 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGTM: Substructure-based Neural Graph Topic Model for Interpretable Graph Generation
Jul 17, 2025Graph generation plays a pivotal role across numerous domains, including molecular design and knowledge graph construction. Although existing methods achieve considerable success in generating realistic graphs, their interpretability remains limited, often obscuring the rationale behind structural decisions. To address this challenge, we propose the Neural Graph Topic Model (NGTM), a novel generative framework inspired by topic modeling in natural language processing. NGTM represents graphs as mixtures of latent topics, each defining a distribution over semantically meaningful substructures, which facilitates explicit interpretability at both local and global scales. The generation process transparently integrates these topic distributions with a global structural variable, enabling clear semantic tracing of each generated graph. Experiments demonstrate that NGTM achieves competitive generation quality while uniquely enabling fine-grained control and interpretability, allowing users to tune structural features or induce biological properties through topic-level adjustments.
MolEditRL: Structure-Preserving Molecular Editing via Discrete Diffusion and Reinforcement Learning
May 26, 2025Molecular editing aims to modify a given molecule to optimize desired chemical properties while preserving structural similarity. However, current approaches typically rely on string-based or continuous representations, which fail to adequately capture the discrete, graph-structured nature of molecules, resulting in limited structural fidelity and poor controllability. In this paper, we propose MolEditRL, a molecular editing framework that explicitly integrates structural constraints with precise property optimization. Specifically, MolEditRL consists of two stages: (1) a discrete graph diffusion model pretrained to reconstruct target molecules conditioned on source structures and natural language instructions; (2) an editing-aware reinforcement learning fine-tuning stage that further enhances property alignment and structural preservation by explicitly optimizing editing decisions under graph constraints. For comprehensive evaluation, we construct MolEdit-Instruct, the largest and most property-rich molecular editing dataset, comprising 3 million diverse examples spanning single- and multi-property tasks across 10 chemical attributes. Experimental results demonstrate that MolEditRL significantly outperforms state-of-the-art methods in both property optimization accuracy and structural fidelity, achieving a 74\% improvement in editing success rate while using 98\% fewer parameters.
A Comprehensive Survey on Self-Interpretable Neural Networks
Jan 26, 2025Neural networks have achieved remarkable success across various fields. However, the lack of interpretability limits their practical use, particularly in critical decision-making scenarios. Post-hoc interpretability, which provides explanations for pre-trained models, is often at risk of robustness and fidelity. This has inspired a rising interest in self-interpretable neural networks, which inherently reveal the prediction rationale through the model structures. Although there exist surveys on post-hoc interpretability, a comprehensive and systematic survey of self-interpretable neural networks is still missing. To address this gap, we first collect and review existing works on self-interpretable neural networks and provide a structured summary of their methodologies from five key perspectives: attribution-based, function-based, concept-based, prototype-based, and rule-based self-interpretation. We also present concrete, visualized examples of model explanations and discuss their applicability across diverse scenarios, including image, text, graph data, and deep reinforcement learning. Additionally, we summarize existing evaluation metrics for self-interpretability and identify open challenges in this field, offering insights for future research. To support ongoing developments, we present a publicly accessible resource to track advancements in this domain: https://github.com/yangji721/Awesome-Self-Interpretable-Neural-Network.
Data-Free Adversarial Knowledge Distillation for Graph Neural Networks
May 08, 2022


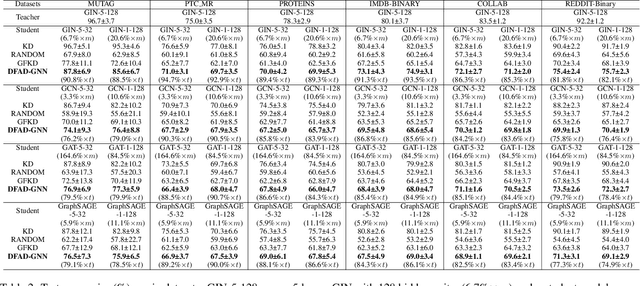
Graph neural networks (GNNs) have been widely used in modeling graph structured data, owing to its impressive performance in a wide range of practical applications. Recently, knowledge distillation (KD) for GNNs has enabled remarkable progress in graph model compression and knowledge transfer. However, most of the existing KD methods require a large volume of real data, which are not readily available in practice, and may preclude their applicability in scenarios where the teacher model is trained on rare or hard to acquire datasets. To address this problem, we propose the first end-to-end framework for data-free adversarial knowledge distillation on graph structured data (DFAD-GNN). To be specific, our DFAD-GNN employs a generative adversarial network, which mainly consists of three components: a pre-trained teacher model and a student model are regarded as two discriminators, and a generator is utilized for deriving training graphs to distill knowledge from the teacher model into the student model. Extensive experiments on various benchmark models and six representative datasets demonstrate that our DFAD-GNN significantly surpasses state-of-the-art data-free baselines in the graph classification task.