 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction of a Syntactic Analysis Map for Yi Shui School through Text Mining and Natural Language Processing Research
Paper and Code
Feb 16, 2024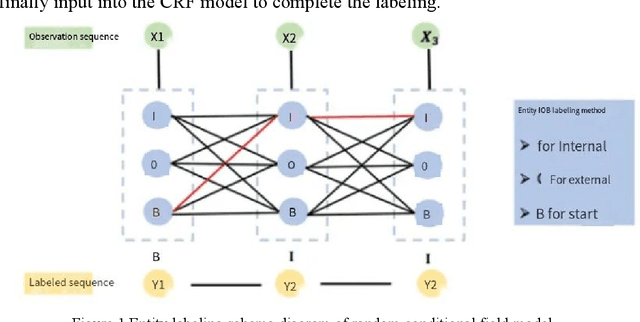
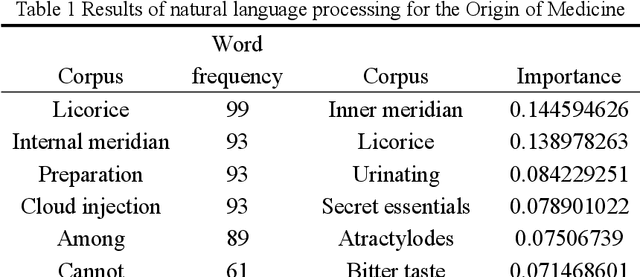
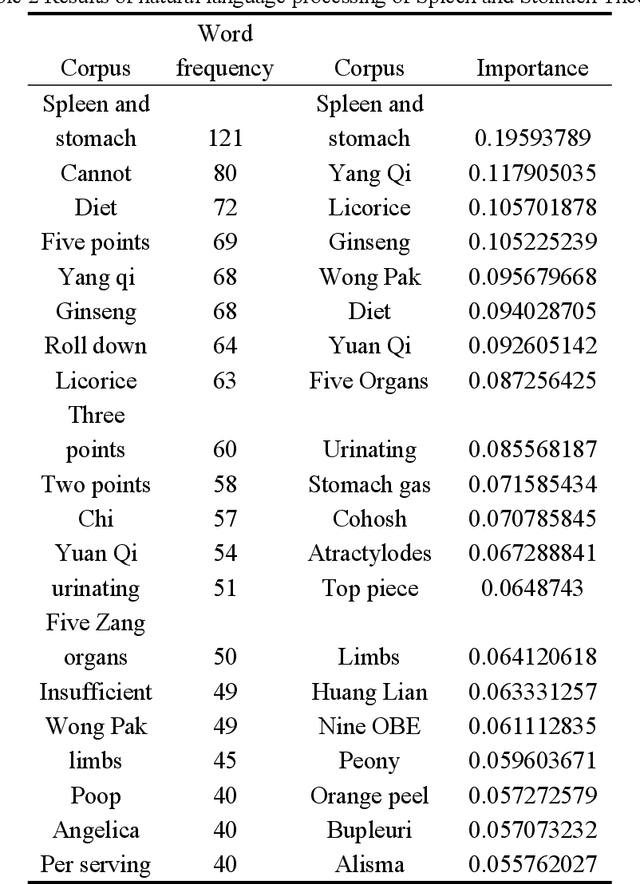

Entity and relationship extraction is a crucial component in natural language processing tasks such as knowledge graph construction, question answering system design, and semantic analysis. Most of the information of the Yishui school of traditional Chinese Medicine (TCM) is stored in the form of unstructured classical Chinese text. The key information extraction of TCM texts plays an important role in mining and studying the academic schools of TCM. In order to solve these problems efficiently using artificial intelligence methods, this study constructs a word segmentation and entity relationship extraction model based on conditional random fields under the framework of natural language processing technology to identify and extract the entity relationship of traditional Chinese medicine texts, and uses the common weighting technology of TF-IDF information retrieval and data mining to extract important key entity information in different ancient books. The dependency syntactic parser based on neural network is used to analyze the grammatical relationship between entities in each ancient book article, and it is represented as a tree structure visualization, which lays the foundation for the next construction of the knowledge graph of Yishui school and the use of artificial intelligence methods to carry out the research of TCM academic schools.