 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegVQA: Can Vision Language Models Understand Negation?
May 28, 2025Negation is a fundamental linguistic phenomenon that can entirely reverse the meaning of a sentence. As vision language models (VLMs) continue to advance and are deployed in high-stakes applications, assessing their ability to comprehend negation becomes essential. To address this, we introduce NegVQA, a visual question answering (VQA) benchmark consisting of 7,379 two-choice questions covering diverse negation scenarios and image-question distributions. We construct NegVQA by leveraging large language models to generate negated versions of questions from existing VQA datasets. Evaluating 20 state-of-the-art VLMs across seven model families, we find that these models struggle significantly with negation, exhibiting a substantial performance drop compared to their responses to the original questions. Furthermore, we uncover a U-shaped scaling trend, where increasing model size initially degrades performance on NegVQA before leading to improvements. Our benchmark reveals critical gaps in VLMs' negation understanding and offers insights into future VLM development. Project page available at https://yuhui-zh15.github.io/NegVQA/.
MicroVQA: A Multimodal Reasoning Benchmark for Microscopy-Based Scientific Research
Mar 17, 2025Scientific research demands sophisticated reasoning over multimodal data, a challenge especially prevalent in biology. Despite recent advances in multimodal large language models (MLLMs) for AI-assisted research, existing multimodal reasoning benchmarks only target up to college-level difficulty, while research-level benchmarks emphasize lower-level perception, falling short of the complex multimodal reasoning needed for scientific discovery. To bridge this gap, we introduce MicroVQA, a visual-question answering (VQA) benchmark designed to assess three reasoning capabilities vital in research workflows: expert image understanding, hypothesis generation, and experiment proposal. MicroVQA consists of 1,042 multiple-choice questions (MCQs) curated by biology experts across diverse microscopy modalities, ensuring VQA samples represent real scientific practice. In constructing the benchmark, we find that standard MCQ generation methods induce language shortcuts, motivating a new two-stage pipeline: an optimized LLM prompt structures question-answer pairs into MCQs; then, an agent-based `RefineBot' updates them to remove shortcuts. Benchmarking on state-of-the-art MLLMs reveal a peak performance of 53\%; models with smaller LLMs only slightly underperform top models, suggesting that language-based reasoning is less challenging than multimodal reasoning; and tuning with scientific articles enhances performance. Expert analysis of chain-of-thought responses shows that perception errors are the most frequent, followed by knowledge errors and then overgeneralization errors. These insights highlight the challenges in multimodal scientific reasoning, showing MicroVQA is a valuable resource advancing AI-driven biomedical research. MicroVQA is available at https://huggingface.co/datasets/jmhb/microvqa, and project page at https://jmhb0.github.io/microvqa.
Automated Generation of Challenging Multiple-Choice Questions for Vision Language Model Evaluation
Jan 06, 2025



The rapid development of vision language models (VLMs) demands rigorous and reliable evaluation. However, current visual question answering (VQA) benchmarks often depend on open-ended questions, making accurate evaluation difficult due to the variability in natural language responses. To address this, we introduce AutoConverter, an agentic framework that automatically converts these open-ended questions into multiple-choice format, enabling objective evaluation while reducing the costly question creation process. Our experiments demonstrate that AutoConverter can generate correct and challenging multiple-choice questions, with VLMs demonstrating consistently similar or lower accuracy on these questions compared to human-created ones. Using AutoConverter, we construct VMCBench, a benchmark created by transforming 20 existing VQA datasets into a unified multiple-choice format, totaling 9,018 questions. We comprehensively evaluate 33 state-of-the-art VLMs on VMCBench, setting a new standard for scalable, consistent, and reproducible VLM evaluation.
Multimodal Generalized Category Discovery
Sep 18, 2024



Generalized Category Discovery (GCD) aims to classify inputs into both known and novel categories, a task crucial for open-world scientific discoveries. However, current GCD methods are limited to unimodal data, overlooking the inherently multimodal nature of most real-world data. In this work, we extend GCD to a multimodal setting, where inputs from different modalities provide richer and complementary information. Through theoretical analysis and empirical validation, we identify that the key challenge in multimodal GCD lies in effectively aligning heterogeneous information across modalities. To address this, we propose MM-GCD, a novel framework that aligns both the feature and output spaces of different modalities using contrastive learning and distillation techniques. MM-GCD achieves new state-of-the-art performance on the UPMC-Food101 and N24News datasets, surpassing previous methods by 11.5\% and 4.7\%, respectively.
Why are Visually-Grounded Language Models Bad at Image Classification?
May 28, 2024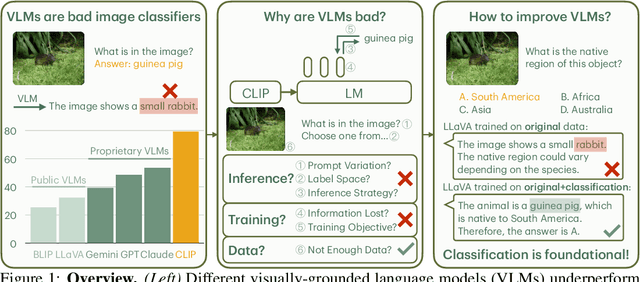
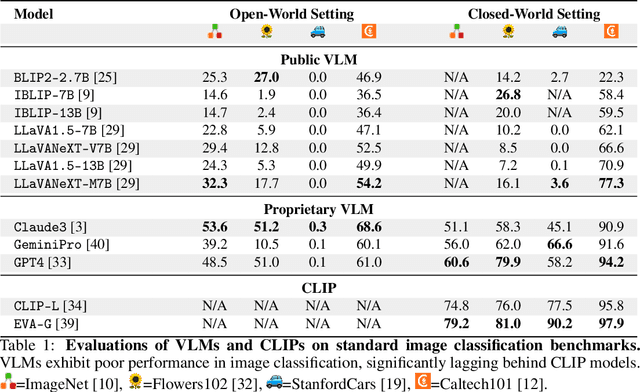
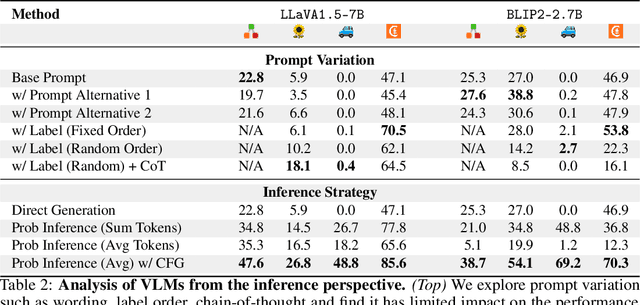
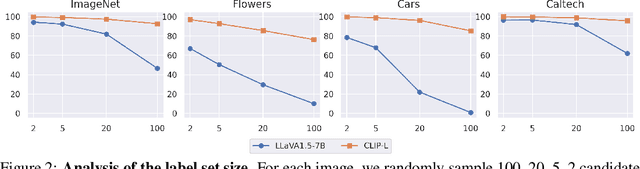
Image classification is one of the most fundamental capabilities of machine vision intelligence. In this work, we revisit the image classification task using visually-grounded language models (VLMs) such as GPT-4V and LLaVA. We find that existing proprietary and public VLMs, despite often using CLIP as a vision encoder and having many more parameters, significantly underperform CLIP on standard image classification benchmarks like ImageNet. To understand the reason, we explore several hypotheses concerning the inference algorithms, training objectives, and data processing in VLMs. Our analysis reveals that the primary cause is data-related: critical information for image classification is encoded in the VLM's latent space but can only be effectively decoded with enough training data. Specifically, there is a strong correlation between the frequency of class exposure during VLM training and instruction-tuning and the VLM's performance in those classes; when trained with sufficient data, VLMs can match the accuracy of state-of-the-art classification models. Based on these findings, we enhance a VLM by integrating classification-focused datasets into its training, and demonstrate that the enhanced classification performance of the VLM transfers to its general capabilities, resulting in an improvement of 11.8% on the newly collected ImageWikiQA dataset.