 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Through Complexity: What Makes Good Supervision for Hard Reasoning Tasks?
Oct 27, 2024

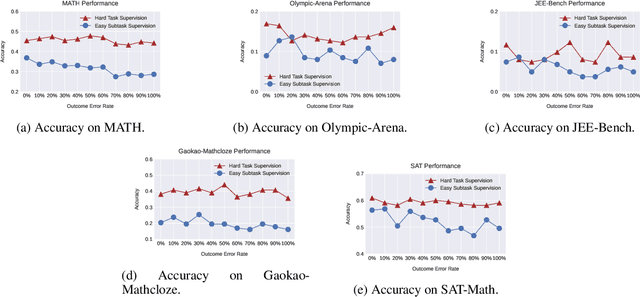
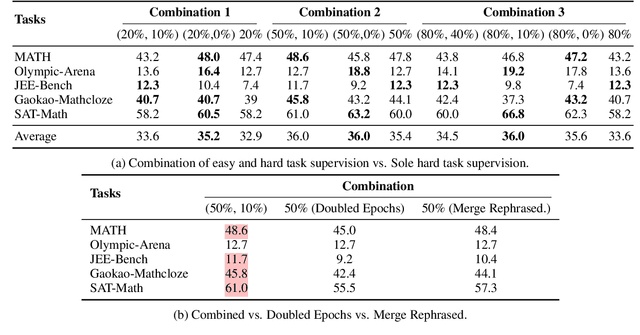
How can "weak teacher models" such as average human annotators or existing AI systems, effectively supervise LLMs to improve performance on hard reasoning tasks, especially those that challenge and requires expertise or daily practice from the teacher models? In this paper, we seek for empirical answers to this question by investigating various data-driven strategies that offer supervision data at different quality levels upon tasks of varying complexity. Two intuitive strategies emerge for teacher models to provide supervision during alignment training: 1) using lower-quality supervision from complete tasks that match the difficulty of the target reasoning tasks, and 2) leveraging higher-quality supervision from easier subtasks that are less challenging. Interestingly, we find that even when the outcome error rate for hard task supervision is high (e.g., 90\%), training on such data can outperform perfectly correct supervision on easier subtasks on multiple hard math benchmarks. We further identify a more critical factor influencing training performance: step-wise error rates, which indicate the severity of errors in solutions. Specifically, training on hard task supervision with the same outcome error rates but disparate step-wise error rates can lead to a 30\% accuracy gap on MATH benchmark. Our results also reveal that supplementing hard task supervision with the corresponding subtask supervision can yield notable performance improvements than simply combining rephrased hard full task supervision, suggesting new avenues for data augmentation. Data and code are released at \url{https://github.com/hexuan21/Weak-to-Strong}.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022
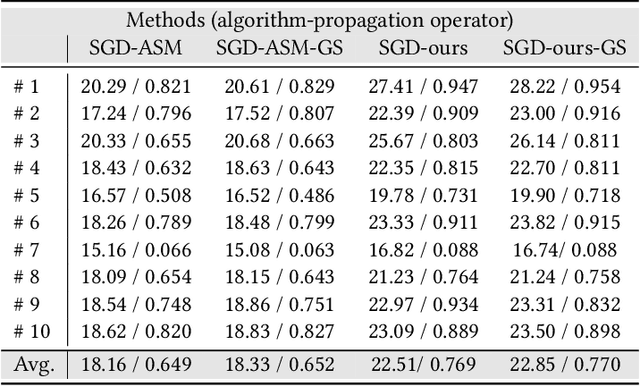

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data
Feb 17, 2020

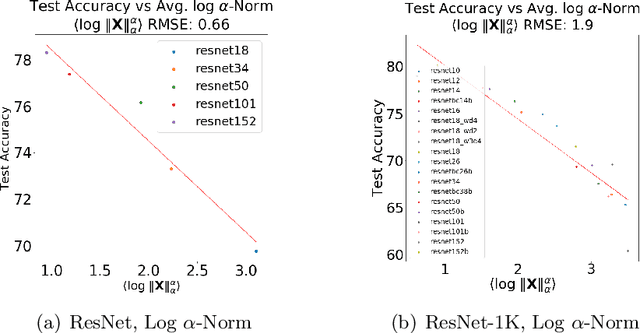
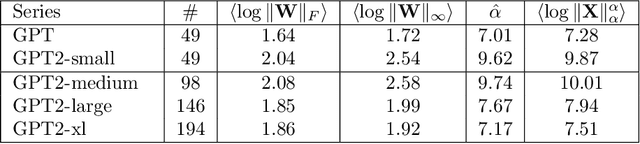
In many applications, one works with deep neural network (DNN) models trained by someone else. For such pretrained models, one typically does not have access to training/test data. Moreover, one does not know many details about the model, such as the specifics of the training data, the loss function, the hyperparameter values, etc. Given one or many pretrained models, can one say anything about the expected performance or quality of the models? Here, we present and evaluate empirical quality metrics for pretrained DNN models at scale. Using the open-source WeightWatcher tool, we analyze hundreds of publicly-available pretrained models, including older and current state-of-the-art models in CV and NLP. We examine norm-based capacity control metrics as well as newer Power Law (PL) based metrics (including fitted PL exponents and a Weighted Alpha metric), from the recently-developed Theory of Heavy-Tailed Self Regularization. Norm-based metrics correlate well with reported test accuracies for well-trained models across nearly all CV architecture series. On the other hand, norm-based metrics can not distinguish "good-versus-bad" models---which, arguably is the point of needing quality metrics. Indeed, they may give spurious results. PL-based metrics do much better---quantitatively better at discriminating series of "good-better-best" models, and qualitatively better at discriminating "good-versus-bad" models. PL-based metrics can also be used to characterize fine-scale properties of models, and we introduce the layer-wise Correlation Flow as new quality assessment. We show how poorly-trained (and/or poorly fine-tuned) models may exhibit both Scale Collapse and unusually large PL exponents, in particular for recent NLP models. Our techniques can be used to identify when a pretrained DNN has problems that can not be detected simply by examining training/test accuracies.