 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodPoint: Learning Constructive Scientific Paper Feedback from Author Responses
Apr 13, 2026While LLMs hold significant potential to transform scientific research, we advocate for their use to augment and empower researchers rather than to automate research without human oversight. To this end, we study constructive feedback generation, the task of producing targeted, actionable feedback that helps authors improve both their research and its presentation. In this work, we operationalize the effectiveness of feedback along two author-centric axes-validity and author action. We first curate GoodPoint-ICLR, a dataset of 19K ICLR papers with reviewer feedback annotated along both dimensions using author responses. Building on this, we introduce GoodPoint, a training recipe that leverages success signals from author responses through fine-tuning on valid and actionable feedback, together with preference optimization on both real and synthetic preference pairs. Our evaluation on a benchmark of 1.2K ICLR papers shows that a GoodPoint-trained Qwen3-8B improves the predicted success rate by 83.7% over the base model and sets a new state-of-the-art among LLMs of similar size in feedback matching on a golden human feedback set, even surpassing Gemini-3-flash in precision. We further validate these findings through an expert human study, demonstrating that GoodPoint consistently delivers higher practical value as perceived by authors.
FINEST: Improving LLM Responses to Sensitive Topics Through Fine-Grained Evaluation
Mar 04, 2026Large Language Models (LLMs) often generate overly cautious and vague responses on sensitive topics, sacrificing helpfulness for safety. Existing evaluation frameworks lack systematic methods to identify and address specific weaknesses in responses to sensitive topics, making it difficult to improve both safety and helpfulness simultaneously. To address this, we introduce FINEST, a FINE-grained response evaluation taxonomy for Sensitive Topics, which breaks down helpfulness and harmlessness into errors across three main categories: Content, Logic, and Appropriateness. Experiments on a Korean-sensitive question dataset demonstrate that our score- and error-based improvement pipeline, guided by FINEST, significantly improves the model responses across all three categories, outperforming refinement without guidance. Notably, score-based improvement -- providing category-specific scores and justifications -- yields the most significant gains, reducing the error sentence ratio for Appropriateness by up to 33.09%. This work lays the foundation for a more explainable and comprehensive evaluation and improvement of LLM responses to sensitive questions.
Perceptions to Beliefs: Exploring Precursory Inferences for Theory of Mind in Large Language Models
Jul 09, 2024While humans naturally develop theory of mind (ToM), the capability to understand other people's mental states and beliefs, state-of-the-art large language models (LLMs) underperform on simple ToM benchmarks. We posit that we can extend our understanding of LLMs' ToM abilities by evaluating key human ToM precursors -- perception inference and perception-to-belief inference -- in LLMs. We introduce two datasets, Percept-ToMi and Percept-FANToM, to evaluate these precursory inferences for ToM in LLMs by annotating characters' perceptions on ToMi and FANToM, respectively. Our evaluation of eight state-of-the-art LLMs reveals that the models generally perform well in perception inference while exhibiting limited capability in perception-to-belief inference (e.g., lack of inhibitory control). Based on these results, we present PercepToM, a novel ToM method leveraging LLMs' strong perception inference capability while supplementing their limited perception-to-belief inference. Experimental results demonstrate that PercepToM significantly enhances LLM's performance, especially in false belief scenarios.
CReHate: Cross-cultural Re-annotation of English Hate Speech Dataset
Aug 31, 2023


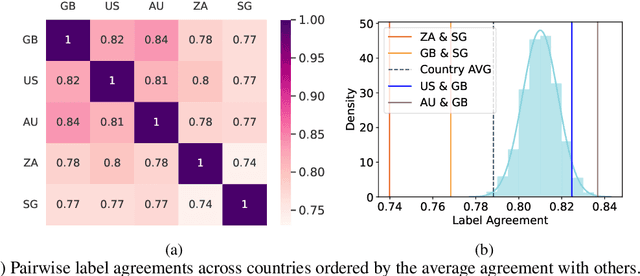
English datasets predominantly reflect the perspectives of certain nationalities, which can lead to cultural biases in models and datasets. This is particularly problematic in tasks heavily influenced by subjectivity, such as hate speech detection. To delve into how individuals from different countries perceive hate speech, we introduce CReHate, a cross-cultural re-annotation of the sampled SBIC dataset. This dataset includes annotations from five distinct countries: Australia, Singapore, South Africa, the United Kingdom, and the United States. Our thorough statistical analysis highlights significant differences based on nationality, with only 59.4% of the samples achieving consensus among all countries. We also introduce a culturally sensitive hate speech classifier via transfer learning, adept at capturing perspectives of different nationalities. These findings underscore the need to re-evaluate certain aspects of NLP research, especially with regard to the nuanced nature of hate speech in the English language.