable reliable communications of such low-power devices, Manchester-coded on-off keying (OOK) modulation and non-coherent detections are attractive techniques due to their energy efficiency, robustness in noisy environments, and simplicity in receiver design. Moreover, to extend their communication range, employing channel coding along with enhanced detection schemes is crucial. In this paper, a novel soft-decision decoder is designed for OOK-based low-power receivers to enhance their detection performance. In addition, exact closed-form expressions and two simplified approximations are derived for the log-likelihood ratio (LLR), an essential metric for soft decoding. Numerical results demonstrate the significant coverage gain achieved through soft decoding for convolutional code.
MKOR: Momentum-Enabled Kronecker-Factor-Based Optimizer Using Rank-1 Updates
Jun 02, 2023



This work proposes a Momentum-Enabled Kronecker-Factor-Based Optimizer Using Rank-1 updates, called MKOR, that improves the training time and convergence properties of deep neural networks (DNNs). Second-order techniques, while enjoying higher convergence rates vs first-order counterparts, have cubic complexity with respect to either the model size and/or the training batch size. Hence they exhibit poor scalability and performance in transformer models, e.g. large language models (LLMs), because the batch sizes in these models scale by the attention mechanism sequence length, leading to large model size and batch sizes. MKOR's complexity is quadratic with respect to the model size, alleviating the computation bottlenecks in second-order methods. Because of their high computation complexity, state-of-the-art implementations of second-order methods can only afford to update the second order information infrequently, and thus do not fully exploit the promise of better convergence from these updates. By reducing the communication complexity of the second-order updates as well as achieving a linear communication complexity, MKOR increases the frequency of second order updates. We also propose a hybrid version of MKOR (called MKOR-H) that mid-training falls backs to a first order optimizer if the second order updates no longer accelerate convergence. Our experiments show that MKOR outperforms state -of-the-art first order methods, e.g. the LAMB optimizer, and best implementations of second-order methods, i.e. KAISA/KFAC, up to 2.57x and 1.85x respectively on BERT-Large-Uncased on 64 GPUs.
Green, Quantized Federated Learning over Wireless Networks: An Energy-Efficient Design
Jul 19, 2022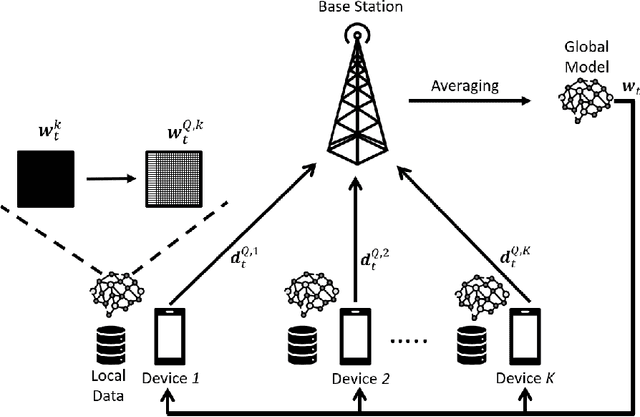
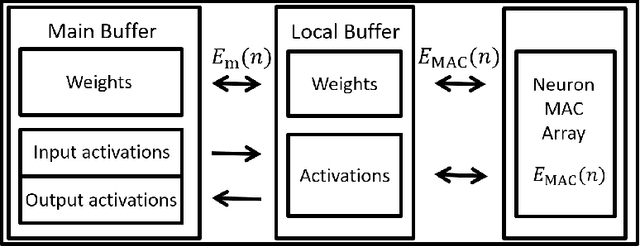
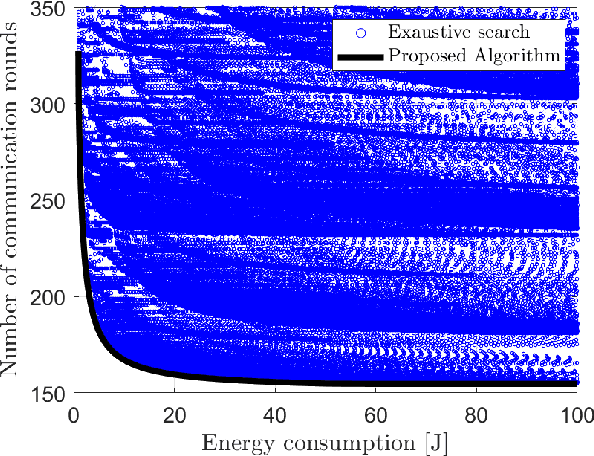
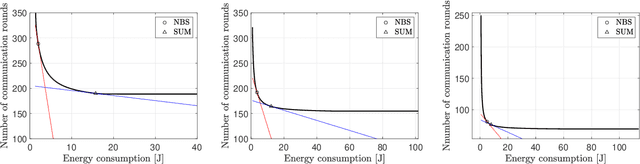
In this paper, a green, quantized FL framework, which represents data with a finite precision level in both local training and uplink transmission, is proposed. Here, the finite precision level is captured through the use of quantized neural networks (QNNs) that quantize weights and activations in fixed-precision format. In the considered FL model, each device trains its QNN and transmits a quantized training result to the base station. Energy models for the local training and the transmission with quantization are rigorously derived. To minimize the energy consumption and the number of communication rounds simultaneously, a multi-objective optimization problem is formulated with respect to the number of local iterations, the number of selected devices, and the precision levels for both local training and transmission while ensuring convergence under a target accuracy constraint. To solve this problem, the convergence rate of the proposed FL system is analytically derived with respect to the system control variables. Then, the Pareto boundary of the problem is characterized to provide efficient solutions using the normal boundary inspection method. Design insights on balancing the tradeoff between the two objectives are drawn from using the Nash bargaining solution and analyzing the derived convergence rate. Simulation results show that the proposed FL framework can reduce energy consumption until convergence by up to 52% compared to a baseline FL algorithm that represents data with full precision.
On the Tradeoff between Energy, Precision, and Accuracy in Federated Quantized Neural Networks
Nov 17, 2021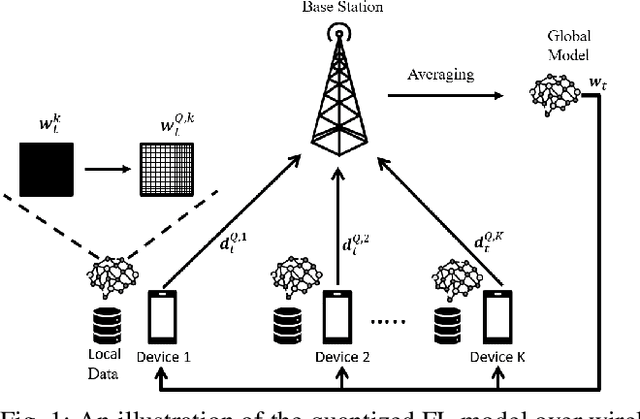
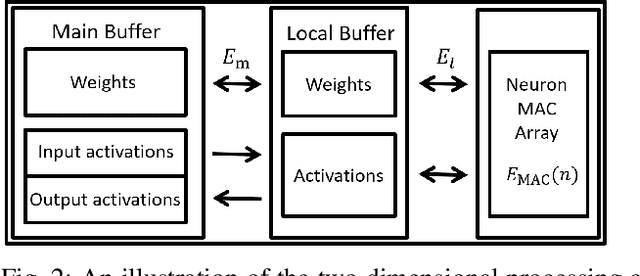
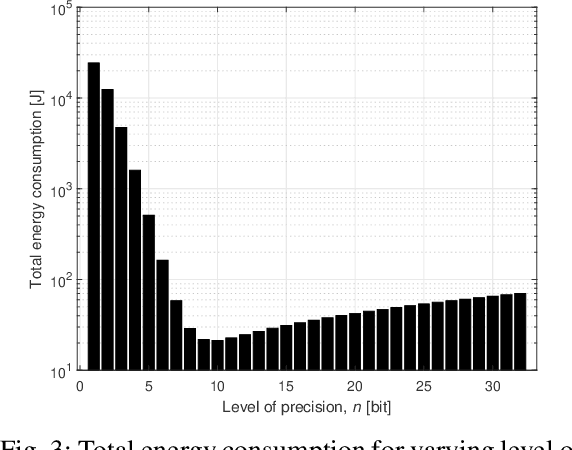
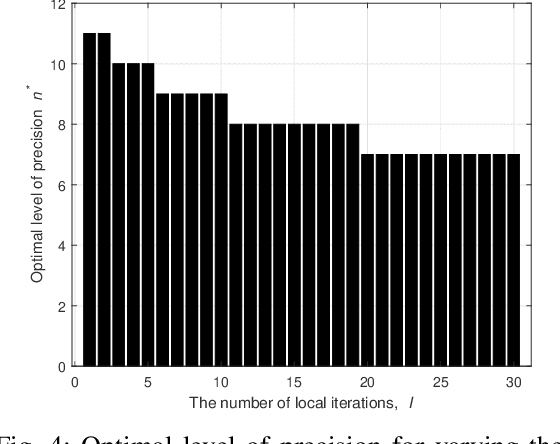
Deploying federated learning (FL) over wireless networks with resource-constrained devices requires balancing between accuracy, energy efficiency, and precision. Prior art on FL often requires devices to train deep neural networks (DNNs) using a 32-bit precision level for data representation to improve accuracy. However, such algorithms are impractical for resource-constrained devices since DNNs could require execution of millions of operations. Thus, training DNNs with a high precision level incurs a high energy cost for FL. In this paper, a quantized FL framework, that represents data with a finite level of precision in both local training and uplink transmission, is proposed. Here, the finite level of precision is captured through the use of quantized neural networks (QNNs) that quantize weights and activations in fixed-precision format. In the considered FL model, each device trains its QNN and transmits a quantized training result to the base station. Energy models for the local training and the transmission with the quantization are rigorously derived. An energy minimization problem is formulated with respect to the level of precision while ensuring convergence. To solve the problem, we first analytically derive the FL convergence rate and use a line search method. Simulation results show that our FL framework can reduce energy consumption by up to 53% compared to a standard FL model. The results also shed light on the tradeoff between precision, energy, and accuracy in FL over wireless networks.
A Deep Reinforcement Learning Approach to Efficient Drone Mobility Support
May 11, 2020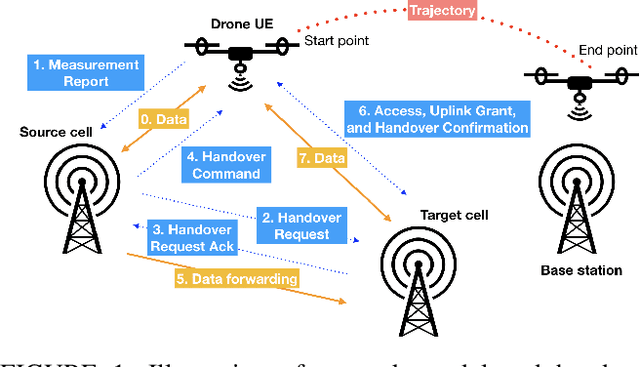
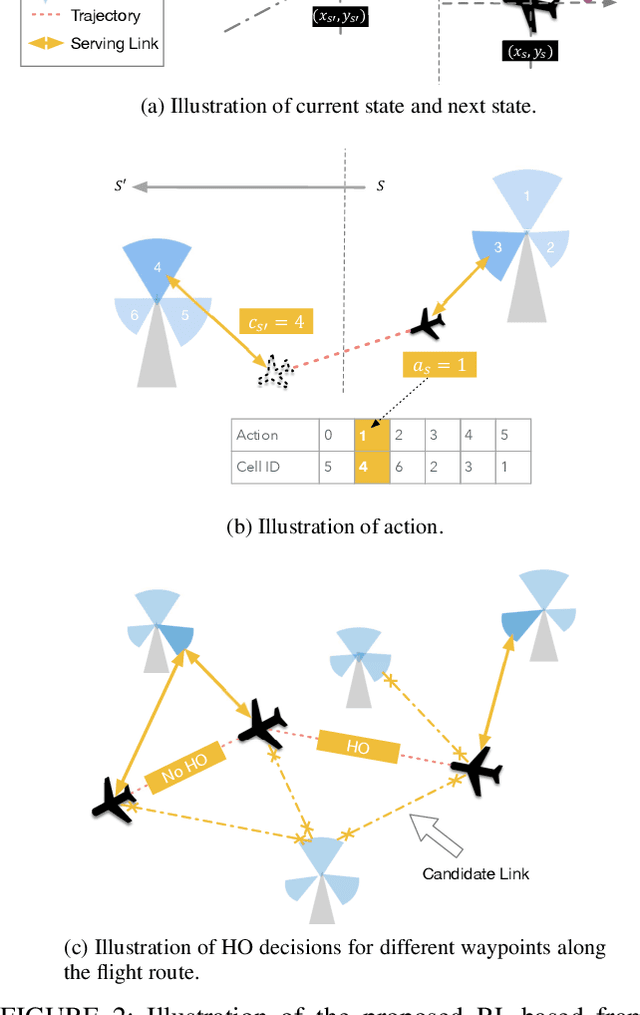
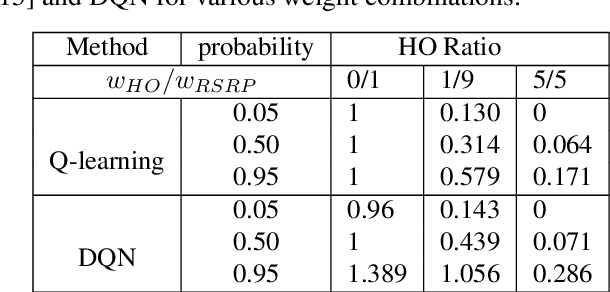
The growing deployment of drones in a myriad of applications relies on seamless and reliable wireless connectivity for safe control and operation of drones. Cellular technology is a key enabler for providing essential wireless services to flying drones in the sky. Existing cellular networks targeting terrestrial usage can support the initial deployment of low-altitude drone users, but there are challenges such as mobility support. In this paper, we propose a novel handover framework for providing efficient mobility support and reliable wireless connectivity to drones served by a terrestrial cellular network. Using tools from deep reinforcement learning, we develop a deep Q-learning algorithm to dynamically optimize handover decisions to ensure robust connectivity for drone users. Simulation results show that the proposed framework significantly reduces the number of handovers at the expense of a small loss in signal strength relative to the baseline case where a drone always connect to a base station that provides the strongest received signal strength.
Federated Learning in the Sky: Joint Power Allocation and Scheduling with UAV Swarms
Feb 19, 2020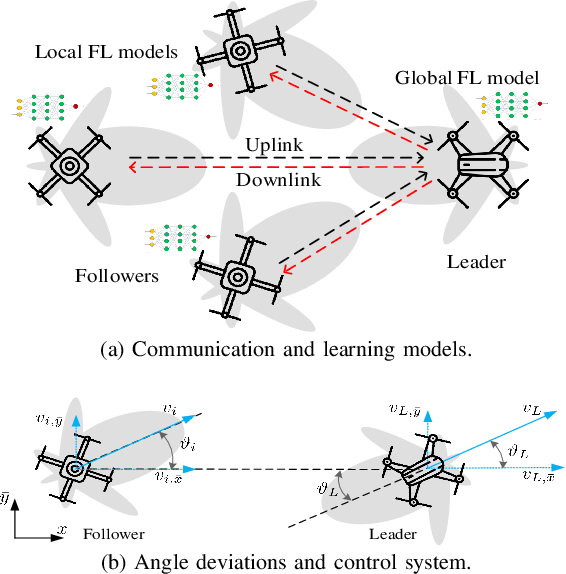
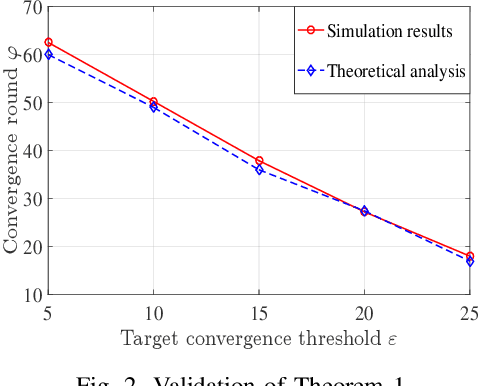

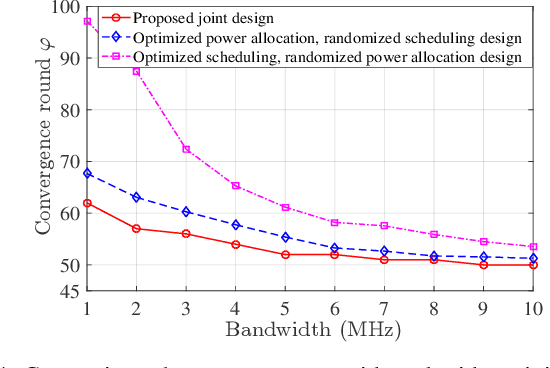
Unmanned aerial vehicle (UAV) swarms must exploit machine learning (ML) in order to execute various tasks ranging from coordinated trajectory planning to cooperative target recognition. However, due to the lack of continuous connections between the UAV swarm and ground base stations (BSs), using centralized ML will be challenging, particularly when dealing with a large volume of data. In this paper, a novel framework is proposed to implement distributed federated learning (FL) algorithms within a UAV swarm that consists of a leading UAV and several following UAVs. Each following UAV trains a local FL model based on its collected data and then sends this trained local model to the leading UAV who will aggregate the received models, generate a global FL model, and transmit it to followers over the intra-swarm network. To identify how wireless factors, like fading, transmission delay, and UAV antenna angle deviations resulting from wind and mechanical vibrations, impact the performance of FL, a rigorous convergence analysis for FL is performed. Then, a joint power allocation and scheduling design is proposed to optimize the convergence rate of FL while taking into account the energy consumption during convergence and the delay requirement imposed by the swarm's control system. Simulation results validate the effectiveness of the FL convergence analysis and show that the joint design strategy can reduce the number of communication rounds needed for convergence by as much as 35% compared with the baseline design.