 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREDS: Resource-Efficient Deep Subnetworks for Dynamic Resource Constraints
Nov 22, 2023Deep models deployed on edge devices frequently encounter resource variability, which arises from fluctuating energy levels, timing constraints, or prioritization of other critical tasks within the system. State-of-the-art machine learning pipelines generate resource-agnostic models, not capable to adapt at runtime. In this work we introduce Resource-Efficient Deep Subnetworks (REDS) to tackle model adaptation to variable resources. In contrast to the state-of-the-art, REDS use structured sparsity constructively by exploiting permutation invariance of neurons, which allows for hardware-specific optimizations. Specifically, REDS achieve computational efficiency by (1) skipping sequential computational blocks identified by a novel iterative knapsack optimizer, and (2) leveraging simple math to re-arrange the order of operations in REDS computational graph to take advantage of the data cache. REDS support conventional deep networks frequently deployed on the edge and provide computational benefits even for small and simple networks. We evaluate REDS on six benchmark architectures trained on the Google Speech Commands, FMNIST and CIFAR10 datasets, and test on four off-the-shelf mobile and embedded hardware platforms. We provide a theoretical result and empirical evidence for REDS outstanding performance in terms of submodels' test set accuracy, and demonstrate an adaptation time in response to dynamic resource constraints of under 40$\mu$s, utilizing a 2-layer fully-connected network on Arduino Nano 33 BLE Sense.
Studying the impact of magnitude pruning on contrastive learning methods
Jul 01, 2022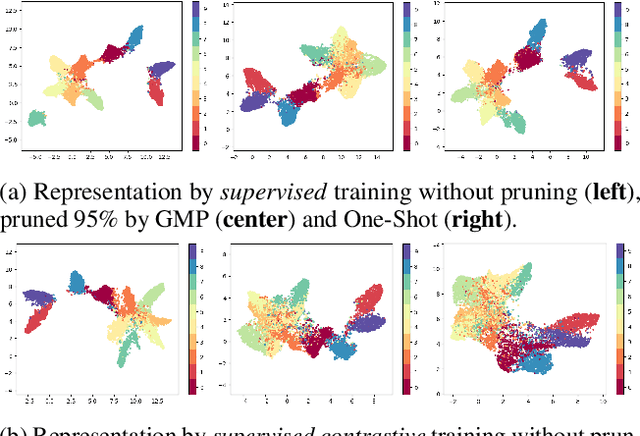
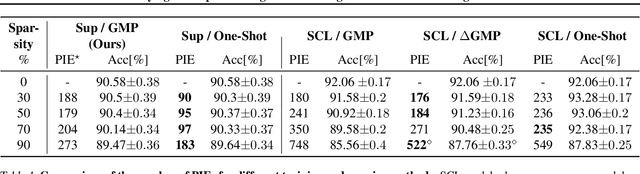

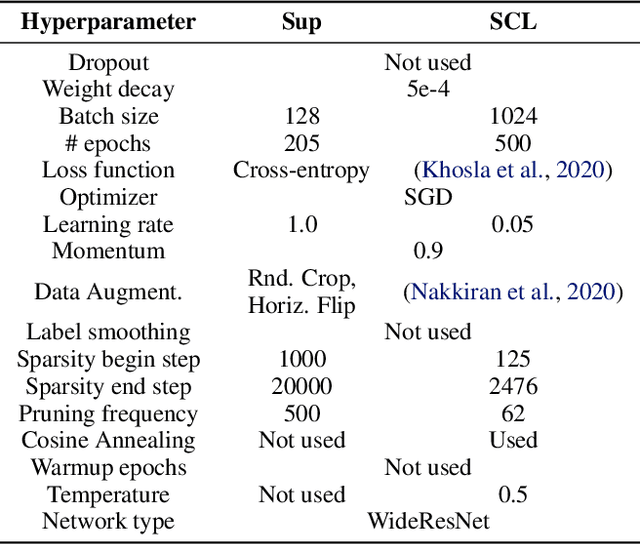
We study the impact of different pruning techniques on the representation learned by deep neural networks trained with contrastive loss functions. Our work finds that at high sparsity levels, contrastive learning results in a higher number of misclassified examples relative to models trained with traditional cross-entropy loss. To understand this pronounced difference, we use metrics such as the number of PIEs (Hooker et al., 2019), Q-Score (Kalibhat et al., 2022), and PD-Score (Baldock et al., 2021) to measure the impact of pruning on the learned representation quality. Our analysis suggests the schedule of the pruning method implementation matters. We find that the negative impact of sparsity on the quality of the learned representation is the highest when pruning is introduced early on in the training phase.