 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Tradeoff between Energy, Precision, and Accuracy in Federated Quantized Neural Networks
Paper and Code
Nov 17, 2021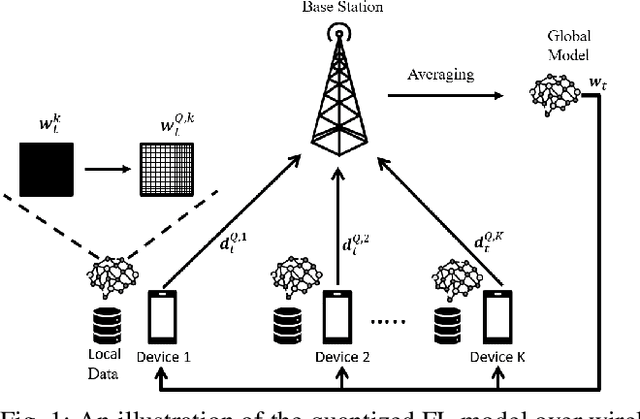
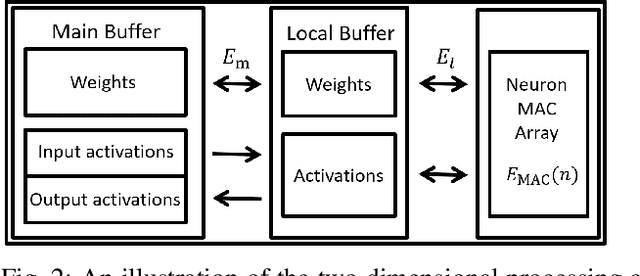
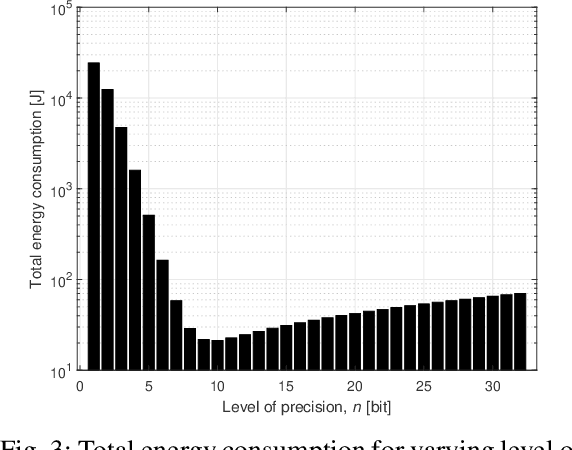
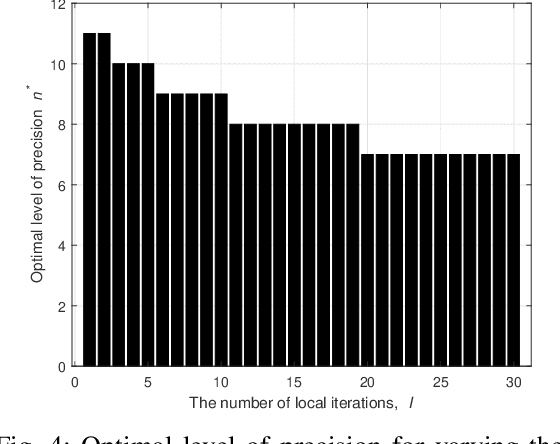
Deploying federated learning (FL) over wireless networks with resource-constrained devices requires balancing between accuracy, energy efficiency, and precision. Prior art on FL often requires devices to train deep neural networks (DNNs) using a 32-bit precision level for data representation to improve accuracy. However, such algorithms are impractical for resource-constrained devices since DNNs could require execution of millions of operations. Thus, training DNNs with a high precision level incurs a high energy cost for FL. In this paper, a quantized FL framework, that represents data with a finite level of precision in both local training and uplink transmission, is proposed. Here, the finite level of precision is captured through the use of quantized neural networks (QNNs) that quantize weights and activations in fixed-precision format. In the considered FL model, each device trains its QNN and transmits a quantized training result to the base station. Energy models for the local training and the transmission with the quantization are rigorously derived. An energy minimization problem is formulated with respect to the level of precision while ensuring convergence. To solve the problem, we first analytically derive the FL convergence rate and use a line search method. Simulation results show that our FL framework can reduce energy consumption by up to 53% compared to a standard FL model. The results also shed light on the tradeoff between precision, energy, and accuracy in FL over wireless networks.