 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the impact of magnitude pruning on contrastive learning methods
Paper and Code
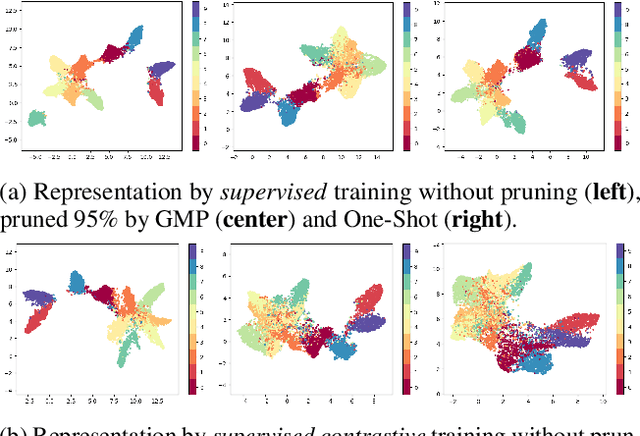
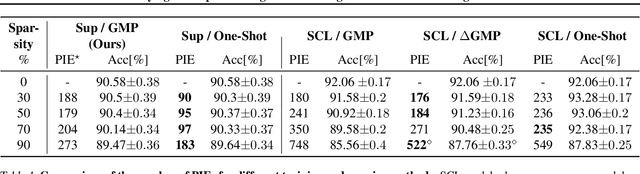

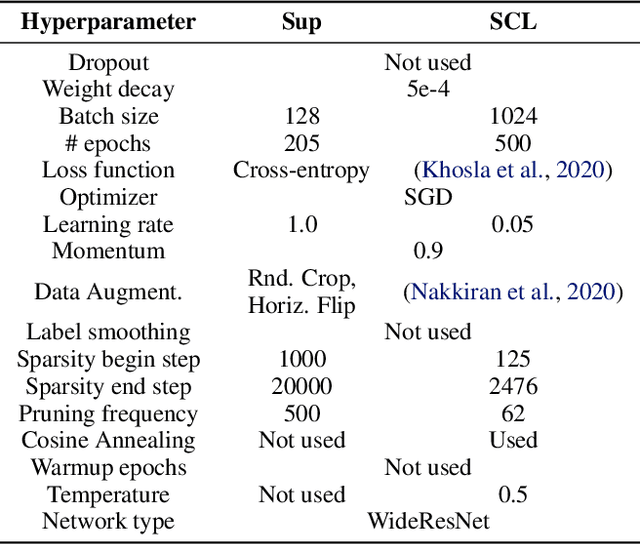
We study the impact of different pruning techniques on the representation learned by deep neural networks trained with contrastive loss functions. Our work finds that at high sparsity levels, contrastive learning results in a higher number of misclassified examples relative to models trained with traditional cross-entropy loss. To understand this pronounced difference, we use metrics such as the number of PIEs (Hooker et al., 2019), Q-Score (Kalibhat et al., 2022), and PD-Score (Baldock et al., 2021) to measure the impact of pruning on the learned representation quality. Our analysis suggests the schedule of the pruning method implementation matters. We find that the negative impact of sparsity on the quality of the learned representation is the highest when pruning is introduced early on in the training phase.