 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge94% on CIFAR-10 in 3.29 Seconds on a Single GPU
Apr 05, 2024CIFAR-10 is among the most widely used datasets in machine learning, facilitating thousands of research projects per year. To accelerate research and reduce the cost of experiments, we introduce training methods for CIFAR-10 which reach 94% accuracy in 3.29 seconds, 95% in 10.4 seconds, and 96% in 46.3 seconds, when run on a single NVIDIA A100 GPU. As one factor contributing to these training speeds, we propose a derandomized variant of horizontal flipping augmentation, which we show improves over the standard method in every case where flipping is beneficial over no flipping at all. Our code is released at https://github.com/KellerJordan/cifar10-airbench.
Calibrated Chaos: Variance Between Runs of Neural Network Training is Harmless and Inevitable
Apr 04, 2023



Typical neural network trainings have substantial variance in test-set performance between repeated runs, impeding hyperparameter comparison and training reproducibility. We present the following results towards understanding this variation. (1) Despite having significant variance on their test-sets, we demonstrate that standard CIFAR-10 and ImageNet trainings have very little variance in their performance on the test-distributions from which those test-sets are sampled, suggesting that variance is less of a practical issue than previously thought. (2) We present a simplifying statistical assumption which closely approximates the structure of the test-set accuracy distribution. (3) We argue that test-set variance is inevitable in the following two senses. First, we show that variance is largely caused by high sensitivity of the training process to initial conditions, rather than by specific sources of randomness like the data order and augmentations. Second, we prove that variance is unavoidable given the observation that ensembles of trained networks are well-calibrated. (4) We conduct preliminary studies of distribution-shift, fine-tuning, data augmentation and learning rate through the lens of variance between runs.
REPAIR: REnormalizing Permuted Activations for Interpolation Repair
Nov 15, 2022


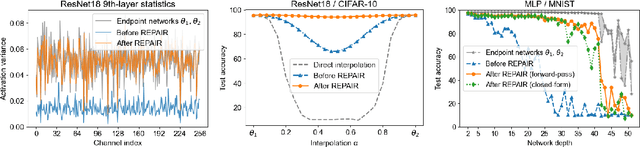
In this paper we look into the conjecture of Entezari et al.(2021) which states that if the permutation invariance of neural networks is taken into account, then there is likely no loss barrier to the linear interpolation between SGD solutions. First, we observe that neuron alignment methods alone are insufficient to establish low-barrier linear connectivity between SGD solutions due to a phenomenon we call variance collapse: interpolated deep networks suffer a collapse in the variance of their activations, causing poor performance. Next, we propose REPAIR (REnormalizing Permuted Activations for Interpolation Repair) which mitigates variance collapse by rescaling the preactivations of such interpolated networks. We explore the interaction between our method and the choice of normalization layer, network width, and depth, and demonstrate that using REPAIR on top of neuron alignment methods leads to 60%-100% relative barrier reduction across a wide variety of architecture families and tasks. In particular, we report a 74% barrier reduction for ResNet50 on ImageNet and 90% barrier reduction for ResNet18 on CIFAR10.