 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Localisation of Spatial-Temporal Graph Neural Network
Jan 08, 2025



Spatial-temporal data, fundamental to many intelligent applications, reveals dependencies indicating causal links between present measurements at specific locations and historical data at the same or other locations. Within this context, adaptive spatial-temporal graph neural networks (ASTGNNs) have emerged as valuable tools for modelling these dependencies, especially through a data-driven approach rather than pre-defined spatial graphs. While this approach offers higher accuracy, it presents increased computational demands. Addressing this challenge, this paper delves into the concept of localisation within ASTGNNs, introducing an innovative perspective that spatial dependencies should be dynamically evolving over time. We introduce \textit{DynAGS}, a localised ASTGNN framework aimed at maximising efficiency and accuracy in distributed deployment. This framework integrates dynamic localisation, time-evolving spatial graphs, and personalised localisation, all orchestrated around the Dynamic Graph Generator, a light-weighted central module leveraging cross attention. The central module can integrate historical information in a node-independent manner to enhance the feature representation of nodes at the current moment. This improved feature representation is then used to generate a dynamic sparse graph without the need for costly data exchanges, and it supports personalised localisation. Performance assessments across two core ASTGNN architectures and nine real-world datasets from various applications reveal that \textit{DynAGS} outshines current benchmarks, underscoring that the dynamic modelling of spatial dependencies can drastically improve model expressibility, flexibility, and system efficiency, especially in distributed settings.
Pre-Training Identification of Graph Winning Tickets in Adaptive Spatial-Temporal Graph Neural Networks
Jun 12, 2024In this paper, we present a novel method to significantly enhance the computational efficiency of Adaptive Spatial-Temporal Graph Neural Networks (ASTGNNs) by introducing the concept of the Graph Winning Ticket (GWT), derived from the Lottery Ticket Hypothesis (LTH). By adopting a pre-determined star topology as a GWT prior to training, we balance edge reduction with efficient information propagation, reducing computational demands while maintaining high model performance. Both the time and memory computational complexity of generating adaptive spatial-temporal graphs is significantly reduced from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$. Our approach streamlines the ASTGNN deployment by eliminating the need for exhaustive training, pruning, and retraining cycles, and demonstrates empirically across various datasets that it is possible to achieve comparable performance to full models with substantially lower computational costs. Specifically, our approach enables training ASTGNNs on the largest scale spatial-temporal dataset using a single A6000 equipped with 48 GB of memory, overcoming the out-of-memory issue encountered during original training and even achieving state-of-the-art performance. {Furthermore, we delve into the effectiveness of the GWT from the perspective of spectral graph theory, providing substantial theoretical support.} This advancement not only proves the existence of efficient sub-networks within ASTGNNs but also broadens the applicability of the LTH in resource-constrained settings, marking a significant step forward in the field of graph neural networks. Code is available at https://anonymous.4open.science/r/paper-1430.
Minimalist Traffic Prediction: Linear Layer Is All You Need
Aug 23, 2023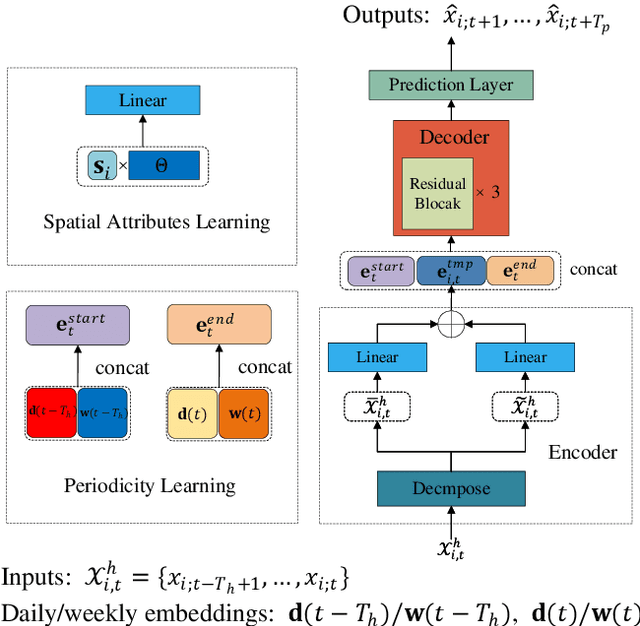
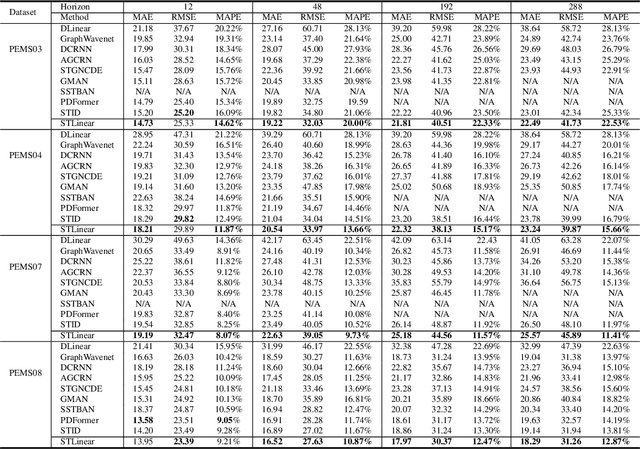
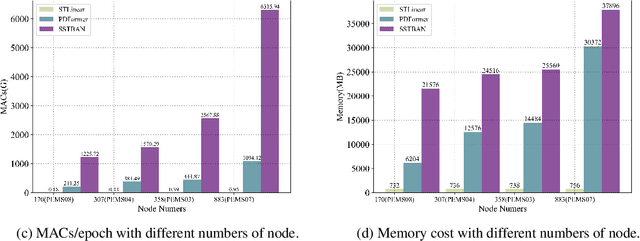
Traffic prediction is essential for the progression of Intelligent Transportation Systems (ITS) and the vision of smart cities. While Spatial-Temporal Graph Neural Networks (STGNNs) have shown promise in this domain by leveraging Graph Neural Networks (GNNs) integrated with either RNNs or Transformers, they present challenges such as computational complexity, gradient issues, and resource-intensiveness. This paper addresses these challenges, advocating for three main solutions: a node-embedding approach, time series decomposition, and periodicity learning. We introduce STLinear, a minimalist model architecture designed for optimized efficiency and performance. Unlike traditional STGNNs, STlinear operates fully locally, avoiding inter-node data exchanges, and relies exclusively on linear layers, drastically cutting computational demands. Our empirical studies on real-world datasets confirm STLinear's prowess, matching or exceeding the accuracy of leading STGNNs, but with significantly reduced complexity and computation overhead (more than 95% reduction in MACs per epoch compared to state-of-the-art STGNN baseline published in 2023). In summary, STLinear emerges as a potent, efficient alternative to conventional STGNNs, with profound implications for the future of ITS and smart city initiatives.
Localised Adaptive Spatial-Temporal Graph Neural Network
Jun 15, 2023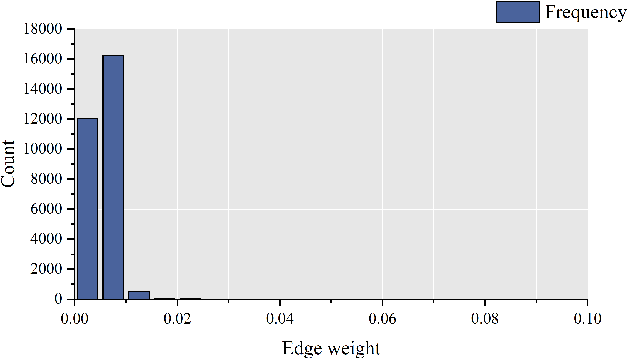
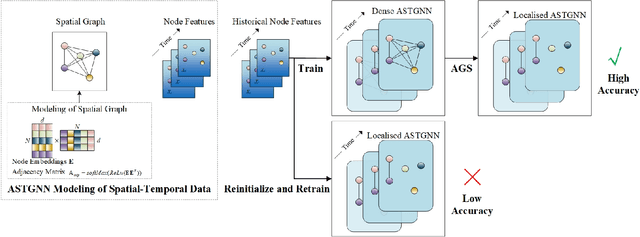

Spatial-temporal graph models are prevailing for abstracting and modelling spatial and temporal dependencies. In this work, we ask the following question: whether and to what extent can we localise spatial-temporal graph models? We limit our scope to adaptive spatial-temporal graph neural networks (ASTGNNs), the state-of-the-art model architecture. Our approach to localisation involves sparsifying the spatial graph adjacency matrices. To this end, we propose Adaptive Graph Sparsification (AGS), a graph sparsification algorithm which successfully enables the localisation of ASTGNNs to an extreme extent (fully localisation). We apply AGS to two distinct ASTGNN architectures and nine spatial-temporal datasets. Intriguingly, we observe that spatial graphs in ASTGNNs can be sparsified by over 99.5\% without any decline in test accuracy. Furthermore, even when ASTGNNs are fully localised, becoming graph-less and purely temporal, we record no drop in accuracy for the majority of tested datasets, with only minor accuracy deterioration observed in the remaining datasets. However, when the partially or fully localised ASTGNNs are reinitialised and retrained on the same data, there is a considerable and consistent drop in accuracy. Based on these observations, we reckon that \textit{(i)} in the tested data, the information provided by the spatial dependencies is primarily included in the information provided by the temporal dependencies and, thus, can be essentially ignored for inference; and \textit{(ii)} although the spatial dependencies provide redundant information, it is vital for the effective training of ASTGNNs and thus cannot be ignored during training. Furthermore, the localisation of ASTGNNs holds the potential to reduce the heavy computation overhead required on large-scale spatial-temporal data and further enable the distributed deployment of ASTGNNs.
Hyper Attention Recurrent Neural Network: Tackling Temporal Covariate Shift in Time Series Analysis
Feb 22, 2022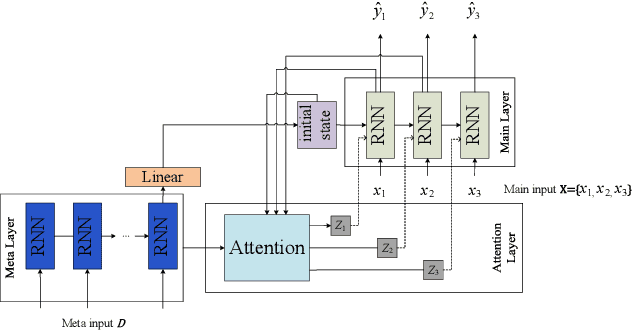
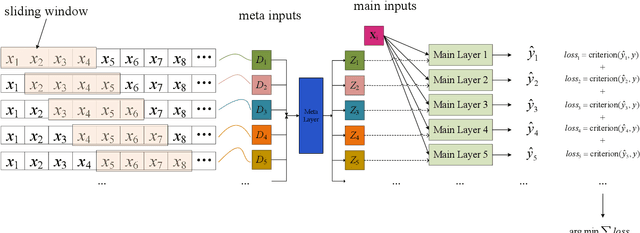
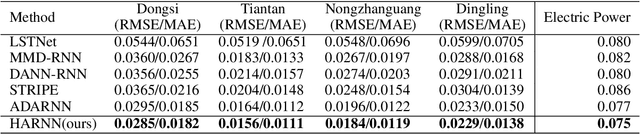
Analyzing long time series with RNNs often suffers from infeasible training. Segmentation is therefore commonly used in data pre-processing. However, in non-stationary time series, there exists often distribution shift among different segments. RNN is easily swamped in the dilemma of fitting bias in these segments due to the lack of global information, leading to poor generalization, known as Temporal Covariate Shift (TCS) problem, which is only addressed by a recently proposed RNN-based model. One of the assumptions in TCS is that the distribution of all divided intervals under the same segment are identical. This assumption, however, may not be true on high-frequency time series, such as traffic flow, that also have large stochasticity. Besides, macro information across long periods isn't adequately considered in the latest RNN-based methods. To address the above issues, we propose Hyper Attention Recurrent Neural Network (HARNN) for the modeling of temporal patterns containing both micro and macro information. An HARNN consists of a meta layer for parameter generation and an attention-enabled main layer for inference. High-frequency segments are transformed into low-frequency segments and fed into the meta layers, while the first main layer consumes the same high-frequency segments as conventional methods. In this way, each low-frequency segment in the meta inputs generates a unique main layer, enabling the integration of both macro information and micro information for inference. This forces all main layers to predict the same target which fully harnesses the common knowledge in varied distributions when capturing temporal patterns. Evaluations on multiple benchmarks demonstrated that our model outperforms a couple of RNN-based methods on a federation of key metrics.