 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniForensics: Face Forgery Detection via General Facial Representation
Jul 26, 2024



Previous deepfake detection methods mostly depend on low-level textural features vulnerable to perturbations and fall short of detecting unseen forgery methods. In contrast, high-level semantic features are less susceptible to perturbations and not limited to forgery-specific artifacts, thus having stronger generalization. Motivated by this, we propose a detection method that utilizes high-level semantic features of faces to identify inconsistencies in temporal domain. We introduce UniForensics, a novel deepfake detection framework that leverages a transformer-based video classification network, initialized with a meta-functional face encoder for enriched facial representation. In this way, we can take advantage of both the powerful spatio-temporal model and the high-level semantic information of faces. Furthermore, to leverage easily accessible real face data and guide the model in focusing on spatio-temporal features, we design a Dynamic Video Self-Blending (DVSB) method to efficiently generate training samples with diverse spatio-temporal forgery traces using real facial videos. Based on this, we advance our framework with a two-stage training approach: The first stage employs a novel self-supervised contrastive learning, where we encourage the network to focus on forgery traces by impelling videos generated by the same forgery process to have similar representations. On the basis of the representation learned in the first stage, the second stage involves fine-tuning on face forgery detection dataset to build a deepfake detector. Extensive experiments validates that UniForensics outperforms existing face forgery methods in generalization ability and robustness. In particular, our method achieves 95.3\% and 77.2\% cross dataset AUC on the challenging Celeb-DFv2 and DFDC respectively.
HeadText: Exploring Hands-free Text Entry using Head Gestures by Motion Sensing on a Smart Earpiece
May 23, 2022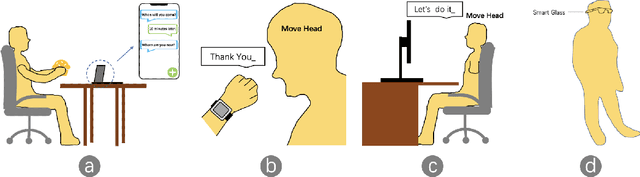
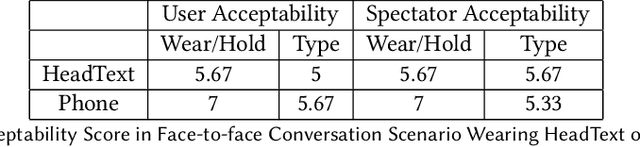
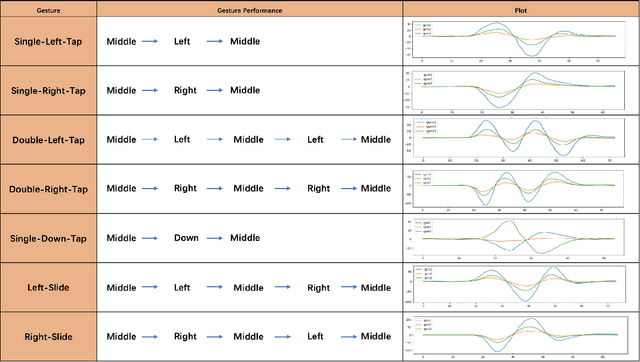
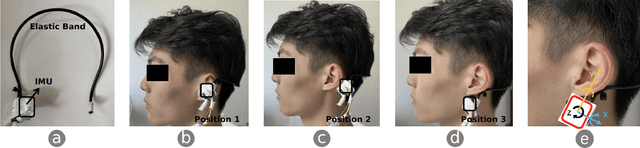
We present HeadText, a hands-free technique on a smart earpiece for text entry by motion sensing. Users input text utilizing only 7 head gestures for key selection, word selection, word commitment and word cancelling tasks. Head gesture recognition is supported by motion sensing on a smart earpiece to capture head moving signals and machine learning algorithms (K-Nearest-Neighbor (KNN) with a Dynamic Time Warping (DTW) distance measurement). A 10-participant user study proved that HeadText could recognize 7 head gestures at an accuracy of 94.29%. After that, the second user study presented that HeadText could achieve a maximum accuracy of 10.65 WPM and an average accuracy of 9.84 WPM for text entry. Finally, we demonstrate potential applications of HeadText in hands-free scenarios for (a). text entry of people with motor impairments, (b). private text entry, and (c). socially acceptable text entry.