 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025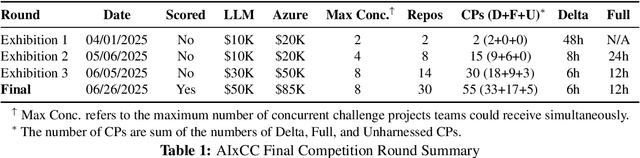
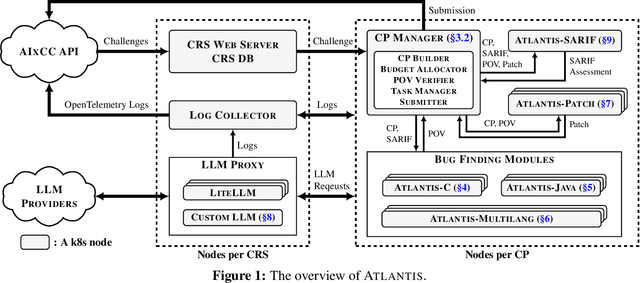
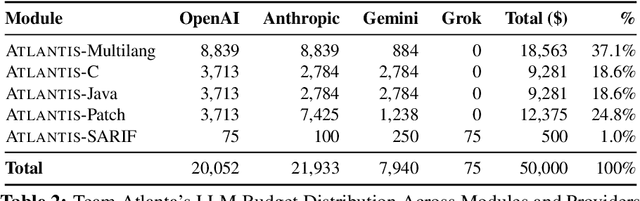
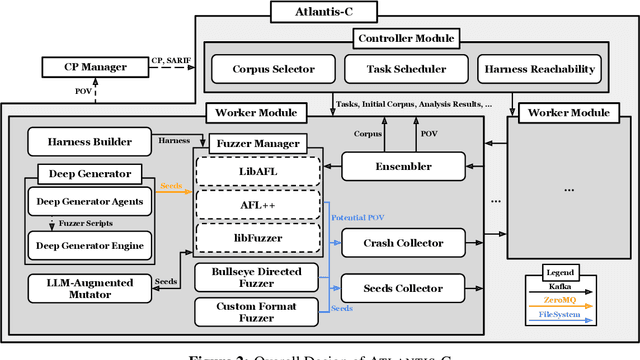
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
MUG-Eval: A Proxy Evaluation Framework for Multilingual Generation Capabilities in Any Language
May 20, 2025Evaluating text generation capabilities of large language models (LLMs) is challenging, particularly for low-resource languages where methods for direct assessment are scarce. We propose MUG-Eval, a novel framework that evaluates LLMs' multilingual generation capabilities by transforming existing benchmarks into conversational tasks and measuring the LLMs' accuracies on those tasks. We specifically designed these conversational tasks to require effective communication in the target language. Then, we simply use task success rate as a proxy of successful conversation generation. Our approach offers two key advantages: it is independent of language-specific NLP tools or annotated datasets, which are limited for most languages, and it does not rely on LLMs-as-judges, whose evaluation quality degrades outside a few high-resource languages. We evaluate 8 LLMs across 30 languages spanning high, mid, and low-resource categories, and we find that MUG-Eval correlates strongly with established benchmarks ($r$ > 0.75) while enabling standardized comparisons across languages and models. Our framework provides a robust and resource-efficient solution for evaluating multilingual generation that can be extended to thousands of languages.
LLM-AS-AN-INTERVIEWER: Beyond Static Testing Through Dynamic LLM Evaluation
Dec 10, 2024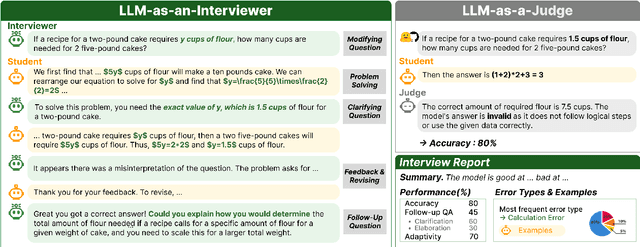
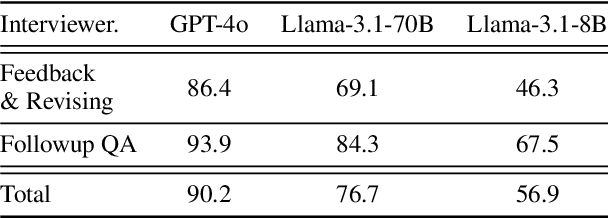
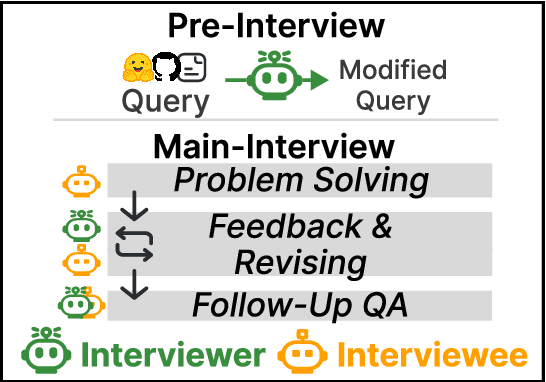
We introduce a novel evaluation paradigm for large language models (LLMs), LLM-as-an-Interviewer. This approach consists of a two stage process designed to assess the true capabilities of LLMs: first, modifying benchmark datasets to generate initial queries, and second, interacting with the LLM through feedback and follow up questions. Compared to existing evaluation methods such as LLM as a Judge, our framework addresses several limitations, including data contamination, verbosity bias, and self enhancement bias. Additionally, we show that our multi turn evaluation process provides valuable insights into the LLM's performance in real-world scenarios, including its adaptability to feedback and its ability to handle follow up questions, including clarification or requests for additional knowledge. Finally, we propose the Interview Report, which offers a comprehensive reflection of an LLM's strengths and weaknesses, illustrated with specific examples from the interview process. This report delivers a snapshot of the LLM's capabilities, providing a detailed picture of its practical performance.
Generalizing Weisfeiler-Lehman Kernels to Subgraphs
Dec 03, 2024Subgraph representation learning has been effective in solving various real-world problems. However, current graph neural networks (GNNs) produce suboptimal results for subgraph-level tasks due to their inability to capture complex interactions within and between subgraphs. To provide a more expressive and efficient alternative, we propose WLKS, a Weisfeiler-Lehman (WL) kernel generalized for subgraphs by applying the WL algorithm on induced $k$-hop neighborhoods. We combine kernels across different $k$-hop levels to capture richer structural information that is not fully encoded in existing models. Our approach can balance expressiveness and efficiency by eliminating the need for neighborhood sampling. In experiments on eight real-world and synthetic benchmarks, WLKS significantly outperforms leading approaches on five datasets while reducing training time, ranging from 0.01x to 0.25x compared to the state-of-the-art.
Perceptions to Beliefs: Exploring Precursory Inferences for Theory of Mind in Large Language Models
Jul 09, 2024While humans naturally develop theory of mind (ToM), the capability to understand other people's mental states and beliefs, state-of-the-art large language models (LLMs) underperform on simple ToM benchmarks. We posit that we can extend our understanding of LLMs' ToM abilities by evaluating key human ToM precursors -- perception inference and perception-to-belief inference -- in LLMs. We introduce two datasets, Percept-ToMi and Percept-FANToM, to evaluate these precursory inferences for ToM in LLMs by annotating characters' perceptions on ToMi and FANToM, respectively. Our evaluation of eight state-of-the-art LLMs reveals that the models generally perform well in perception inference while exhibiting limited capability in perception-to-belief inference (e.g., lack of inhibitory control). Based on these results, we present PercepToM, a novel ToM method leveraging LLMs' strong perception inference capability while supplementing their limited perception-to-belief inference. Experimental results demonstrate that PercepToM significantly enhances LLM's performance, especially in false belief scenarios.
How to Find Your Friendly Neighborhood: Graph Attention Design with Self-Supervision
Apr 11, 2022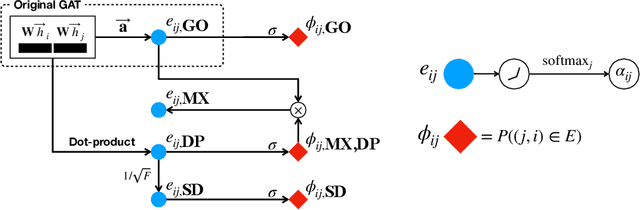
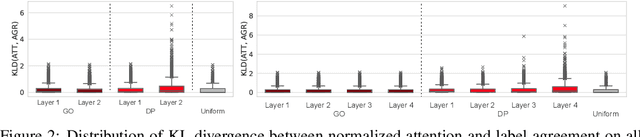
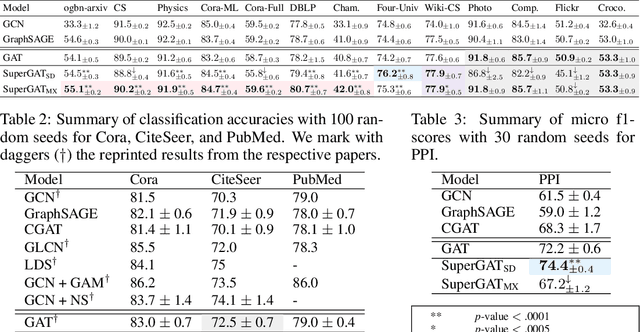

Attention mechanism in graph neural networks is designed to assign larger weights to important neighbor nodes for better representation. However, what graph attention learns is not understood well, particularly when graphs are noisy. In this paper, we propose a self-supervised graph attention network (SuperGAT), an improved graph attention model for noisy graphs. Specifically, we exploit two attention forms compatible with a self-supervised task to predict edges, whose presence and absence contain the inherent information about the importance of the relationships between nodes. By encoding edges, SuperGAT learns more expressive attention in distinguishing mislinked neighbors. We find two graph characteristics influence the effectiveness of attention forms and self-supervision: homophily and average degree. Thus, our recipe provides guidance on which attention design to use when those two graph characteristics are known. Our experiment on 17 real-world datasets demonstrates that our recipe generalizes across 15 datasets of them, and our models designed by recipe show improved performance over baselines.
Efficient Representation Learning of Subgraphs by Subgraph-To-Node Translation
Apr 09, 2022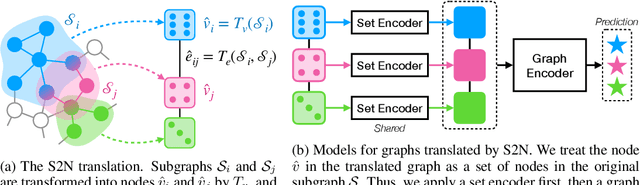



A subgraph is a data structure that can represent various real-world problems. We propose Subgraph-To-Node (S2N) translation, which is a novel formulation to efficiently learn representations of subgraphs. Specifically, given a set of subgraphs in the global graph, we construct a new graph by coarsely transforming subgraphs into nodes. We perform subgraph-level tasks as node-level tasks through this translation. By doing so, we can significantly reduce the memory and computational costs in both training and inference. We conduct experiments on four real-world datasets to evaluate performance and efficiency. Our experiments demonstrate that models with S2N translation are more efficient than state-of-the-art models without substantial performance decrease.
Homogeneity-Based Transmissive Process to Model True and False News in Social Networks
Nov 16, 2018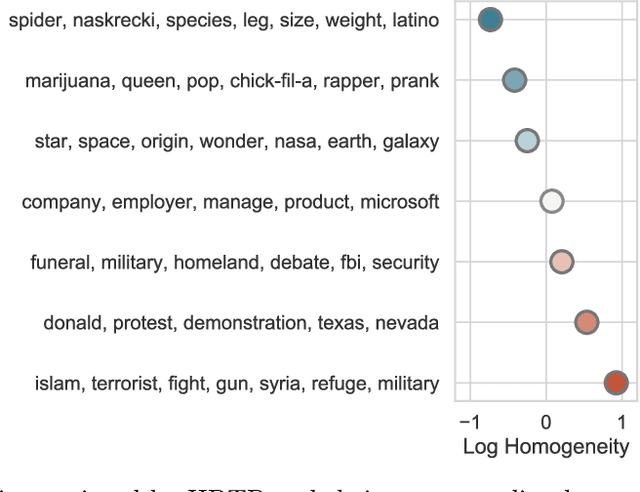
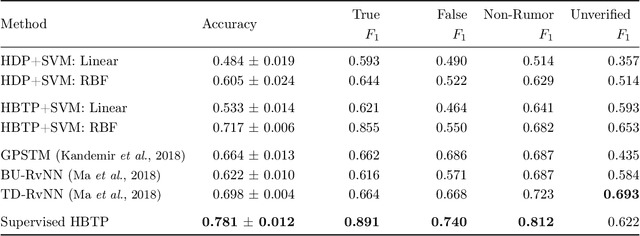

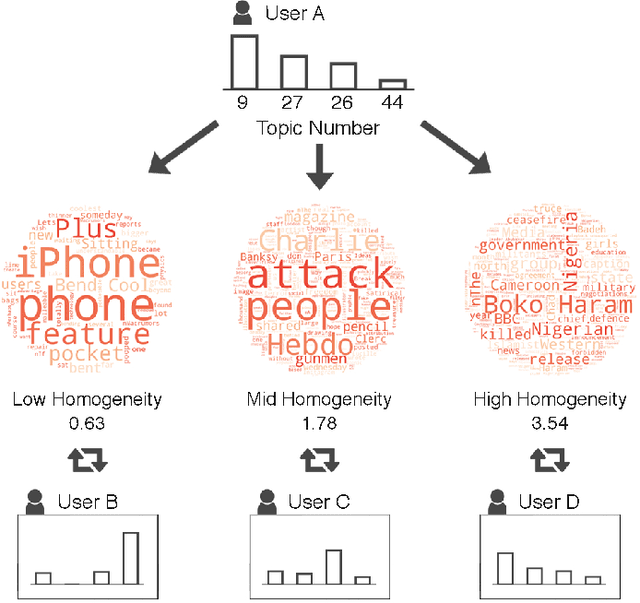
An overwhelming number of true and false news stories are posted and shared in social networks, and users diffuse the stories based on multiple factors. Diffusion of news stories from one user to another depends not only on the stories' content and the genuineness but also on the alignment of the topical interests between the users. In this paper, we propose a novel Bayesian nonparametric model that incorporates homogeneity of news stories as the key component that regulates the topical similarity between the posting and sharing users' topical interests. Our model extends hierarchical Dirichlet process to model the topics of the news stories and incorporates Bayesian Gaussian process latent variable model to discover the homogeneity values. We train our model on a real-world social network dataset and find homogeneity values of news stories that strongly relate to their labels of genuineness and their contents. Finally, we show that the supervised version of our model predicts the labels of news stories better than the state-of-the-art neural network and Bayesian models.