 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
ISACL: Internal State Analyzer for Copyrighted Training Data Leakage
Aug 25, 2025
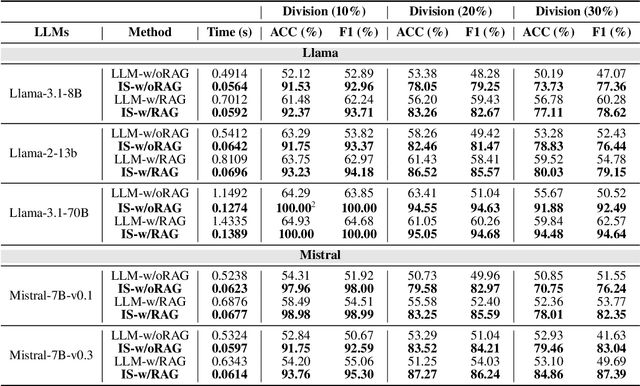
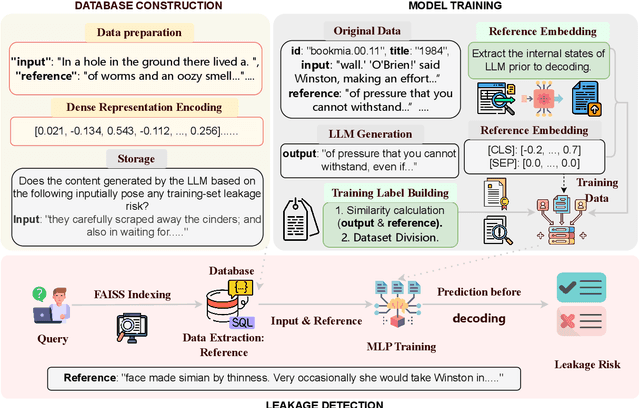
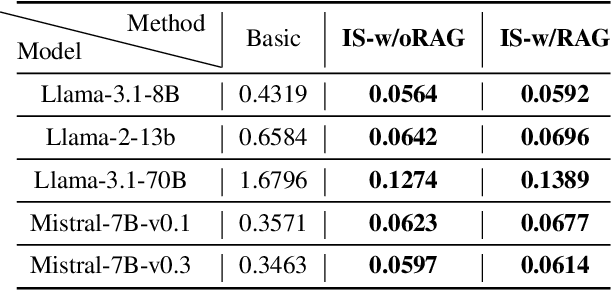
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but pose risks of inadvertently exposing copyrighted or proprietary data, especially when such data is used for training but not intended for distribution. Traditional methods address these leaks only after content is generated, which can lead to the exposure of sensitive information. This study introduces a proactive approach: examining LLMs' internal states before text generation to detect potential leaks. By using a curated dataset of copyrighted materials, we trained a neural network classifier to identify risks, allowing for early intervention by stopping the generation process or altering outputs to prevent disclosure. Integrated with a Retrieval-Augmented Generation (RAG) system, this framework ensures adherence to copyright and licensing requirements while enhancing data privacy and ethical standards. Our results show that analyzing internal states effectively mitigates the risk of copyrighted data leakage, offering a scalable solution that fits smoothly into AI workflows, ensuring compliance with copyright regulations while maintaining high-quality text generation. The implementation is available on GitHub.\footnote{https://github.com/changhu73/Internal_states_leakage}
Knowledge Protocol Engineering: A New Paradigm for AI in Domain-Specific Knowledge Work
Jul 03, 2025The capabilities of Large Language Models (LLMs) have opened new frontiers for interacting with complex, domain-specific knowledge. However, prevailing methods like Retrieval-Augmented Generation (RAG) and general-purpose Agentic AI, while powerful, often struggle with tasks that demand deep, procedural, and methodological reasoning inherent to expert domains. RAG provides factual context but fails to convey logical frameworks; autonomous agents can be inefficient and unpredictable without domain-specific heuristics. To bridge this gap, we introduce Knowledge Protocol Engineering (KPE), a new paradigm focused on systematically translating human expert knowledge, often expressed in natural language documents, into a machine-executable Knowledge Protocol (KP). KPE shifts the focus from merely augmenting LLMs with fragmented information to endowing them with a domain's intrinsic logic, operational strategies, and methodological principles. We argue that a well-engineered Knowledge Protocol allows a generalist LLM to function as a specialist, capable of decomposing abstract queries and executing complex, multi-step tasks. This position paper defines the core principles of KPE, differentiates it from related concepts, and illustrates its potential applicability across diverse fields such as law and bioinformatics, positing it as a foundational methodology for the future of human-AI collaboration.
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning
Aug 02, 2024The key challenge of cross-modal domain-incremental learning (DIL) is to enable the learning model to continuously learn from novel data with different feature distributions under the same task without forgetting old ones. However, existing top-performing methods still cause high forgetting rates, by lacking intra-domain knowledge extraction and inter-domain common prompting strategy. In this paper, we propose a simple yet effective framework, CP-Prompt, by training limited parameters to instruct a pre-trained model to learn new domains and avoid forgetting existing feature distributions. CP-Prompt captures intra-domain knowledge by compositionally inserting personalized prompts on multi-head self-attention layers and then learns the inter-domain knowledge with a common prompting strategy. CP-Prompt shows superiority compared with state-of-the-art baselines among three widely evaluated DIL tasks. The source code is available at https://github.com/dannis97500/CP_Prompt.
HeadText: Exploring Hands-free Text Entry using Head Gestures by Motion Sensing on a Smart Earpiece
May 23, 2022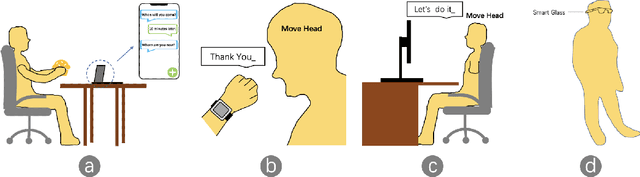
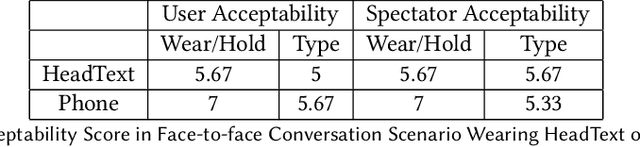
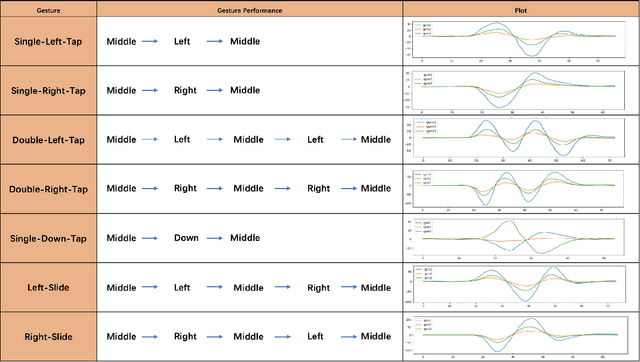
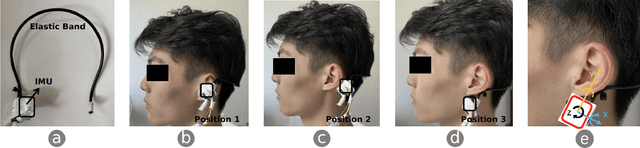
We present HeadText, a hands-free technique on a smart earpiece for text entry by motion sensing. Users input text utilizing only 7 head gestures for key selection, word selection, word commitment and word cancelling tasks. Head gesture recognition is supported by motion sensing on a smart earpiece to capture head moving signals and machine learning algorithms (K-Nearest-Neighbor (KNN) with a Dynamic Time Warping (DTW) distance measurement). A 10-participant user study proved that HeadText could recognize 7 head gestures at an accuracy of 94.29%. After that, the second user study presented that HeadText could achieve a maximum accuracy of 10.65 WPM and an average accuracy of 9.84 WPM for text entry. Finally, we demonstrate potential applications of HeadText in hands-free scenarios for (a). text entry of people with motor impairments, (b). private text entry, and (c). socially acceptable text entry.