 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Federated Learning Using Dynamic Update and Adaptive Pruning with Momentum on Shared Server Data
Paper and Code
Aug 11, 2024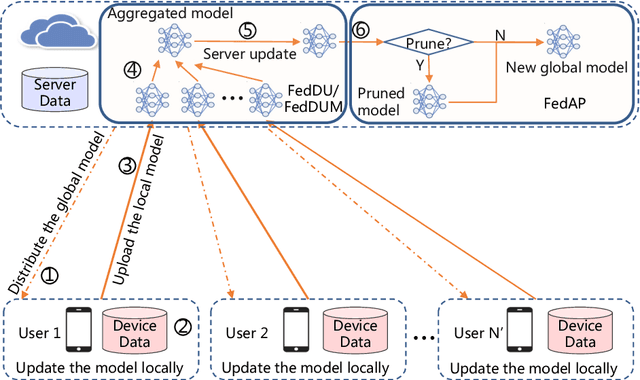

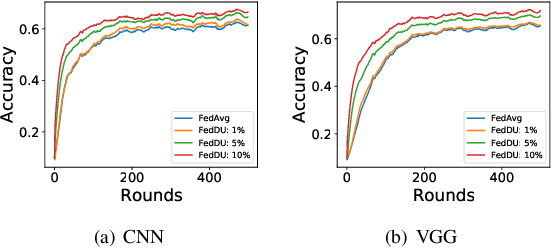
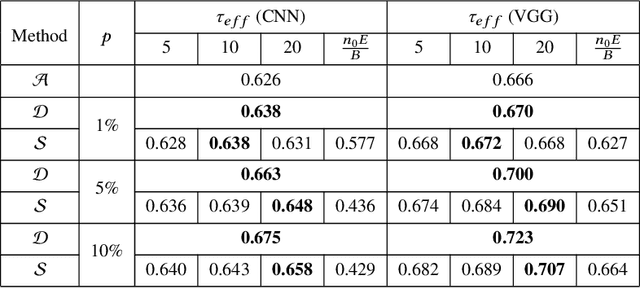
Despite achieving remarkable performance, Federated Learning (FL) encounters two important problems, i.e., low training efficiency and limited computational resources. In this paper, we propose a new FL framework, i.e., FedDUMAP, with three original contributions, to leverage the shared insensitive data on the server in addition to the distributed data in edge devices so as to efficiently train a global model. First, we propose a simple dynamic server update algorithm, which takes advantage of the shared insensitive data on the server while dynamically adjusting the update steps on the server in order to speed up the convergence and improve the accuracy. Second, we propose an adaptive optimization method with the dynamic server update algorithm to exploit the global momentum on the server and each local device for superior accuracy. Third, we develop a layer-adaptive model pruning method to carry out specific pruning operations, which is adapted to the diverse features of each layer so as to attain an excellent trade-off between effectiveness and efficiency. Our proposed FL model, FedDUMAP, combines the three original techniques and has a significantly better performance compared with baseline approaches in terms of efficiency (up to 16.9 times faster), accuracy (up to 20.4% higher), and computational cost (up to 62.6% smaller).